
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- GNN
- computer vision
- Graph Neural Networks
- cv
- image classification
- algebraic viewpoint
- data-driven approach
- Semantic Gap
- object detection
- tensor core
- human keypoints
- visual viewpoint
- gfortran
- fortran90
- format이 없는 입출력문
- L1 distance
- FORTRAN
- feature cropping
- parametric approach
- EECS 498-007/598-005
- implicit rule
- geometric viewpoint
- multiclass SVM loss
- L2 distance
- 산술연산
- 내장함수
- cross-entropy loss
- implicit rules
- print*
- cs224w
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 2강. Image Classification (1) 본문
[EECS 498-007/598-005] 2강. Image Classification (1)
ydduri 2023. 1. 21. 16:26※ Deep Learning for Computer Vision 카테고리의 글 시리즈는 Michigan University의 동명의 강의(EECS 498-007 / 598-005) 내용을 정리한 것입니다. 혹시 오류를 발견하신다면 언제든지 댓글로 알려주시면 감사하겠습니다!
강의 영상: https://youtu.be/dJYGatp4SvA
1. Image Classification
Deep Learning for Computer Vision 강의를 관통하는 큰 주제이자 컴퓨터 비전 분야의 'Core Task'
1) Semantic Gap(의미론적 차이)
사진을 보고 이게 고양인지 강아진지 구별하는 것은 우리 인간에게 일도 아니기 때문에, 언뜻 보기에 단순해 보이는 Image Classification이 컴퓨터 비전 분야에서 'Core Task'씩이나 된다는 것이 의아하게 느껴질 수도 있다.
그런데 컴퓨터 입장에서 이미지는 우리와는 다른 의미를 가진다. 우리는 이미지를 이미지 그 자체로 인식하지만, 컴퓨터는 모든 것을 숫자로 인식한다. 컴퓨터에서 이미지는 0~255 사이의 pixel과 red, green, blue의 3개 채널로 이루어진 '거대한 숫자 집합'에 불과하다. 이렇게 이미지를 바라보는 인간과 컴퓨터의 인식 차이를 'Semantic Gap(의미론적 차이)'라 한다.
2) Challenges for Image Classification
이미지를 숫자로 인식한다는 컴퓨터의 특성에서 기인하는 여러 어려움들이 있다.
(1) Viewpoint Variation
카메라가 조금만 움직여도 사진을 구성하는 픽셀이 모조리 변한다.

(2) Intraclass Variation
유전적 다양성은 컴퓨터를 힘들게 한다.

(3) Fine-Grained Categories
고양이 안에서도 품종별로 세분화하는 작업 등을 일컫는다.

(4) Background Clutter
배경으로 인해 식별이 어려운 경우를 말한다.

(5) Illumination Changes

(6) Deformation
강사님: 제 생각엔 고양이만큼 다양한 변형이 가능한 동물은 없을 것 같습니다

(7) Occlusion
아래 사진들처럼 고양이의 일부밖에 볼 수 없는 상황이 있을 수 있다.

3) Image Classification Application
이토록 많은 난관이 있지만 그럼에도 Image Classification을 연구하는 이유는 매우 유용하기 때문이다. 일례로, 의학 분야에서 양성 종양과 악성 종양을 구분하거나, 천문학 분야에서 은하의 형태를 구분하는 데 Image Classification 모델이 유용하게 쓰일 수 있다. 그밖에도 Image Classification을 이용하면 아래와 같은 일들이 가능하다.
(1) Object Detection
이미지를 Classification(분류)해주는 것에서 더 나아가 하나의 객체라고 판단되는 곳에 직사각형을 그려주는 Localization 작업까지 할 수 있다.

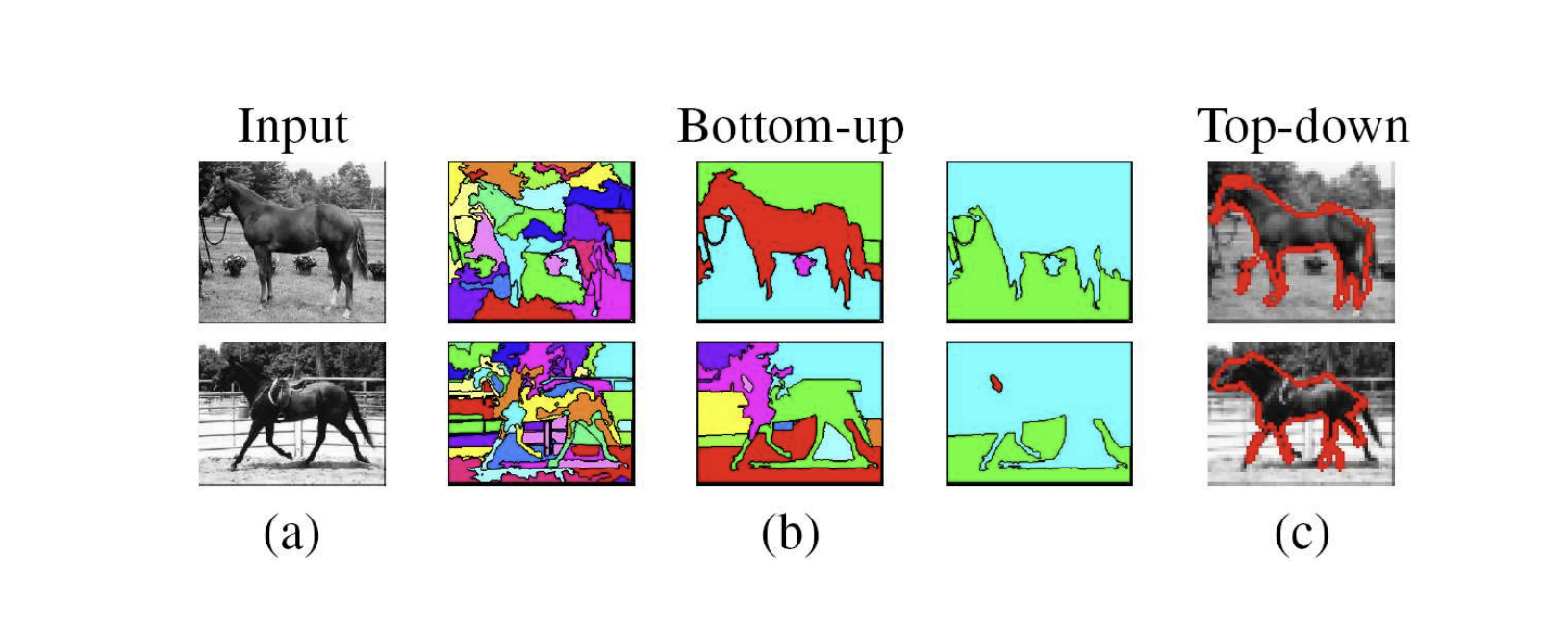
(2) Image Captioning
말그대로 이미지에 캡션을 달아주는 일로, 이미지를 보고 어떤 이미지인지 언어로 설명하는 작업을 말한다. 접근 방식은 크게 'Top-Down Approach'와 'Bottom-Up Approach'로 구분된다.
Top-Down Approach: 이미지를 통째로 시스템에 통과시켜서 얻은 '요점'을 언어로 변환
- 현재 가장 많이 쓰이고 있는 접근 방식이다.
- Recurrent Neural Network(RNN)을 활용한 학습이 가능하며, 이 방식의 성능이 가장 좋다고 평가받는다.
- 이미지의 디테일한 부분에 집중하는 것이 상대적으로 어렵다.
Bottom-Up Approach: 이미지를 부분적으로 접근, 여러 부분들로부터 단어를 도출한 뒤 이를 결합하여 문장 생성
- 이미지의 여러 부분으로부터 하나씩 단어들을 뽑아낸 뒤 조합하기 때문에 디테일에 신경을 써줄 수 있다.
4) Attempts to Image Classification

Image Classification을 위해 처음으로 시도된 방법 중 하나는 바로 edge를 이용하는 것이었다.
가장자리를 따라 outline을 만들어내고, 세 개의 선이 맞닿는 부분을 'corner'라고 정의한다. 고양이, 개 등 객체별로 corner 집합의 규칙을 이끌어내 이미지를 구별하겠다는 아이디어인데, 언뜻 봐도 쉽지 않아 보인다. 실제로 이 알고리즘에는 다음과 같은 문제점들이 있다.
- 매우 나약함: 고양이를 예로 들면 무늬, 자세 등에 너무 쉽게 영향을 받음
- 낮은 확장성: 고양이, 개 등 객체별 집합을 모두 정의해야 하므로 확장성이 매우 낮음
이러한 알고리즘의 문제를 해결하기 위해 등장한 것이 'Data-Driven Approach(데이터 중심 접근법)'이다. 여기서부터는 다음 글에서 다루기로 하겠다.
'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
|---|---|
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 3강. Linear Classifier (1) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 2강. Image Classification (2) (0) | 2023.01.21 |



