
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- GNN
- geometric viewpoint
- algebraic viewpoint
- FORTRAN
- human keypoints
- format이 없는 입출력문
- cv
- gfortran
- multiclass SVM loss
- object detection
- 산술연산
- cross-entropy loss
- implicit rules
- fortran90
- 내장함수
- L2 distance
- data-driven approach
- cs224w
- Semantic Gap
- image classification
- feature cropping
- print*
- L1 distance
- EECS 498-007/598-005
- tensor core
- parametric approach
- computer vision
- Graph Neural Networks
- visual viewpoint
- implicit rule
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 9강. Hardware and Software (2) 본문
[EECS 498-007/598-005] 9강. Hardware and Software (2)
ydduri 2023. 2. 23. 16:092. Software
먼저 프레임워크의 전체적인 계도를 살펴보자. 파란색 박스 친 부분이 현 세대의 프레임워크인데, 이중 PyTorch와 TensorFlow가 딥러닝 프레임워크 계의 양대산맥이라 할 수 있고, 특히 지금은 PyTorch의 점유율이 급격하게 커지고 있는 중이다. 강의 또한 이 두 프레임워크에 초점을 맞춰 진행된다.

우리가 딥러닝 프레임워크에 기대하는 세 가지 중요한 특징은 다음과 같다.
- 새로운 아이디어에 대한 빠른 prototyping이 가능: 이는 프레임워크가 딥러닝 프로젝트에서 공통적으로 수행되는 작업에 필요한 여러 레이어, 기능들을 제공해서 우리가 매번 같은 코드를 새로 쓰지 않도록 해야 한다는 의미
- backpropagation, computational graphs를 이용해 gradients 자동 계산
- GPU, TPU를 비롯해 미래에 개발될 다른 hardware device에 대해서도 효과적으로 작동
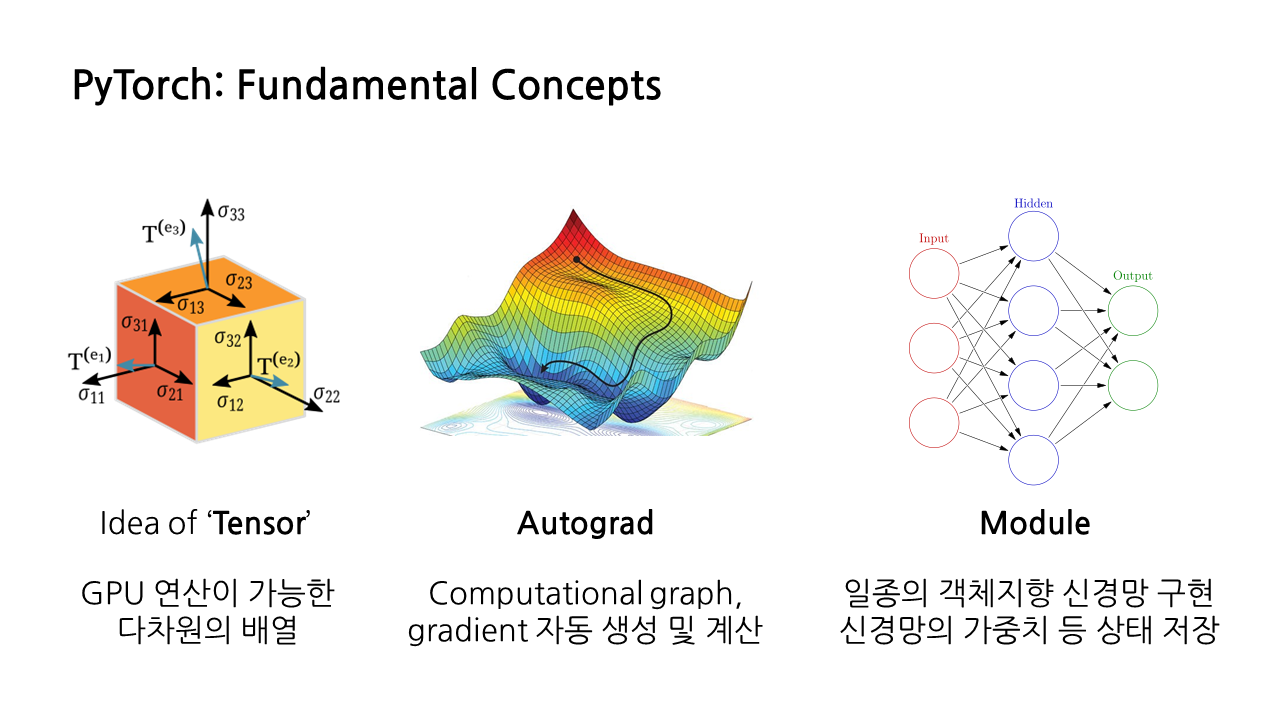
1) PyTorch: Fundamental Concpets
앞서 프레임워크 계도에서 소개한 딥러닝 프레임워크 양대산맥 중 PyTorch에 대해 알아보겠다. PyTorch에서는 신경망 모델을 구성하기 위한 세 가지 수준의 추상화를 제공한다(필자는 여기서 등장하는 추상화가 객체지향 프로그래밍 원칙의 추상화와 같은 의미, 즉 python의 클래스처럼 공통된 속성 혹은 행위가 있을 때 이를 새로이 개념화해서 적용하는 것이라고 이해했다).
(1) Idea of 'Tensor'
PyTorch에서 제공하는 추상화 중 가장 낮은 레벨은 'Tensor'의 개념이다. 이는 GPU에서 연산을 수행할 수 있도록 해주는 다차원의 배열로, 기본적으로는 numpy와 비슷하나 GPU에서 구동될 수 있다는 차이점이 있다.
(2) Autograd
이는 앞서 딥러닝 프레임워크의 세 가지 특징 중 두 번째를 만족하는 것으로, computational graph를 알아서 만들고, gradient를 자동으로 계산해준다.
(3) Module
이는 일종의 '객체지향 신경망'을 구현할 수 있도록 해준다. 대표적인 객체지향 프로그래밍 언어인 파이썬의 ‘클래스’가 클래스에 포함된 인스턴스 메소드의 정보를 저장하는 것과 비슷하게, ‘모듈’은 신경망의 가중치 등 상태를 저장해준다. 이러한 모듈을 조합하면 더 복잡한 모델을 쉽게 만들 수 있다.
2) PyTorch: Tensors 구현 코드 예제
PyTorch에서 실제로 tensor를 구현하는 코드는 다음과 같다.
- 빨간색: 데이터 및 가중치를 위한 random tensors 생성하는 부분(뒤의 코드에서 실제 값으로 대체)
- 초록색: forward pass를 통해 predictions 및 loss 계산하는 부분
- 파란색: backward pass를 통해 gradient 계산하는 부분

CPU를 사용할지, GPU를 사용할지는 다음과 같이 tensor 선언 시에 원하는 디바이스를 지정해주면 된다.

3) PyTorch: Autograd 구현 코드 예제
Autograd 기능은 PyTorch에서 매우 간결하게 구현할 수 있다. gradient를 계산하고 싶은 tensor에 'requires_grad = True'라는 인자를 추가해주기만 하면 된다.

Autograd를 사용하면, 알아서 신경망의 상태와 가중치 등을 자동 저장하기 때문에 우리가 직접 계산의 중간 산물을 추적하는 코드를 짤 필요가 없다. 따라서 텐서만 사용했을 때의 코드와 비교해보면, forward pass 부분이 매우 간결해진 것을 볼 수 있다.

Autograd를 사용했을 때, gradient를 구하기 위해서는 'loss.backward()'라는 코드 딱 한 줄만 추가해주면 된다. 이는 우리가 'requires_grad = True'로 지정한 inputs에 대해 gradient를 계산해 주는 코드이다.

이제부터 Autograd의 동작 과정을 좀 더 구체적으로 살펴보겠다.
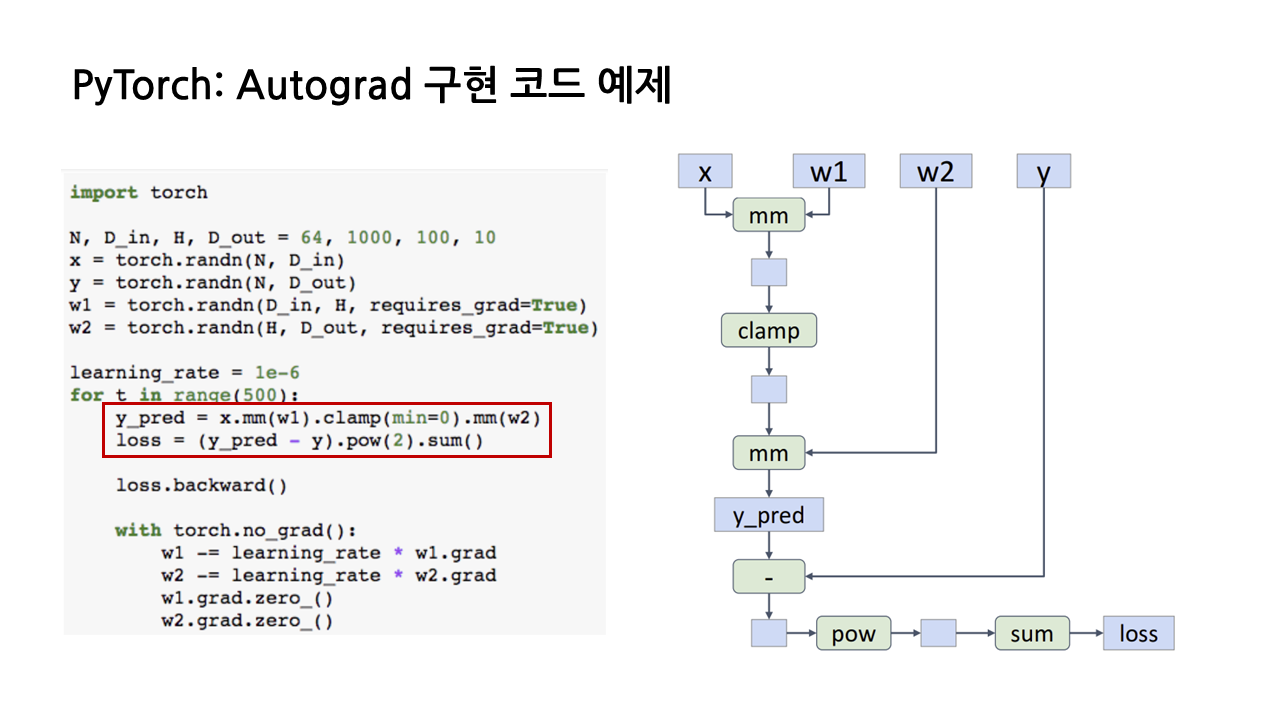
(1) PyTorch는 우선 'requires_grad = True'로 선언된 input이 있는지 체크하고, 만일 있다면 해당 input의 계산을 나타내는 computational graph를 백그라운드에서 build up하기 시작한다.
예를 들어, 아래 그림에서 x와 w1 사이의 matrix multiplication을 계산하는 빨간 박스 코드를 수행할 때, w1이 'requires_grad = True'로 선언된 input이므로 오른쪽과 같은 computational graph를 그리기 시작한다.

(2) Autograd의 특징은 'requires_grad = True'가 포함된 input이 관여하는 모든 연산에 대해 computational graph를 그린다는 것이다. 이제 x와 w1의 행렬곱 결과에 clamp 함수를 쓰게 되는데, 이 또한 w1이 관여하는 연산이므로 graph를 추가해준다.
- clamp 함수: 함수의 입력으로 들어오는 모든 값들을 특정 범위 안으로 조정해주는 역할. 여기서는 min = 0으로 설정했으므로, x와 w1 행렬곱 결과의 최솟값이 0이 되도록 조정하는 역할을 함.
- pow 함수: 괄호 안의 숫자만큼 거듭제곱 수행하는 함수

(3) 이런 식으로 'requires_grad = True'인 input과 연관된 모든 연산에 대해 computational graph를 그리면 다음과 같은 그래프가 탄생하고, 이때 그래프의 끝 노드는 loss가 된다.
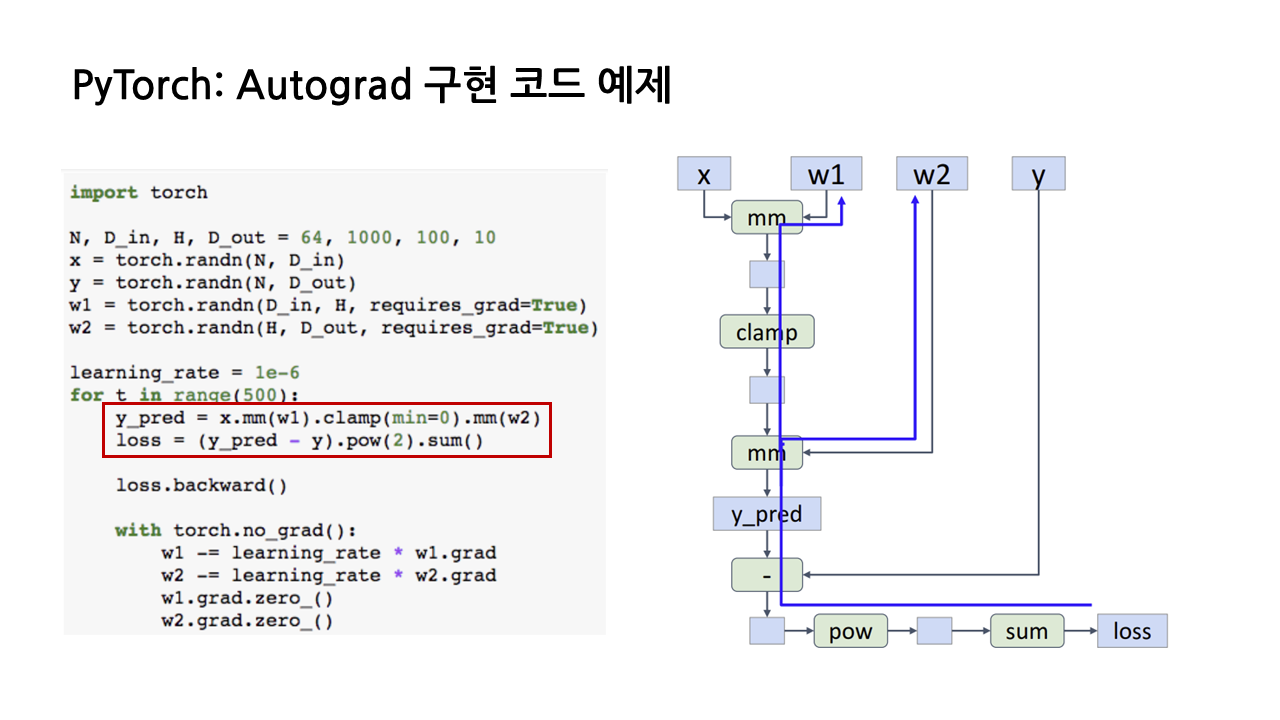
(4) 이렇게 그래프를 다 그리고 나면 PyTorch는 'requires_grad = True'인 input을 찾아 backpropagation을 진행하며 해당 input에 대한 gradient를 계산한다. 계산된 w1, w2 각각의 gradient는 w1.grad, w2.grad라는 새로운 텐서에 저장되고, 그러고 나면 그래프 구조는 모두 지워진다.
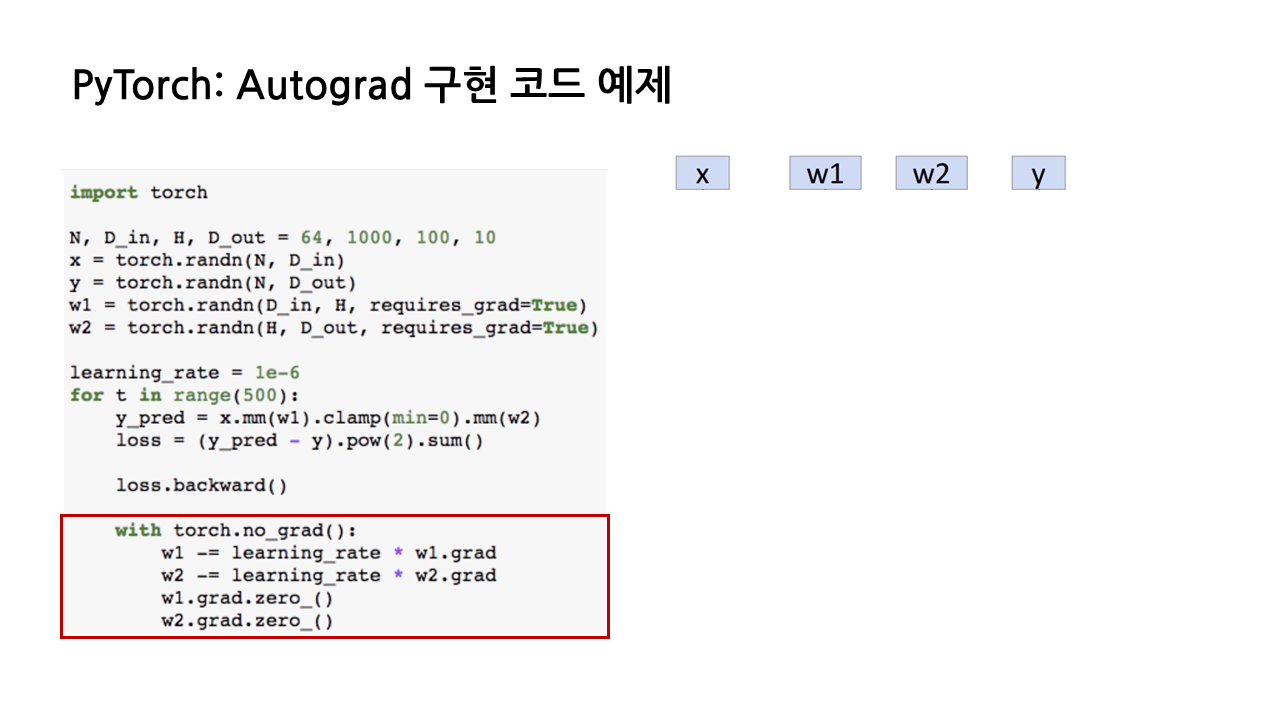
(5) 이제 굉장히 중요한 대목이 남았는데, 반복문을 한 번 돌 때마다 w1.grad와 w2.grad를 0으로 초기화해주는 부분이다. PyTorch에서 gradient 계산은 기존에 계산한 값을 덮어쓰는 식이 아니라, 새로운 gradient 값을 구했을 때 기존의 값에 더해가는 식으로 진행되기 때문에, 반복 한 번이 끝나면 w1.grad, w2.grad를 초기화해야 한다.
또 눈여겨보면 좋을 점은 해당 코드들이 'torch.no_grad():'라는 context manager 안에 들어가 있다는 것인데, 이렇게 경사하강법을 진행하는 동안에는 이에 대한 gradient 계산이 불필요하기 때문이다.
4) PyTorch: New functions
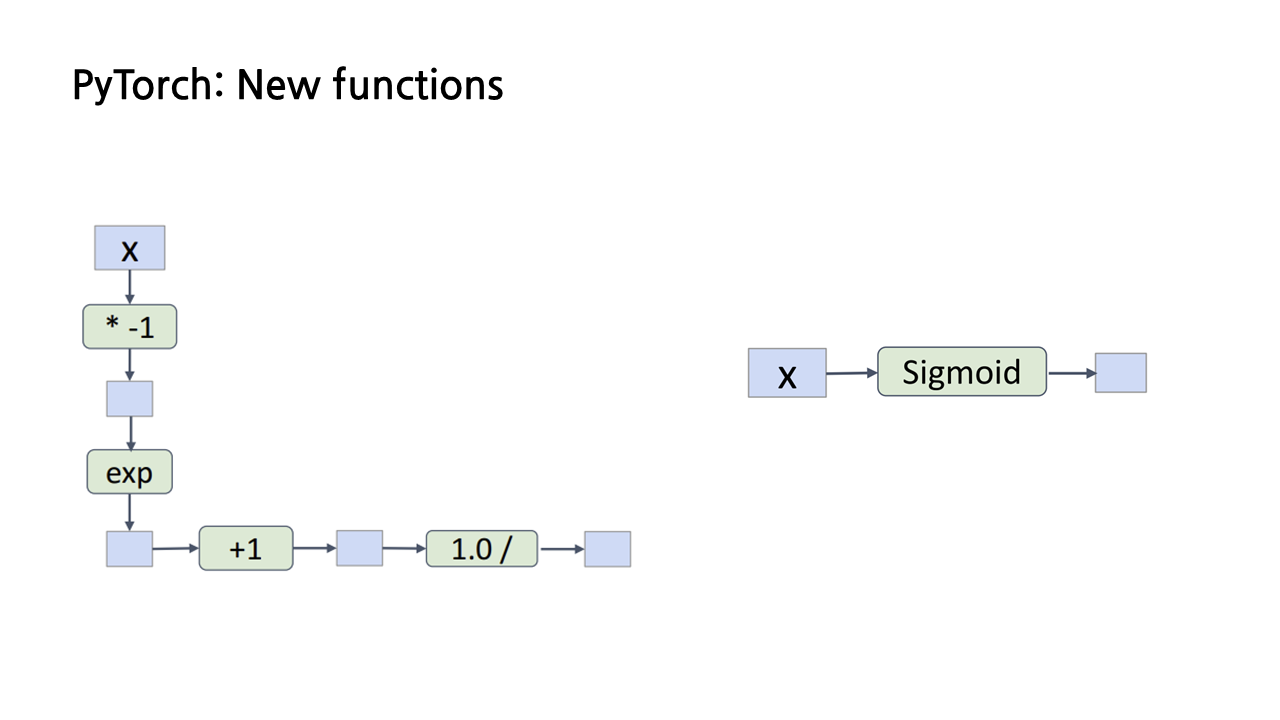
지금까지는 행렬곱이나 clamp처럼 PyTorch에서 기본적으로 제공하는 연산자를 이용해 y값을 예측했는데, PyTorch의 강점 중 하나는 임의의 파이썬 함수에 대해서 확장이 가능하다는 것이다. 아래 그림에서 볼 수 있듯이, 만일 우리가 왼쪽과 같이 파이썬 함수를 이용해 sigmoid 식을 정의한다면, 우리는 y값을 예측하는 부분을 이렇게 sigmoid 함수로 대체할 수 있다.

문제는 PyTorch가 이렇게 tensor를 입력으로 받는 함수에 대해서도 computational graph를 자동으로 구현한다는 것이다. 따라서 sigmoid 함수에 대해 backpropagation을 진행한다면 아래 그림에서 좌측 하단과 같은 그래프를 거슬러 올라가는 식으로 계산이 이루어지게 된다.
아까는 computational graph 자동으로 그려서 알아서 gradient 계산해 주는 게 장점이라더니, 이게 왜 문제가 되나 싶을 수 있을 것이다. 그런데 강연자에 따르면 sigmoid를 비롯한 몇몇 파이썬 함수에 대해 이런 식으로 gradient를 계산하는 것은 불안정한 방법이라고 한다. 값이 NaN이 되거나 오버플로우가 발생하는 등의 문제가 생길 수 있다.

그래서 등장한 해결책이 바로 이론적인 지식을 활용해서 새로운 autograd function을 정의하는 방법이다. 우리는 sigmoid 함수의 gradient를 다음과 같은 식을 통해 구할 수 있음을 이미 알고 있으므로, 이 식을 토대로 다음과 같은 새로운 autograd function을 작성할 수 있다.

이를 통해, 우리는 이제 앞에서처럼 함수의 계산 단계 하나하나를 computational graph의 노드로 만드는 게 아니라 함수 그 자체가 그래프의 단일 노드가 될 수 있게 구현할 수 있게 되었다. 하지만 이 방법은 구현이 복잡하기 때문에 어느 정도의 불안정성을 감수하고 처음에 소개한 것처럼 파이썬 함수를 활용하는 방법을 더 많이 사용한다고 한다(뭔가 허망...).
5) PyTorch: nn Module
이제 우리가 아직 다루지 않은 마지막 추상화인 'Module' 예제를 살펴보겠다. 그중에서도 예시로 살펴볼 nn module은 PyTorch에서 신경망을 구축할 수 있게 해주는 일종의 '객체지향 API'이다. nn module을 이용해서 여러 개의 레이어를 가지며, 그에 따른 weight, bias를 구할 수 있는 모델을 구축할 수 있다.
또한 nn module을 이용하면 forward pass와 loss 구하는 부분 및 backward pass를 굉장히 간단하게 구현할 수 있다는 장점이 있으며, 이외의 구조는 앞서 봤던 것과 유사하다.

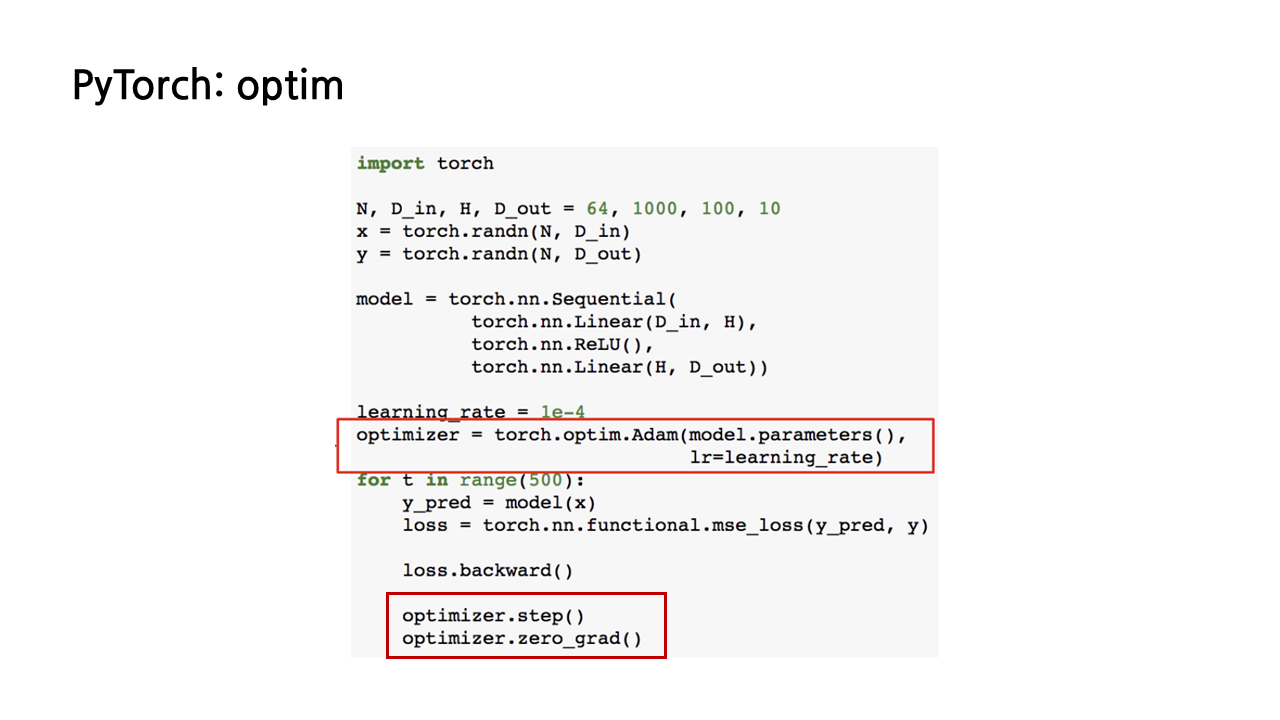
6) PyTorch: optim Module
optimizer 또한 optim module을 이용해 구현할 수 있다. 예시 코드에서는 optimizer계의 1인자라 할 수 있는 Adam optimizer를 사용했다(4강의 Optimization에서도 공부한 바 있듯이, 잘 모르면 일단 Adam을 쓰고 보자 할 정도로 일반적으로 가장 좋은 성능을 내는 optimizer인데, computer vision 분야에서는 SGD도 보편적으로 쓴다고 한다). optimizer 또한 반복이 한 번 끝나고 나면 초기화를 해주어야 한다.
7) PyTorch: nn - Defining Modules
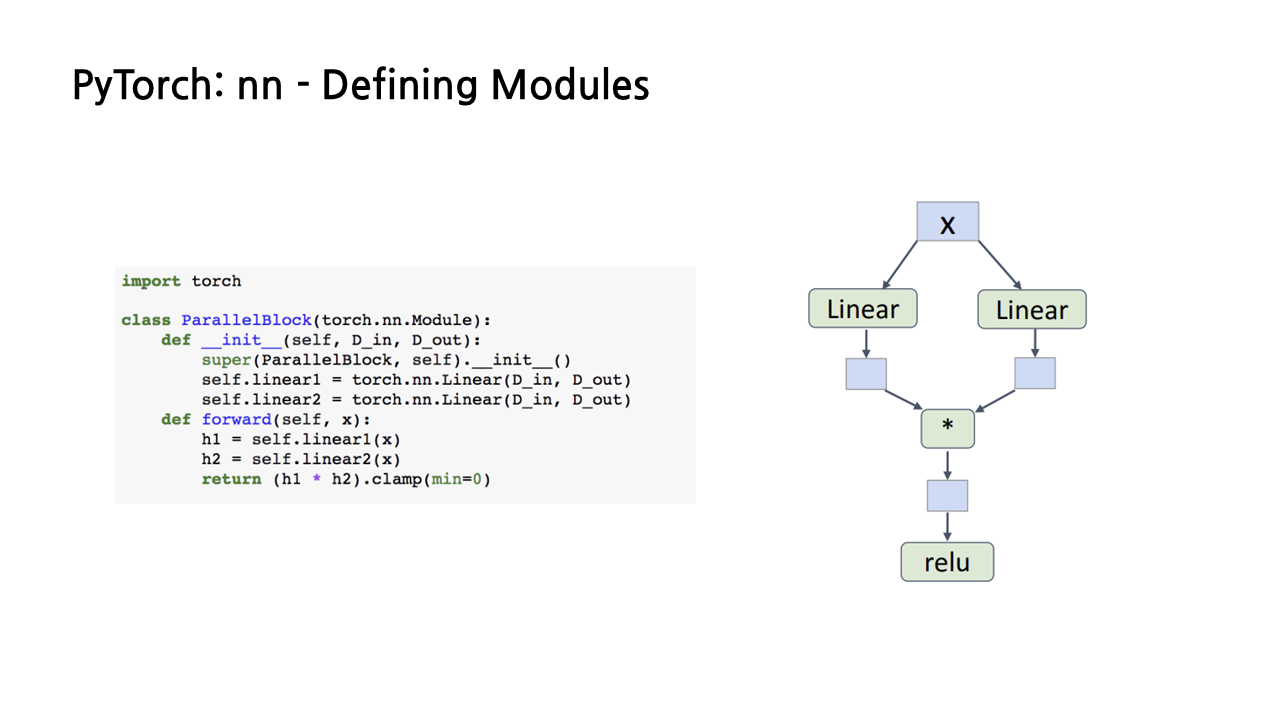
PyTorch는 모듈을 customizing할 수 있는 기능도 제공한다. 만일 앞서 본 sequential model보다 복잡한 모델을 구현해야 할 경우 이와 같이 torch.nn.Module을 상속받는 class를 만듦으로써 새로운 모듈을 정의할 수 있다. 모델을 구현할 때 이런 식으로 새로 정의한 모듈을 복합적으로 사용하는 경우가 대부분이다.
실제로 코드를 보면 ParallelBlock이라는 이름의 모듈과 nn.linear를 통해 구현된 선형 레이어가 함께 하나의 모델을 이루고 있는데, 이중 ParallelBlock은 위에서 클래스를 통해 새로 정의한 모듈이다.

ParallelBlock 모듈의 경우 nn.linear를 이용하여 self.linear1과 self.linear2라는 2개의 linear layer를 평행하게 배치하였고, forward pass를 통해 이 둘을 곱함으로써 하나의 fully connected layer를 만들었다.
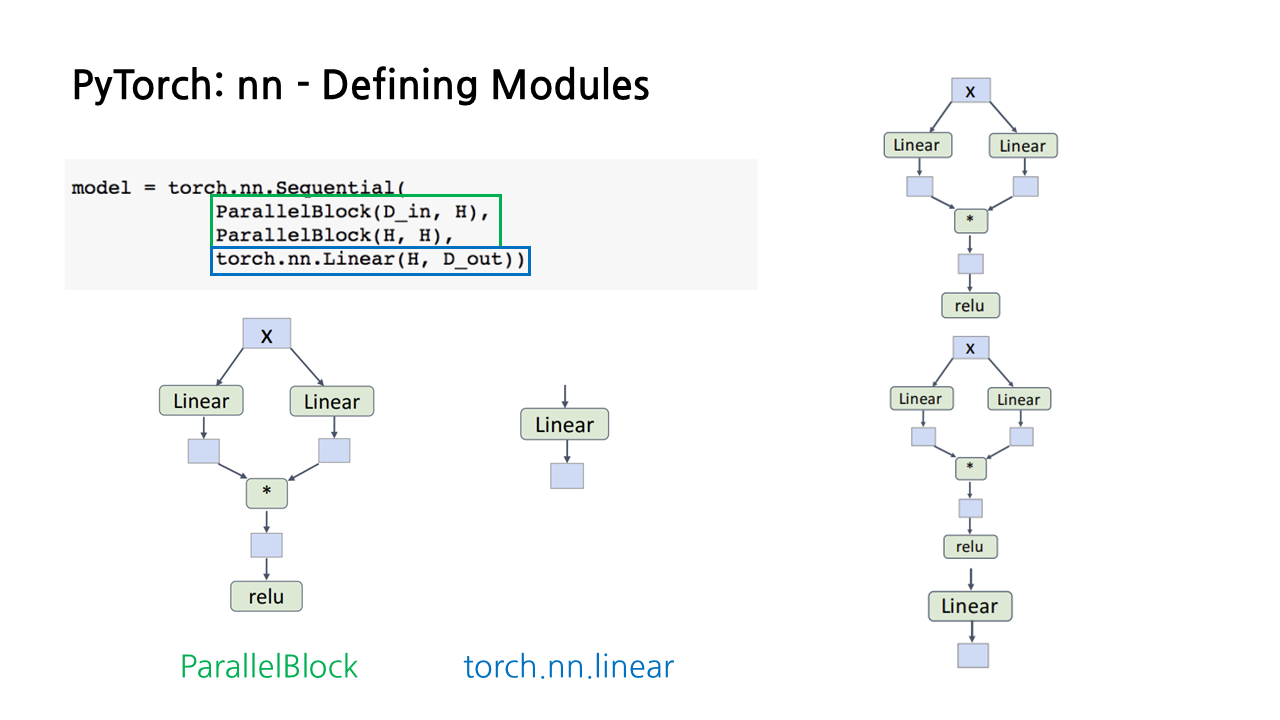
모델의 구조를 computational graph로 나타내면 아래와 같다. ParallelBlock 모듈을 통해 구현한 fully connected layer와 torch.nn.linear를 통해 구현한 또다른 fully connected layer를 sequential하게 쌓으면 모델의 구조가 완성된다.
8) PyTorch: DataLoaders & Pretrained Models
그밖에도 PyTorch에서는 아래와 같이 데이터를 로딩하고, mini batch를 생성하고, 데이터를 섞는 등의 기능을 제공해주는 dataloaders 메커니즘을 사용할 수도 있고, 사전 훈련된 pre-trained model을 제공하기도 합니다.

9) PyTorch: Dynamic and Static Computation Graph
앞서 PyTorch에서 Autograd 구현 예제를 설명하면서, 반복을 한 번 할 때마다 forward pass를 통해 computational graph를 그리고, backward pass를 통해 loss를 찾고, loss를 불러오고 나면 그래프를 지우고, 다음 epoch을 반복하는 과정을 설명 했는데, 이를 ‘Dynamic Computation Graph’라 한다.

그런데, 매 epoch마다 같은 형태의 그래프를 그려야 하는데 왜 굳이 그래프를 그렸다 지웠다 하는 걸 반복하는 것일까? 상식적으로 매우 비효율적인 메커니즘이 맞지만, 필요한 순간이 있기 때문이다.
예시 코드와 같이 이전의 loss를 가중치 업데이트에 사용해야 할 경우, 즉 반복문 안에 조건문이 들어간 control flow가 모델에 포함된 경우 dynamic computation graph가 유용하게 사용될 수 있다. 예시 코드를 통해 설명하자면, 첫 번째 반복에서는 w2a가 가중치로 사용되었지만, 그 다음 반복에서는 조건을 만족하는지 여부에 따라 가중치가 w2b로 바뀔 수도 있기 때문에, 매 반복마다 그래프를 새로 그려주는 것이 이러한 control flow를 수행하기에는 적합하다.

유용한 순간이 있긴 해도 dynamic computation graph가 비효율적이라는 것은 자명한 사실인데, 그래서 이의 대안으로 등장한 것이 바로 static computation graph다. 이것은 같은 그래프를 반복해서 계속 사용할 수 있도록 하는 것인데, 이러한 static graph를 구현하도록 해주는 것이 바로 jit이다.

앞서 조건문이 들어간 예제 코드를 dynamic graph와 static graph로 각각 나타낸 모습이다. 이걸 보면 둘의 차이를 더 명확하게 알 수 있는데, static graph는 같은 그래프를 매 epoch마다 반복해서 사용하는 것이 목적이기 때문에, 그래프에 조건문까지 반영된 것을 확인할 수 있다.

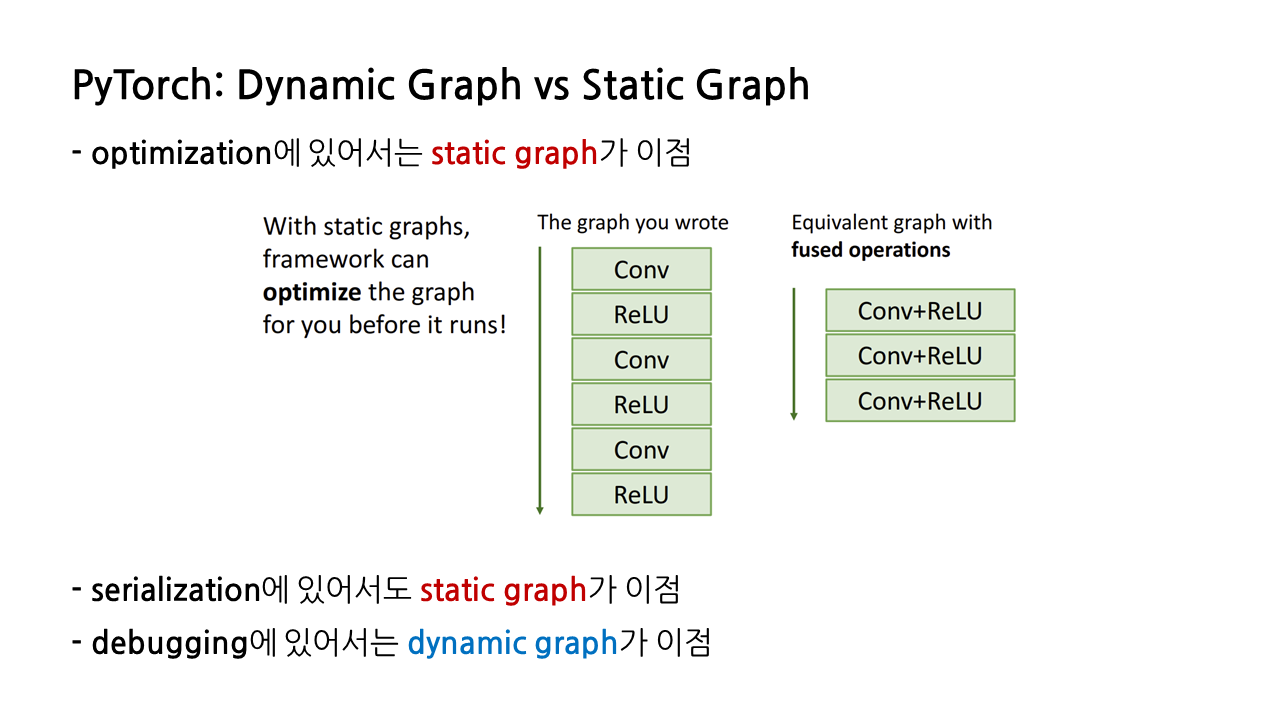
dynamic graph와 static graph는 각기 이점을 가진 부분이 다르다. 먼저 static graph의 경우 optimization에 있어 이점을 가지는데, 코드를 작성할 때 레이어를 따로따로 썼더라도 convolution, ReLU 레이어와 같이 서로 합칠 수 있는 것들은 알아서 합쳐주는 등 최적화가 자동으로 이루어진다.
또다른 이점은 ‘serialization’, 즉 ‘직렬화’다. 직렬화는 메모리를 디스크에 저장하거나 통신에 사용할 수 있는 형식으로 변환하는 것인데, 직렬화를 이용하면 static 그래프를 data structure 형태로 디스크에 저장할 수 있다. 이렇게 되면, 모델을 구현하는 코드를 파이썬으로 작성한 뒤, 이렇게 만들어진 static graph를 data structure 형태로 디스크에 올릴 수 있게 되고, 그러면 파이썬이 아닌 다른 언어도 해당 그래프에 접근할 수 있게 되기 때문에, 모델을 실행할 때는 비교적 속도가 빠른 C++등을 사용할 수 있게 된다.
하지만 이렇게 모델 구현은 파이썬, 구동은 C++과 같은 식으로 서로 다른 언어를 사용한다면 디버깅이 쉽지 않다는 단점이 있고, 그런 점에서 dynamic graph가 디버깅 면에 있어서는 이점을 가진다.
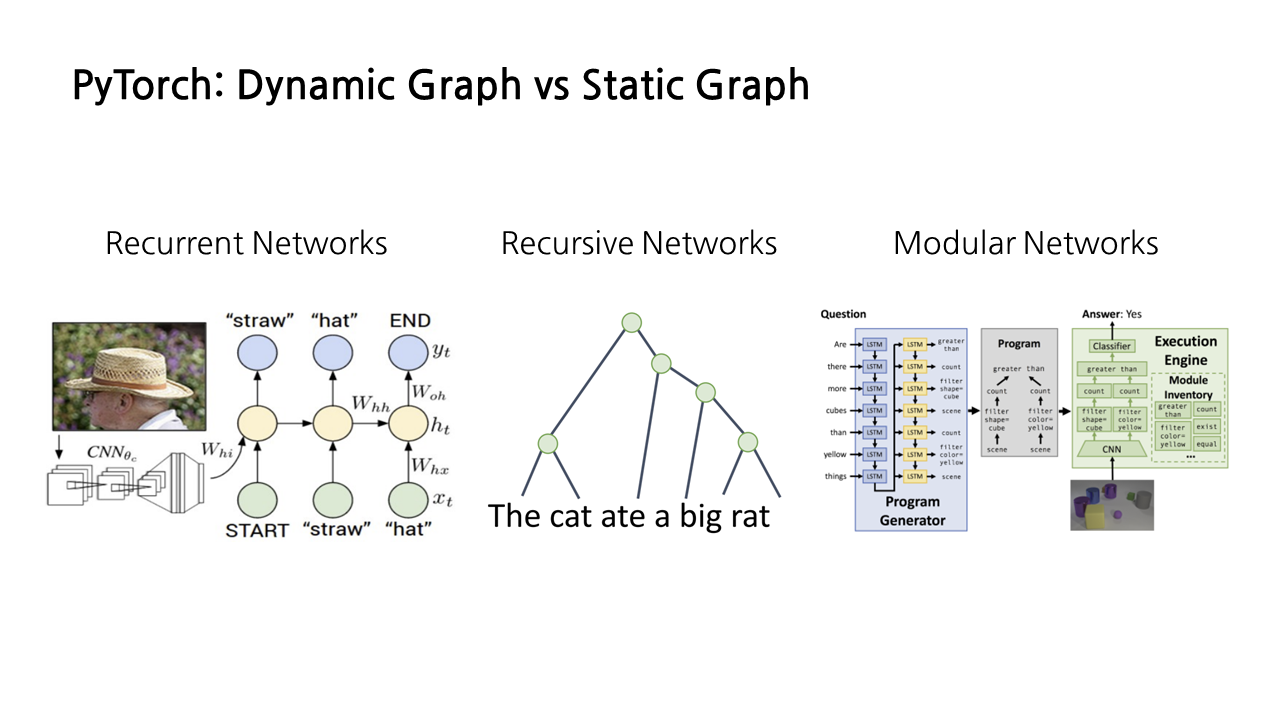
그밖에도 dyamic graph만이 수행할 수 있는 작업들이 있는데, 모델의 구조가 input에 따라 결정되는 Recurrent Networks, Recursive Networks, Modular Networks와 같은 모델들의 경우 dynamic graph를 사용해야 한다고 한다.
10) PyTorch and TensorFlow
이 다음부터는 TensorFlow에 대한 간단한 소개가 이어지는데, 필자는 PyTorch를 위주로 공부 중이라 해당 내용에 대한 정리는 생략하도록 하겠다. 대신 PyTorch와 TensorFlow 1.0, 2.0의 특징을 정리하는 것으로 마무리하고자 한다.
(1) PyTorch
- 꼭 필요한 API들이 깔끔하게 정리되어 있다.
- 디버깅을 위한 dynamic graph 생성이 쉽다.
- JIT을 통한 static graph 생성도 가능하다.
- 다만 모바일에서 효율적으로 사용하는 것이 어렵다.
(2) TensorFlow 1.0
- 디폴트가 static graph이다.
- 디버깅이 비교적 복잡하다.
- API가 깔끔하지 않다.
(3) TensorFlow 2.0
- 디폴트가 dynamic graph이다.
- Keras API로 표준화되어 있다.

'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 16강. Detection and Segmentation(2) (0) | 2023.03.03 |
|---|---|
| [EECS 498-007/598-005] 16강. Detection and Segmentation(1) (0) | 2023.02.26 |
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 3강. Linear Classifier (1) (0) | 2023.01.21 |



