
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- multiclass SVM loss
- gfortran
- Semantic Gap
- image classification
- human keypoints
- print*
- cross-entropy loss
- implicit rules
- geometric viewpoint
- fortran90
- cv
- parametric approach
- implicit rule
- feature cropping
- 내장함수
- computer vision
- GNN
- format이 없는 입출력문
- 산술연산
- FORTRAN
- L2 distance
- tensor core
- cs224w
- data-driven approach
- visual viewpoint
- object detection
- EECS 498-007/598-005
- algebraic viewpoint
- L1 distance
- Graph Neural Networks
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 9강. Hardware and Software (1) 본문
[EECS 498-007/598-005] 9강. Hardware and Software (1)
ydduri 2023. 2. 20. 11:251. Hardware
컴퓨터 본체 내부를 들여다보면, 큰 부피를 차지하고 있는 CPU와 GPU를 볼 수 있다. 실제로 이 둘은 그만큼 중요한 구성 요소이다.

NVIDIA와 AMD는 하드웨어계의 유명한 라이벌이지만, 딥러닝 분야에 있어서는 승자가 확실하다. 바로 NVIDIA다. AMD의 경우 딥러닝을 위한 범용 컴퓨팅(general-purpose computing)에 활용되는 software stack이 NVIDIA의 것만큼 발전하지 못했기 때문에 딥러닝을 할 때는 NVIDIA의 hardware가 보편적으로 사용된다. 딥러닝에서 GPU라 하면 사실상 NVIDIA GPU라고 보면 된다.
※ 이때 범용 컴퓨팅이란 가전제품 제어, 비행기 항로 제어 등 특수한 목적만을 수행하는 것이 아닌, 사무 처리, 계산 등 여러 업무를 모두 처리할 수 있음을 말하며, 오늘날 사용되는 대부분의 컴퓨터가 이에 해당한다.

FLOPs란 Floating point Operations Per Second의 약자로, 초당 얼마나 많은 부동 소수점 연산을 할 수 있는지를 나타낸다. 이는 하드웨어 성능을 수치로 나타낼 때 주로 사용되는 단위 중 하나이다. Giga는 10의 9제곱, 즉 10억을 의미하며, 따라서 1GigaFLOPs라 하면 컴퓨터가 1초동안 10억 자리의 부동소수점 연산을 할 수 있음을 뜻한다.
아래 그래프에서 파란색 점이 CPU, 주황색 점이 GPU인데, 시간이 지남에 따라 둘 다 비용 대비 성능이 좋아지지만, 특히 GPU가 2012년 부근에서 드라마틱하게 좋아지는 것을 볼 수 있다. 그중에서도 눈여겨봐야 할 AlexNet은 딥러닝 성능 향상의 돌파구를 제시한 모델인데, 이것이 GPU 기반에서 구동되었다.
이를 통해 딥러닝 계산에 CPU 대신 GPU를 사용하면 엄청난 비용 절감 효과가 있음을 알 수 있었다. 그래서 AlexNet을 기점으로 모델의 크기가 급격히 커질 수 있었고, 더 큰 데이터셋을 학습시킬 수 있게 되었다. 강연자는 이를 ‘Deep Learning Explosion’이라 표현했다.

앞서 CPU와 GPU가 컴퓨터 하드웨어의 중요한 구성 요소라고 소개했는데, 이 둘의 차이점을 알아보도록 하겠다. CPU는 우리말로 중앙처리장치, GPU는 그래픽 처리 장치라고 하는데, 둘 다 매우 중요한 컴퓨팅 엔진이지만, 그 역할은 서로 다르다. 이런 역할 차이는 아키텍처의 차이에서 기인한다.
※ 아키텍처 차이를 알아보기에 앞서 핵심 용어 정의를 하고 가보자면, 코어는 연산을 수행하는 핵심적인 부분이고, Clock speed는 초당 실행하는 사이클 수이다.
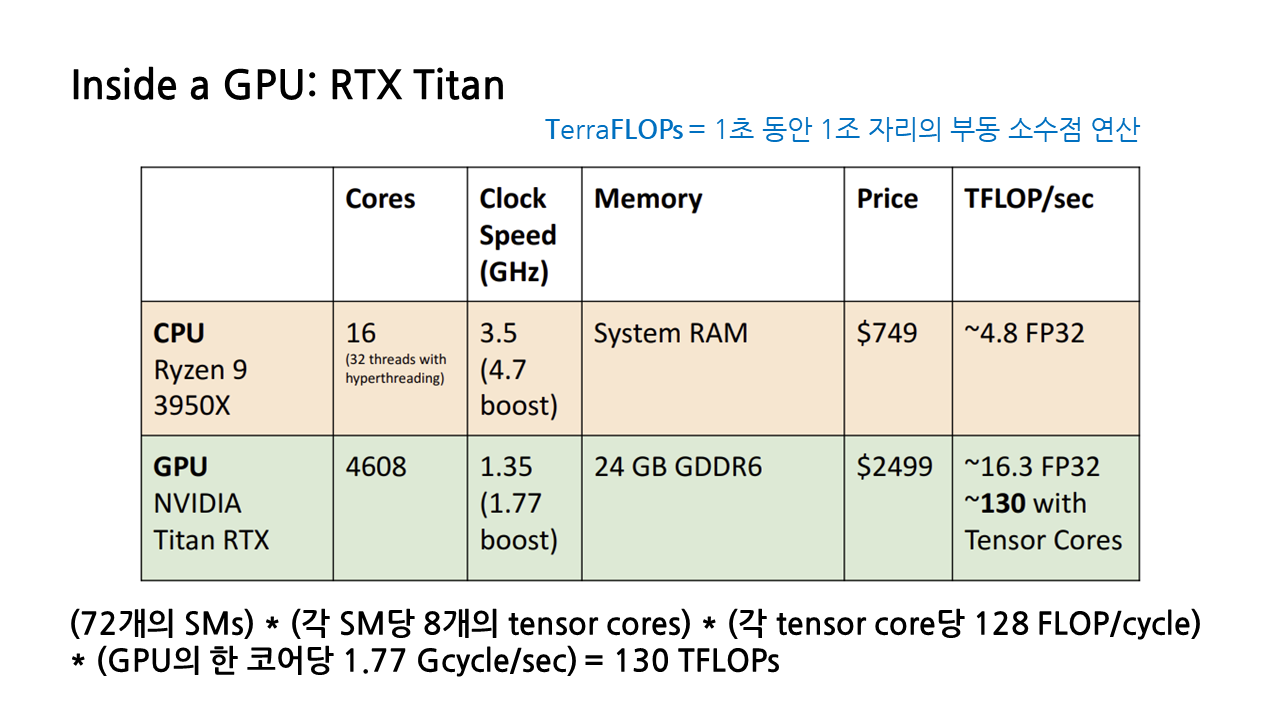
아래 표에서 볼 수 있다시피, CPU는 GPU에 비해 코어 수가 현저히 적다. 하지만 코어 당 clock speed가 크기 때문에 각각의 코어가 빠르고 강력하게 연산을 수행해낼 수 있다. GPU는 코어 당 clock speed는 상대적으로 작아 코어 낱개로만 봤을 때는 CPU 코어보다 성능이 현저히 낮지만, 코어의 수를 무지막지하게 늘림으로써 이를 해결한다. 따라서 CPU는 코어 당 성능이 중요한 연속적인 작업에서, GPU는 여러 코어를 사용하는 것이 가능한 병렬적인 작업에서 강점을 발휘한다.

1) Inside a GPU
이제 GPU 내부를 파고들어가 보겠다. GPU는 그 자체로 하나의 작은 컴퓨터라고 볼 수 있다. 총 24GB의 자체적인 메모리 모듈을 가지고 있고, 컴퓨팅에 필요한 모든 것을 품고 있는 GPU의 심장, 프로세서도 존재한다.

다시 프로세서의 내부를 들여다보면, 아래 그림과 같이 엄청난 수의 computing elements가 그리드 형태로 나열된 모습을 볼 수 있다. 이때 빨간색 박스로 표시된 부분이 NVIDIA GPU의 core computing elements의 단위라 할 수 있는 Streaming multiprocessor(이하 SMs)이다. RTX Titan의 경우 72개의 SMs로 구성되어 있다.

(1) FP32 Core
이번엔 각각의 SMs 내부를 보겠다. 작은 네모는 FP32 core라 불리는데, 32는 32비트, FP는 floating point, 즉 부동 소수점의 약자로, 이름처럼 부동 소수점 연산에 특화된 코어이다.
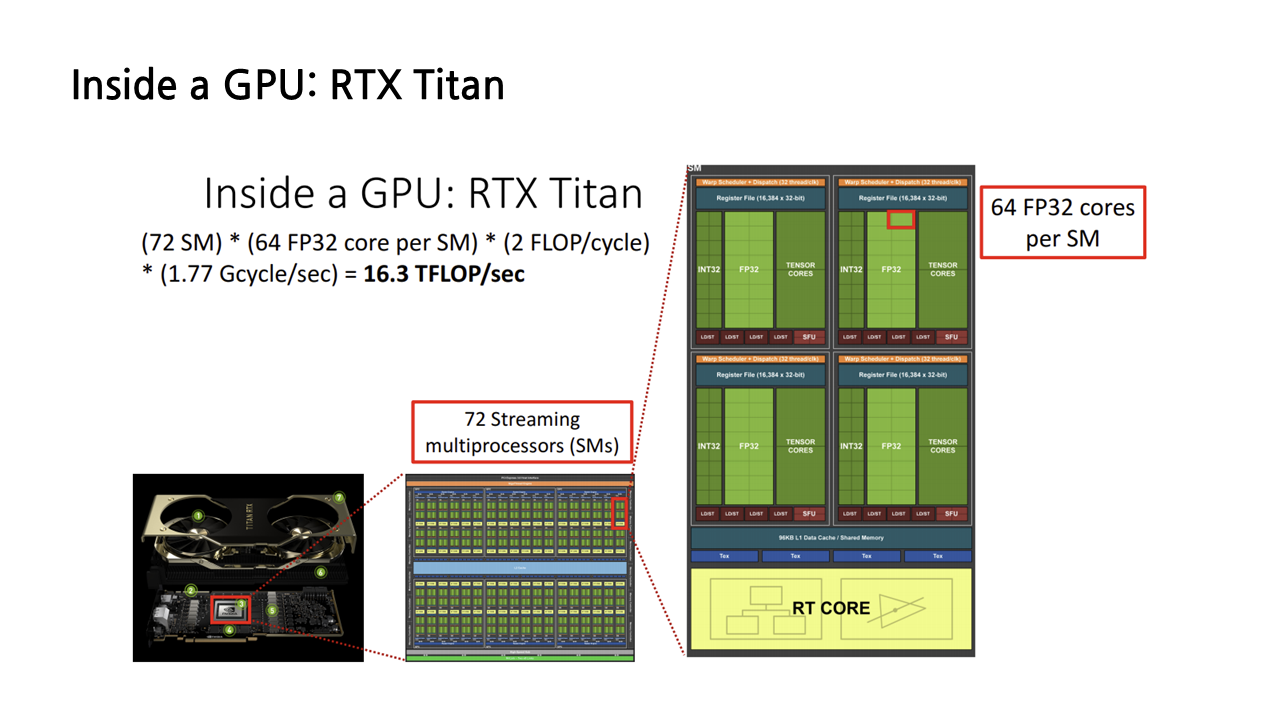
앞서 하드웨어의 성능을 나타내는 지표 중 하나로 초당 얼마나 많은 부동 소수점 연산을 할 수 있는지를 나타내는 FLOPs라는 단위를 소개했었는데, 이 지표를 결정하는 것이 바로 FP32 core의 개수이다. 실제로 앞서 표에서 NVIDIA Titan RTX GPU의 TFLOPs(테라플롭스)가 16.3 정도 된다고 나온 바 있는데, 이는 다음과 같은 방식으로 계산된 값이다.
이 GPU는 72개의 Streaming multiprocessors가 있고, 각각의 SMs는 64개의 FP32 core를 가지고 있는데, 각각의 FP32 core는 clock cycle당 2번의 부동 소수점 연산을 할 수 있으므로 이들을 모두 곱해준다. 여기에 GPU의 한 코어가 초당 실행하는 사이클 수인 1.77 Gcycle/sec까지 곱해주면 16.3 TFLOPs(테라플롭스)가 나오게 된다.

(2) Tensor Core
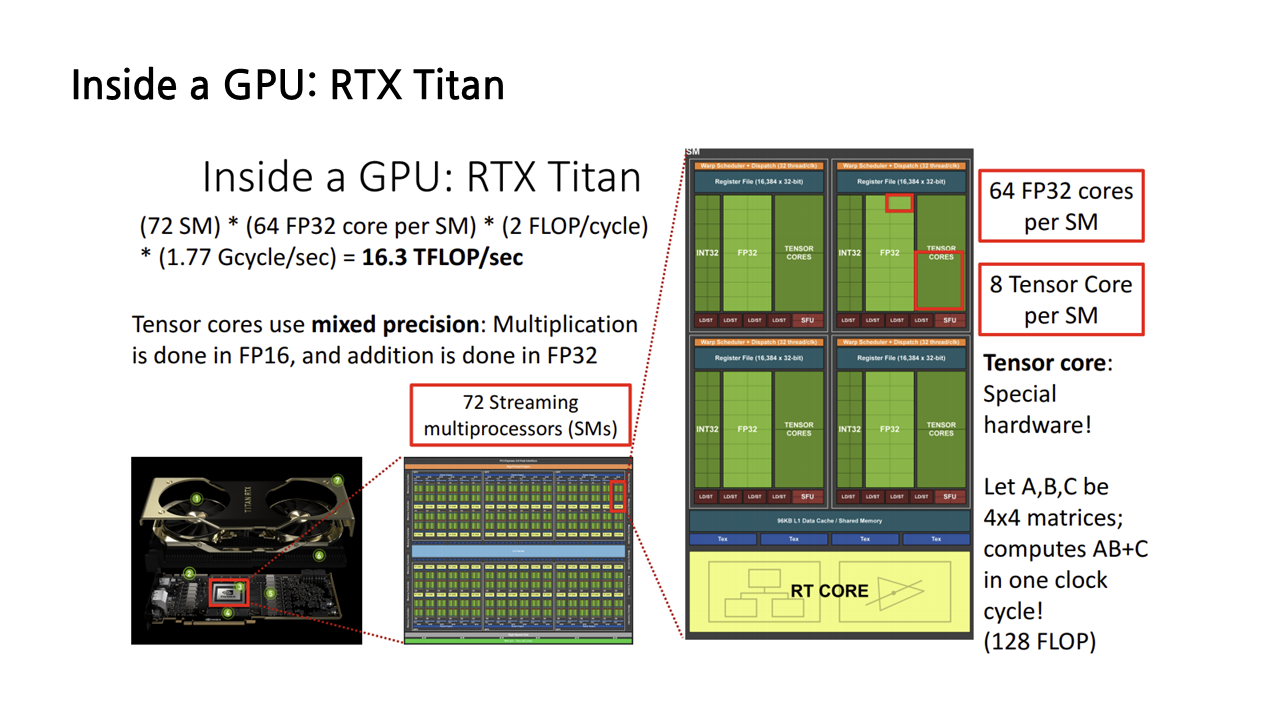
SMs를 구성하는 단위는 FP32 코어뿐만이 아니다. NVIDIA GPU의 특징적인 구성요소 중 하나는 바로 Tensor Core인데, 이것이 바로 NVIDIA GPU를 딥러닝 하드웨어 분야의 1인자로 만들어준 1등공신이라 볼 수 있다. 왜냐하면 Tensor core가 이름처럼 텐서 및 matrix 계산에 특화되어 있기 때문. 실제로 딥러닝에서 matrix 연산이 차지하는 비중은 어마어마하다. 당장 CNN의 convolution 연산만 봐도 그렇다.
Tensor core는 4*4 matrix의 곱과 합 연산을 한 사이클에 수행할 수 있는데, 이는 FLOP로 따지자면 한 clock cycle당 128번의 부동 소수점 연산을 할 수 있는 수준이다. 앞서 FP32 core의 성능이 2 FLOP/cycle임을 감안하면 어마어마한 성능인 셈.
그러나, 얻는 게 있으면 잃는 것도 있는 법. Tensor core는 어마어마한 속도와 성능의 대가로 정확도를 내주었다. FP32 core가 32비트까지의 숫자를 정확하게 다룰 수 있는 것에 비해, Tensor core의 정확도는 그의 절반인 16비트이다. 정확도를 어느 정도 포기한 대신 엄청난 속도와 성능을 얻은 것이다.
Tensor core를 고려해 TFLOPs를 아까와 같은 방식으로 다시 한번 계산해보면 130이라는 매우 높은 숫자가 나오게 된다.
Pytorch에서 tensor core를 활용하기 위해서는 세 가지 준비가 필요하다. Input data type이 16비트가 되도록 바꿔주고, 당연한 말이지만 tensor core를 가진 GPU를 준비하고, NVIDIA driver 등 적절한 소프트웨어를 설치해주면 pytorch에서 알아서 tensor core를 활용한다고 한다.

2) GPU가 딥러닝 강자인 이유
딥러닝에 있어 CPU에 비해 GPU의 성능이 좋은 이유는 딥러닝에서 큰 비중을 차지하는 ‘matrix multiplication’, 즉 행렬곱 때문이다. GPU가 matrix 연산에 특화된 Tensor core를 보유하고 있기 때문도 맞지만, Tensor core가 없는 GPU와 CPU를 비교하더라도 딥러닝에 있어 GPU의 성능이 더 좋은 편인데, 그 이유는 다음과 같다.
앞서 CPU와 GPU의 아키텍처 차이에 대해 설명하면서 CPU는 코어 당 성능이 중요한 연속적인 작업에, GPU는 여러 코어를 사용하는 것이 가능한 병렬적인 작업에 유리하다고 소개했는데, 행렬곱이 바로 병렬적인 작업의 대표적인 예시이다. 행렬곱 output의 원소들은 모두 독립적이기 때문에 병렬 계산을 수행해도 상관이 없습니다.

Question. 코어 당 성능으로 보면 CPU가 GPU에 비해 더 좋다고 했는데, 하드웨어의 성능을 나타내는 지표 중 하나인 TFLOPs는 왜 GPU가 더 좋은가?
이것은 해당 강의를 보면서 들었던 개인적인 궁금증인데, 이에 대해 깨달음을 얻은 내용을 정리하도록 하겠다. 코어 당 성능으로 보면 CPU가 GPU에 비해 더 좋다고 했는데, 그렇다면 하드웨어의 성능을 나타내는 지표인 TFLOPs도 CPU가 더 좋아야 할 것이 아닌가? 그런데 TFLOPs의 경우 GPU가 더 좋은 수치를 보여서 처음에는 의아하게 느껴졌다. 그런데 여기서 기억해야 할 점은 TFLOPs는 '부동 소수점 연산', 즉 단순 계산 성능과 관련된 지표라는 것이다.
간단한 곱셈 3000문제를 풀어야 하는 미션이 주어졌다고 생각해보자. 첫 번째 집단은 푸리에급 두뇌의 소유자 16명으로 구성되어 있고, 두 번째 집단은 대한민국 고등학생 4608명으로 이루어져 있다. 어느 집단이 더 빨리 해결할 수 있을까? 당연히 후자다. 간단한 곱셈을 해결하는 데는 푸리에급 수학 실력이 필요하지 않을뿐더러, 시간을 단축시키는 데는 머릿수로 승부하는 게 더 효과적이기 때문이다. 이때 전자가 CPU, 후자가 GPU라고 보면 된다. CPU는 물론 고성능의 코어를 보유하고 있지만, 부동소수점 연산처럼 간단한 계산에 있어서는 양으로 승부하는 GPU에 밀리는 편이다.
앞서 언급한 행렬곱의 경우에도 뜯어보면 간단한 곱셈과 덧셈으로 이루어지므로, 이러한 이유에서도 GPU가 CPU에 비해 행렬곱 및 딥러닝에 있어 강점을 발휘한다.

3) Programming GPUs
NVIDIA GPU를 활용하기 위해서는 ‘CUDA’라는 언어를 써야 한다. 이는 GPU를 직접 구동할 수 있도록 하는 코드를 쓰게 해주는 일종의 extension이다. 다만 NVIDIA에서 matrix multiplication, convolution, batch normalization 등 신경망을 사용하기 위한 여러 기능들에 대해 최적화된 루틴을 제공하고 있고, 이를 pytorch를 통해 사용할 수 있다. 그래서 CUDA를 통한 GPU programming 기술은 딥러닝에 있어 필수적이지는 않다.

4) Scaling up: Server
우리는 지금까지 1개의 GPU device 성능에 대해 이야기했다. 그런데 사람들은 생각했다. 1개만 써도 이렇게 좋은데 같이 쓰면 얼마나 좋을까? 그래서 오늘날에는 8개의 GPU를 모아 하나의 서버를 구성하고, 심지어는 이 서버를 다시 여러 개 연결해 데이터 센터를 구축해서 이용하기도 한다.

이때 딥러닝 하드웨어계의 신성이 등장한다. 바로 구글이 자신들의 특별한 하드웨어 device, TPU를 개발하여 나타난 것. 특히 TPU는 단독으로 사용하기보다 여러 개를 assemble하여 사용하는 경우가 많은데, 이를 ‘TPU pod’이라 한다. 단일 TPU와 TPU pod의 FLOPs를 비교했을 때 테라에서 페타로 아예 단위가 바뀐 것을 볼 수 있다.
구글은 cloud TPU v2의 경우 colab에서 무료 제공하고 있고, 그외 cloud TPU v3나 TPU pods의 경우 이용료를 받고 있다. 단점은 이용료가 좀 비싸다는 것… 강연자께서 언급한 또다른 단점 중 하나가 tensorflow에서만 사용 가능하다는 것이었는데, 현재는 pytorch에서도 사용 가능하게 되어 pytorch의 프레임워크 점유율이 급격히 증가하고 있는 현 시점에서 TPU의 활용도 또한 더욱 높아지지 않을까 생각한다.

다음 글에서는 Software 파트를 중점적으로 보도록 하겠다.
'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 16강. Detection and Segmentation(1) (0) | 2023.02.26 |
|---|---|
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 3강. Linear Classifier (1) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 2강. Image Classification (2) (0) | 2023.01.21 |



