
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- cross-entropy loss
- 내장함수
- geometric viewpoint
- Graph Neural Networks
- GNN
- cs224w
- parametric approach
- 산술연산
- object detection
- format이 없는 입출력문
- computer vision
- L2 distance
- print*
- EECS 498-007/598-005
- FORTRAN
- Semantic Gap
- data-driven approach
- L1 distance
- tensor core
- image classification
- multiclass SVM loss
- cv
- visual viewpoint
- implicit rule
- algebraic viewpoint
- feature cropping
- gfortran
- human keypoints
- fortran90
- implicit rules
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 3강. Linear Classifier (1) 본문
[EECS 498-007/598-005] 3강. Linear Classifier (1)
ydduri 2023. 1. 21. 20:431. Linear Classifier
Linear Classifier란 말그대로 선형으로 어떠한 대상을 분류해주는 알고리즘이다.
이는 앞으로 공부할 신경망(neural network)를 구성하는 가장 기본적인 요소로, 레고 작품 전체를 신경망이라 하면 그것을 구성하는 블록 하나하나가 linear classifier라고 볼 수 있다.

1) Parametric Approach
보통 linear classifier에 대해 설명할 때 빠지지 않고 등장하는 키워드가 바로 'parametric approach'이다.
이는 모든 데이터를 저장하는 것이 아니라 파라미터 값만 저장하는 방식으로, 이를 적용한 모델의 가장 단순한 형태가 바로 오늘 공부할 linear classifier이다. 그 반대는 모든 데이터를 저장하는 방식의 non parametric approach로, 그 예시로 kNN을 들 수 있다.

본격적인 설명에 들어가기에 앞서 설명에 사용할 데이터셋인 CIFAR-10을 소개하겠다. 이는 32*32 픽셀의 작은 정사각형 이미지가 red, blue, green 3개의 채널로 표현되어, 전체적으로 32*32*3 픽셀을 가지는 이미지 데이터셋이다.

linear classifier를 통한 우리의 목표는 바로 이것이다.
" 입력 이미지를 받았을 때 airplane, automobile, cat 등 10개의 클래스에서 알맞은 클래스로 분류할 수 있도록 해보자!"
이를 위해 10개의 클래스 각각에 해당하는 점수를 출력하도록 해서, 가장 높은 점수를 받은 클래스를 입력 이미지의 카테고리라고 분류할 것이다.

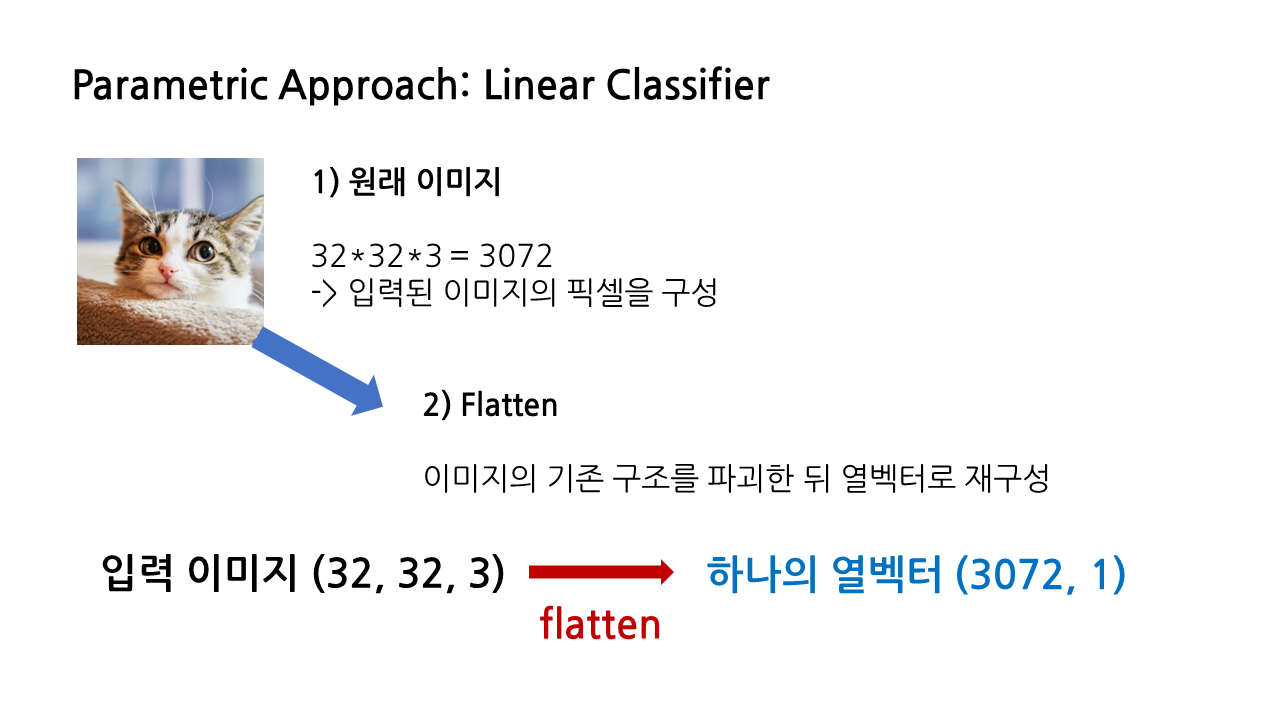
(1) 원래 이미지: 32*32*3 = 3072 -> 입력된 이미지의 픽셀을 구성
(2) flatten: 분류에 사용할 이미지 데이터셋인 CIFAR-10은 앞서 말한 것처럼 32*32*3 픽셀을 가지고 있는데, 우선은 이것을 (3072, 1)의 하나의 열벡터로 재구성한다. 이 과정을 'flatten'이라 한다.
(3) 함수 f(x, W) = Wx + b: 입력 이미지에 대한 flatten이 완료되면 이것을 이러한 형태의 함수에 넣어준다. 우리는 10개 클래스 각각에 해당하는 점수를 결과값으로 뽑고 싶은 것이므로 이미지가 입력됐을 때 10개 클래스에 대한 점수를 결과값으로 출력해야 할 것이다.
앞서 입력 이미지의 shape을 (3072, 1)로 조정했었는데, (10, 1)의 shape을 가지는 결과값이 출력되려면 함수에 들어가는 각각의 파라미터들은 어떤 shape을 가져야 할까?

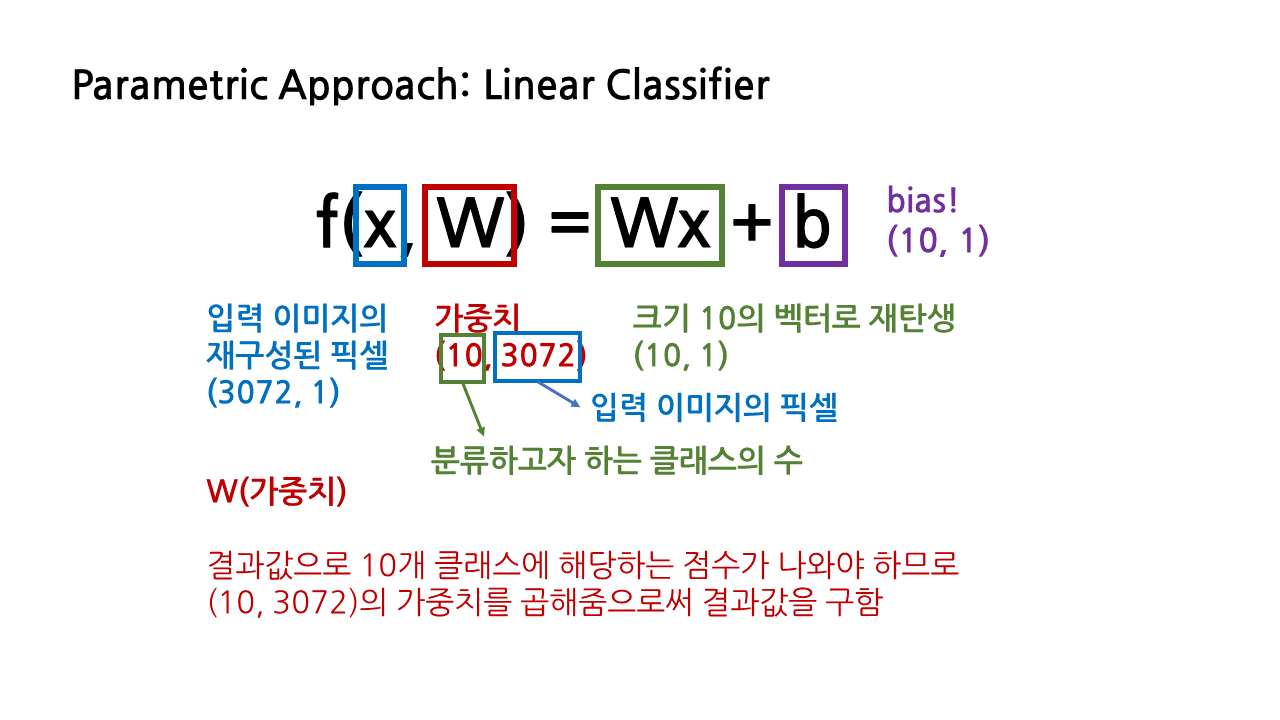
함수 f(x, W) = Wx + b 에서 x는 입력 이미지를 재구성한 픽셀을 의미하며, (3072, 1)의 shape을 가지고 있다. 결과값으로 10개 클래스에 해당하는 점수가 나와야 하므로 결과값은 (10, 1)의 형태를 가져야 한다.
- W(가중치): 그러기 위해서 우리는 함수에서 W로 표시된 가중치를 곱해줄 것이다. (10, 1)의 결과값을 만들기 위해 (10, 3072)의 가중치를 곱해주게 된다.
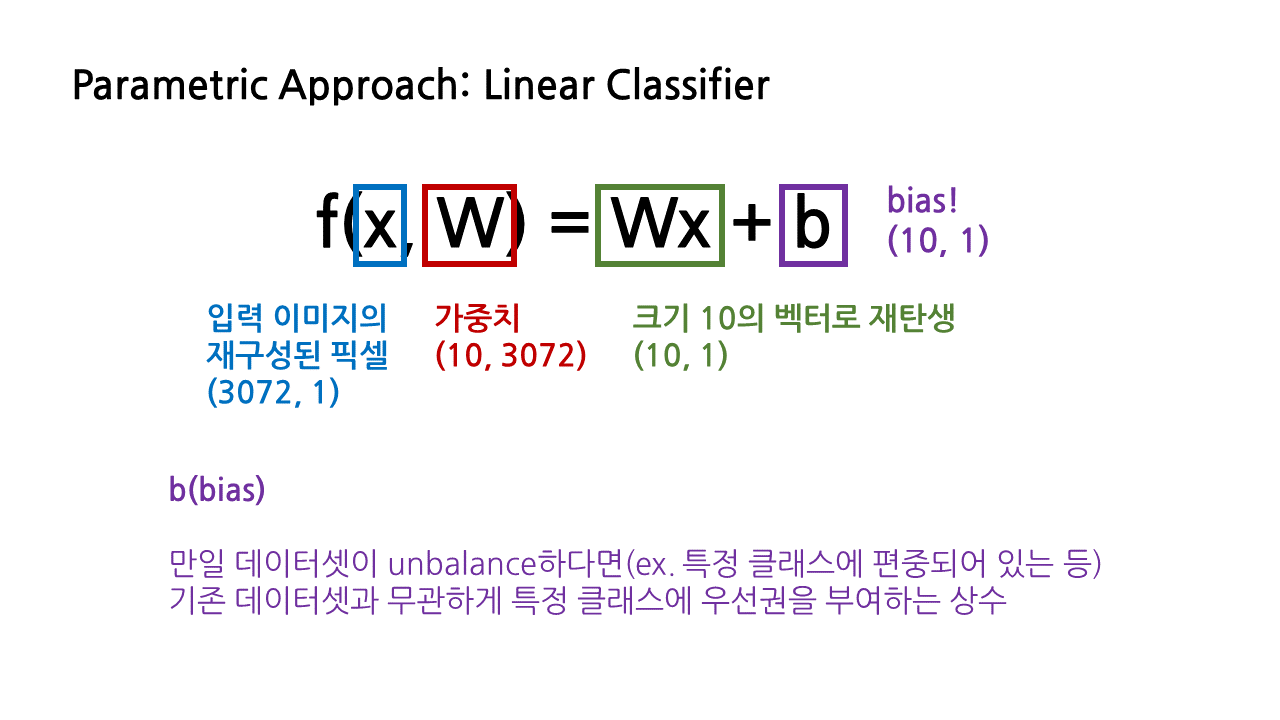
- b(bias): 만일 데이터셋이 unbalance하다면, 예를 들어 특정 클래스에 편중되어 있는 등의 상황에서, 기존 데이터셋과 무관하게 특정 클래스에 우선권을 부여할 수 있도록 더해지는 상수이다.
2) Algebraic Viewpoint
지금부터 다룰 것은 linear classifier를 바라보는 세 가지 관점 중 첫 번째인 'Algebraic Viewpoint', 즉 대수적 관점이다. 표현은 그럴싸하지만 사실상 선형대수 계산이라고 생각하면 된다.
이해를 쉽게 하기 위해 2*2의 입력 이미지를 3개의 class로 분류하는 상황을 가정했을 때, 대수적 관점에서는 linear classifier의 동작 과정을 아래와 같이 도식화할 수 있다.
- flatten: 2*2의 입력 이미지를 4*1의 열벡터로 바꿔준다.
- 분류하고자 하는 클래스의 개수가 3개, 열벡터의 크기가 4이므로 3*4의 가중치 행렬을 생성한다.
- 가중치 행렬과 입력 이미지의 열벡터 사이에서 백터 내적 연산을 수행하고, 마지막에 bias를 더해주면 각 클래스별로 아래 그림과 같은 점수를 계산해낼 수 있다.
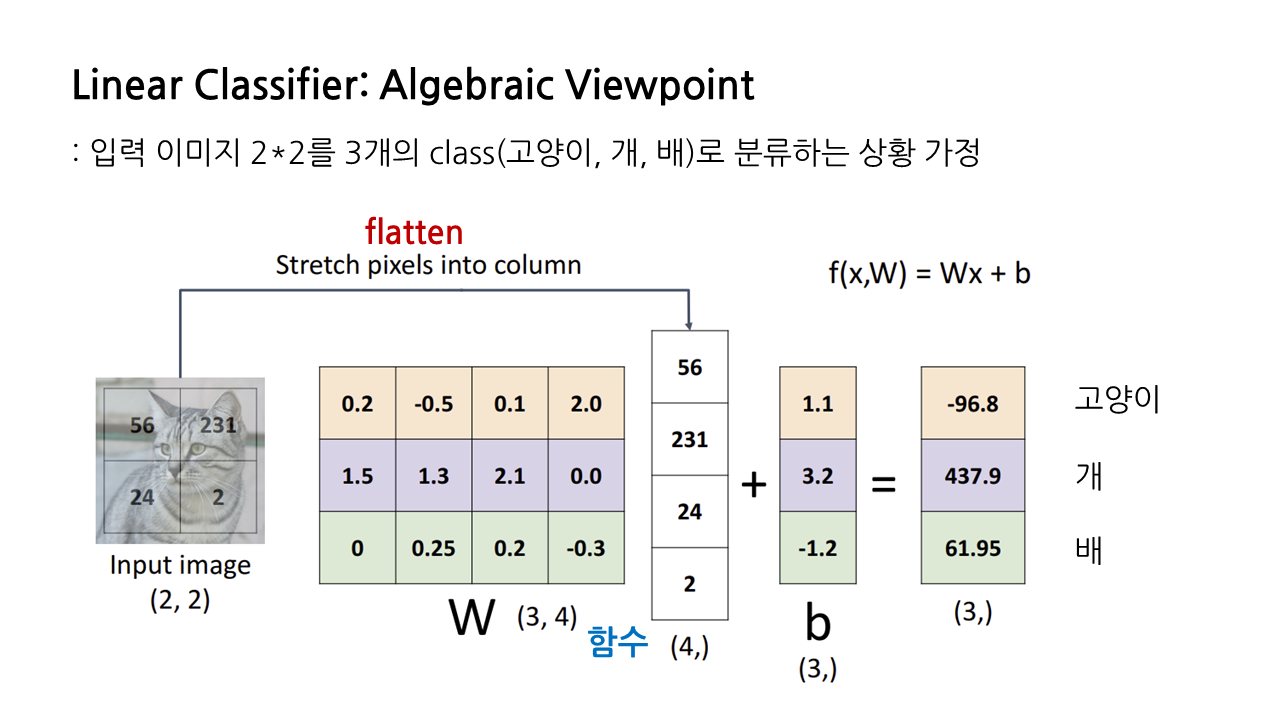
벡터 내적 연산은 아래 그림과 같이 수행된다. 가중치 행렬의 첫 번째 행에 있는 원소들을 입력 이미지 열벡터의 원소들과 차례로 곱해서 더해주고, 마지막에 bias까지 더해주면 첫 번째 클래스에 해당하는 점수인 -96.8을 얻어낼 수 있다.
이 예시에서는 입력 이미지가 437.9의 가장 높은 점수를 받은 두 번째 클래스로 분류될 것이다. 그런데 우리의 입력 이미지는 고양이인데, 이 classifier는 해당 이미지를 개로 분류했다. 이럴 경우 가중치가 잘못됐다는 의미라서 이걸 조정해야 하는데, 좋은 가중치 W를 설정하는 방법은 다음 글에서 Loss Function 설명하면서 다시 다루겠다.

Bias Trick이란 앞서와 똑같은 상황인데, 다만 bias를 따로 떨어진 상수항으로 취급하는 게 아니라 가중치 행렬에 포함시켜 계산하는 것을 말한다. 벡터 연산 방식도 앞서와 동일하다.


bias trick의 경우 상수항, 즉 bias항을 없앰으로써 구조를 비교적 단순하게 만들어 이해를 돕는다는 장점이 있지만, 컴퓨터 비전에서는 잘 사용하지 않는 편이다. 강연자께서 Linear classifier to convolutions 파트로 넘어갈 때 매끄럽지 않다는 점, 파라미터들을 초기화 혹은 정규화할 때 가중치와 bias를 따로 보는 것이 유리할 때가 있다는 점을 그 이유로 들어 주셨다.

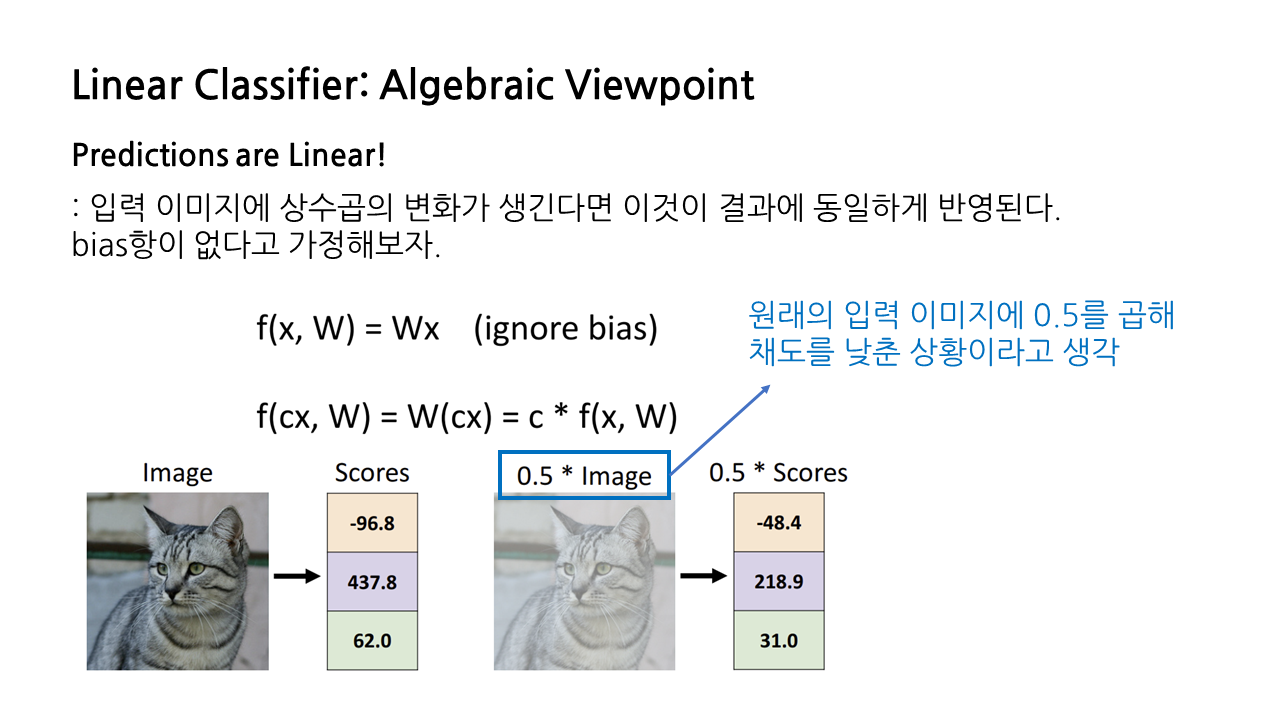
대수적 관점에서의 가장 큰 특징 중 하나는 입력 이미지에 상수곱의 변화가 생겼을 때 이것이 결과에 동일하게, 즉 선형적으로 반영된다는 것이다. 아래 그림에서 원래의 입력 이미지에 0.5를 곱해 채도를 낮춘 상황이라고 생각했을 때, 결과로 출력되는 점수도 각각 0.5배 된 것을 확인할 수 있다.
3) Visual Viewpoint
linear classifier를 바라보는 세 가지 관점 중 두 번째인 'Visual Viewpoint'에 대해 소개하겠다. 앞서 대수적 관점과는 달리 가중치 행렬의 각 행이 이미지와 동일한 shape을 가지도록, 즉 원래 이미지가 2*2였다면 가중치 행렬도 2*2가 되도록 하는 것이 visual viewpoint의 특징이다.
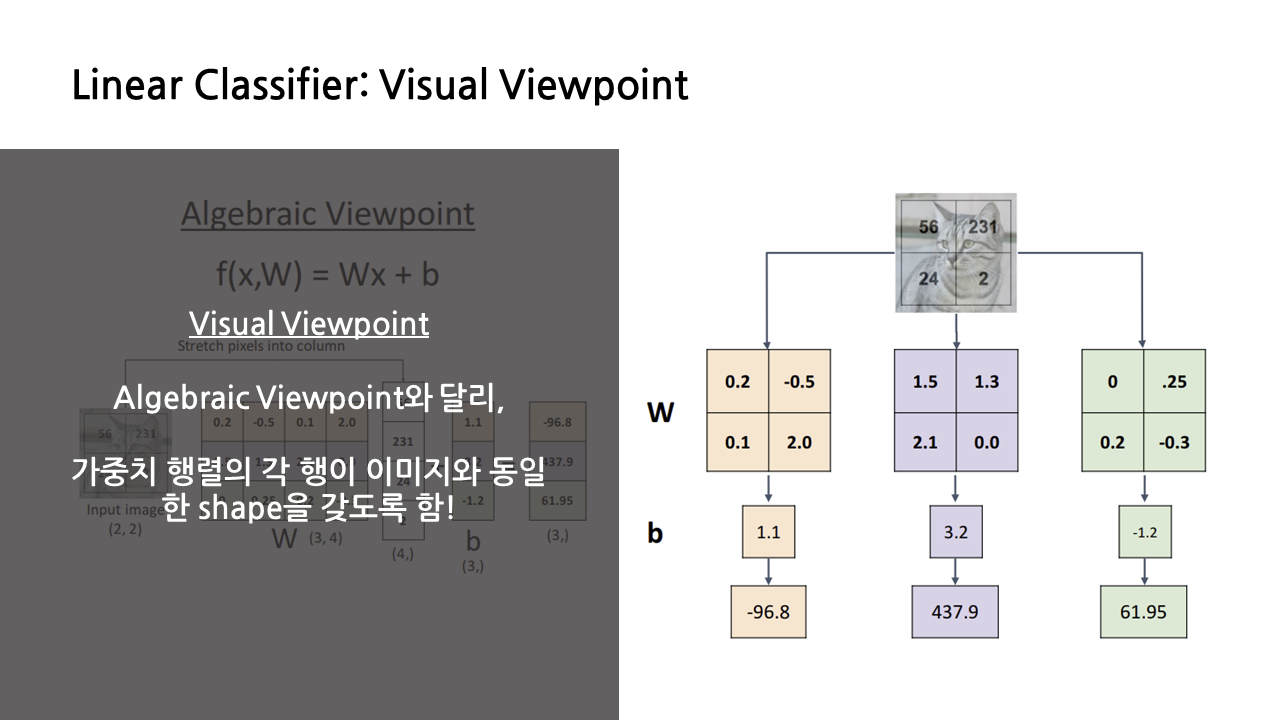
가중치 행렬의 각 행이 이미지와 동일한 shape을 갖기 때문에 가중치 각각에 대한 시각화를 할 수 있고, 그 결과 클래스 당 하나씩 총 10개의 이른바 '템플릿'이 생성된다.

템플릿은 우리가 구분하고자 하는 카테고리 당 하나씩 만들어진다. 우리의 예시에서는 10개의 카테고리가 있으므로 템플릿도 10개가 생성된다. 그 이후는 대수적 관점에서 보았던 것처럼 벡터 간 내적 연산을 수행하여 입력된 이미지가 각 템플릿과 얼마나 잘 맞는지를 계산한다.

비행기 템플릿을 보면 가운데 무언가가 있고, 전체적으로 파란색을 띤 이미지로 생성되었고, 사슴 템플릿은 가운데 갈색의 무언가가 있고, 녹색 배경을 가진 이미지로 생성되었다.
그런데 이렇게 각 클래스별 템플릿을 생성한다는 특징이 linear classifier의 실패 요인과도 연결된다. 일례로, 숲속에 주차된 차 이미지가 입력 이미지로 주어진다면 linear classifier에 혼돈을 불러일으킬 수 있다. 차 형태는 car template에 잘 매칭되는 반면, 녹색 배경은 deer template에 더 잘 매칭되기 때문에, linear classifier 입장에서는 이 이미지를 차로 분류해야 할 지 사슴으로 분류해야 할 지 헷갈릴 것이다.



visual viewpoint에서 확인할 수 있는 linear classifier의 실패 요인이 하나 더 있다. 이는 linear classifier가 하나의 클래스 당 하나의 템플릿만 학습할 수 있다는 데서 오는 문제이다.
만일 하나의 카테고리에 속한 이미지들이 다양한 자세나 형태를 가질 수 있다면 어떻게 될까? 예를 들어 말은 왼쪽을 보고 있을 수도 있고 오른쪽을 보고 있을 수도 있는데, linear classifier는 서로 다른 방향을 보고 있는 말에 대해서 각기 다른 템플릿으로 학습할 수 없다.
그래서 linear classifier가 하나의 템플릿만으로 서로 다른 방향을 보고 있는 말 이미지를 학습하기 위해 선택한 최선의 방법이 바로 머리가 두 개 달린 말 템플릿을 만드는 것이었다. 이는 확실히 문제가 있다.


4) Geometric Viewpoint
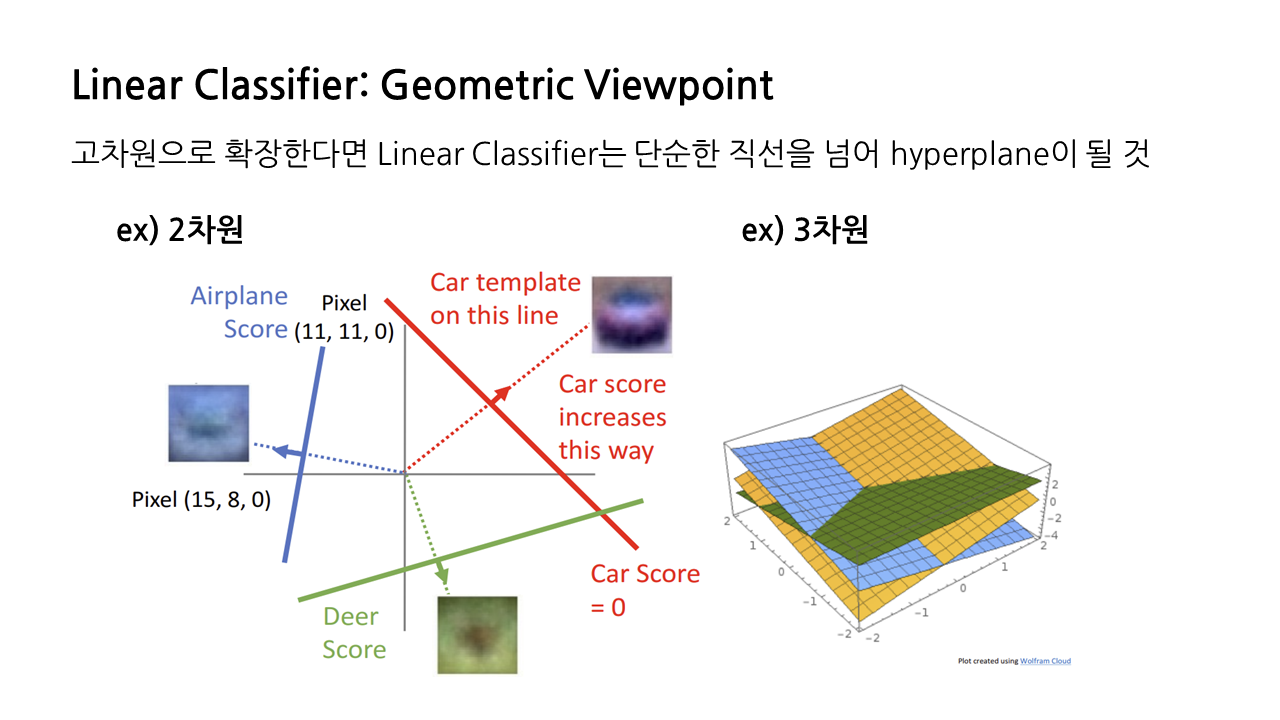
linear classifier를 바라보는 세 가지 관점 중 마지막, 'Geometric Viewpoint'에 대해 소개하겠다. 지금은 입력 이미지가 '차'인지 아닌지를 구별하는 상황이라고 생각해보자.
- 우선 이미지에서 두 개의 픽셀을 잡아 각각을 x축, y축에 대응시킨다.
- 이때 car score가 0.5가 되는 선을 긋는다. 이 선을 기준으로 오른쪽에 있으면 차에 대한 점수가 높은 것이고, 왼쪽에 있으면 차에 대한 점수가 낮게 된다(이때 이 직선식은 앞서 본 f(x, W) = Wx+b라는 함수로부터 나왔다고 생각하면 된다).
- car score = 0.5 선을 기준으로 오른쪽으로 갈수록 car score가 증가하므로, 이 선에 수직인 방향으로 car score가 선형적으로 증가하게 되고, 따라서 car 템플릿은 이 수직선 위에 있다고 볼 수 있다.
이것이 바로 linear classifier를 바라보는 geometric viewpoint의 기본 아이디어다.


방금은 픽셀 두 개만 고려한 2차원 상황을 생각했지만, 이를 고차원으로 확장한다면 linear classifier는 단순한 직선을 넘어 hyperplane으로 표현될 것이다.
5) Hard Cases for a Linear Classifier
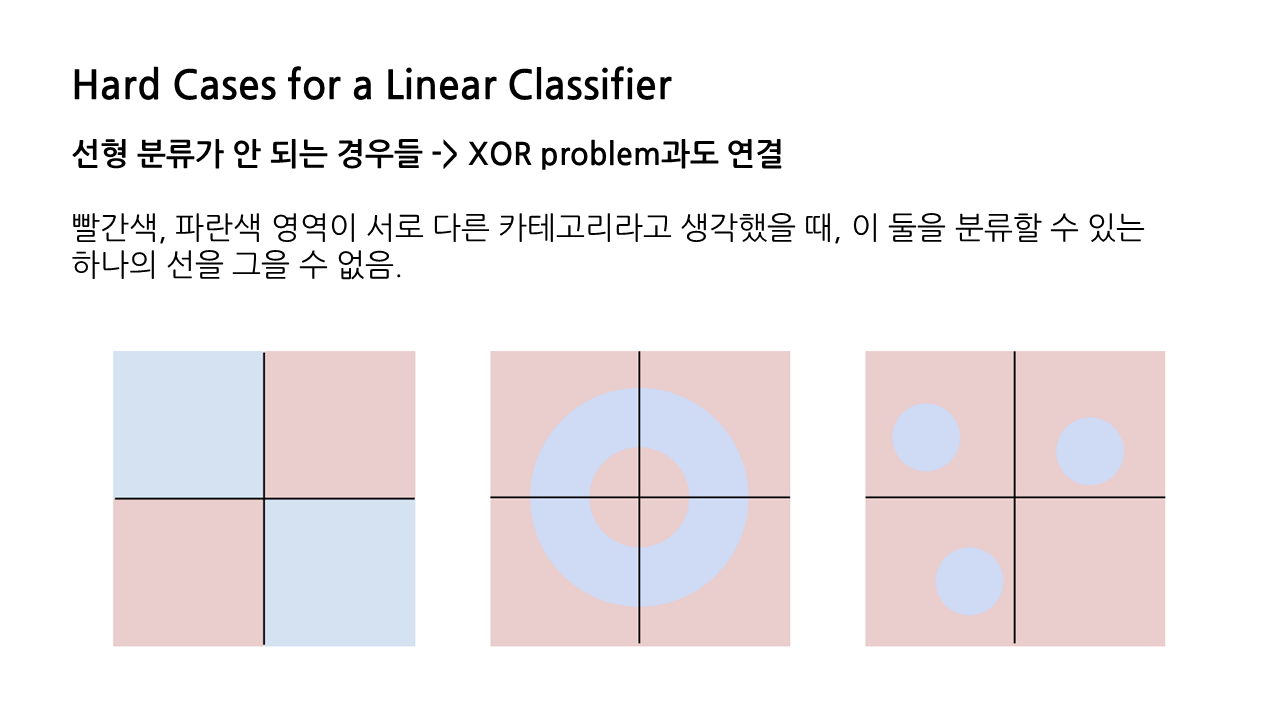
다만 linear classifier에는 명백한 한계가 존재하는데, 바로 선형 분류가 불가능한 경우에는 적용이 안 된다는 점이다. 그림에서 빨간색, 파란색 영역이 서로 다른 카테고리에 속하고, 이 둘을 분류하고 싶은 상황이라고 할 때, 하나의 선을 그어 둘을 구분 지을 수 있는 방법이 존재하지 않는다.
6) How to Choose 'W'?
이제 우리는 linear classifier를 바라보는 세 가지 관점이 있음을 알았다. 이 세 가지 관점에서 공통적으로 '가중치'를 곱하는 원리가 사용되었는데, 그렇다면 이 가중치 W는 어떻게 찾을 수 있을까? 이 질문에 대한 답은 바로 'Loss Function'인데, 여기서부터는 다음 글에서 다루기로 하겠다.


'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
|---|---|
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 2강. Image Classification (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 2강. Image Classification (1) (1) | 2023.01.21 |



