
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- algebraic viewpoint
- image classification
- human keypoints
- object detection
- geometric viewpoint
- 산술연산
- Graph Neural Networks
- feature cropping
- print*
- multiclass SVM loss
- cv
- FORTRAN
- visual viewpoint
- L1 distance
- implicit rules
- implicit rule
- data-driven approach
- Semantic Gap
- cross-entropy loss
- gfortran
- L2 distance
- computer vision
- EECS 498-007/598-005
- 내장함수
- format이 없는 입출력문
- parametric approach
- GNN
- cs224w
- fortran90
- tensor core
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 2강. Image Classification (2) 본문
[EECS 498-007/598-005] 2강. Image Classification (2)
ydduri 2023. 1. 21. 20:411. Data-Driven Approach(데이터 중심 접근 방법)
- 이미지와 각 이미지에 해당하는 라벨에 대한 데이터셋을 모은다.
- Classifier(분류기)를 학습시키는 데에 머신러닝을 이용한다.
- 학습에 사용하지 않은 새로운 이미지들을 이용하여 classifier를 평가한다.
1) Image Classification Datasets
(1) MNIST

- 클래스: 10개(0부터 9까지 숫자)
- 크기: 28*28
- training images: 50k
- test images: 10k
설명이 필요 없을 정도로 유명한 데이터셋. 'Drosophila of computer vision'이라는 별칭도 가지고 있는데, 이는 생명과학 연구에서 단순한 생물 모델이 필요할 때 drosophila(초파리)를 사용한 데서 온 것이다. 주의할 점은, 그만큼 너무 간단한 데이터셋이라 좋은 성능이 나오므로 이 데이터셋의 경우 결과를 맹신하지 말고 아이디어의 검증 용도로만 사용해야 한다.
(2) CIFAR-10

- 클래스: 10개
- 크기: 32*32, 3 channels(RGB)
- training images: 50k
- test images: 10k
(3) CIFAR-100

- 클래스: 100개
- 크기: 32*32, 3 channels(RGB)
- training images: 50k
- test images: 10k
(4) ImageNet

- 클래스: 1,000개
- training images: ~1.3M
- validation images: 50k
- test images: 100k
Image Classification 계의 'Gold Standard', 기준이 되는 데이터셋이라고 보면 된다. 다양한 사이즈를 가지는 이미지들로 구성되어 있는데, 대개 256*256 크기로 resize하여 사용한다.
(5) MIT Places

- 클래스: 365개
- training images: ~8M
- validation images: 18.25k
- test images: 328.5k
풍경, 장면에 집중한 데이터셋이다. 이 또한 다양한 사이즈를 가지는 이미지들로 구성되어 있는데, 대개 256*256 크기로 resize하여 사용한다.
(6) Which Dataset Should I Choose?
ImageNet Dataset이 가장 품질이 좋다고 알려져 있긴 하나 그만큼 비용이 많이 발생하는 문제가 있다. 현재로서는 CIFAR-100이 중간치(middle ground)라고 생각하면 되지만, 데이터셋의 크기는 점점 증가하는 추세이다.
2) Nearest Neighbor
분류를 위한 머신러닝 알고리즘으로, 이를 구현하기 위해서는 train function과 predict function을 우선 구현해야 한다.
- train function: 모든 training data와 라벨을 기억한다
- predict function: 입력된 데이터를 training data와 비교함으로써 어떤 라벨을 가질지 예측한다
(1) Distance Metric to compare images
앞서 nearest neighbor에서, 입력된 데이터를 training data와 '비교'하여 어떤 라벨을 가질지 예측하는 함수가 필요하다고 했는데, 그에 해당하는 함수 중 하나인 'L1 distance'에 대해서 살펴보겠다.
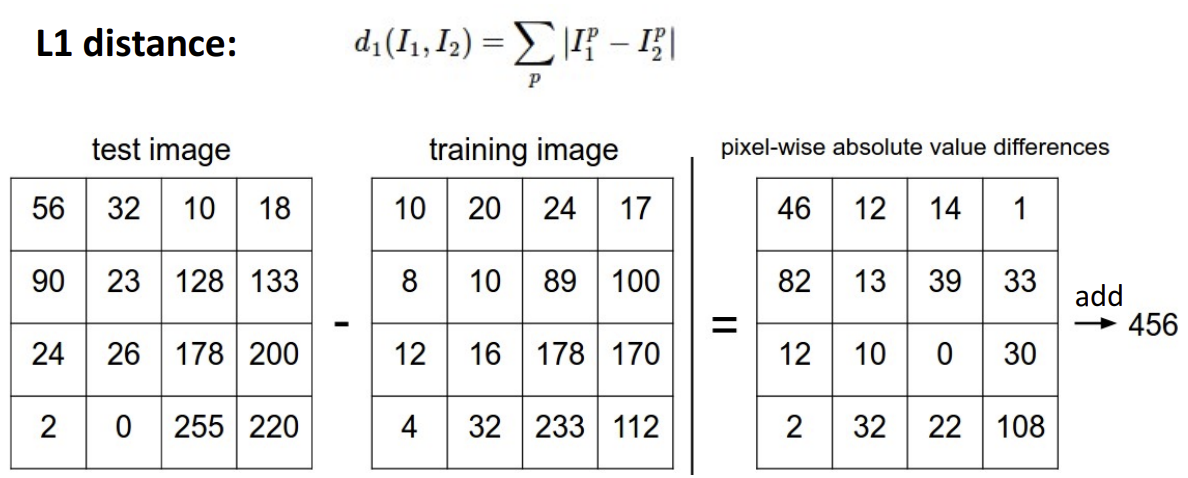
L1 distance의 산출 방식을 보면, test image에서 training image 픽셀 각각의 값을 빼서, 말그대로 '차이'를 구하는 것을 볼 수 있다. 각 픽셀끼리의 차를 구한 뒤 결과값을 합산하는 방식이다(이렇게 픽셀끼리의 산출 방식은 다음 글인 linear classifier를 보면 더욱 익숙해질 것이다!).
아래는 강의에서 소개해주신 Nearest Neighbor 코드에 약간의 설명을 덧붙인 것이다. 실제로 predict function 부분에서 L1 distance가 사용된 것을 볼 수 있다.
import numpy as np
class NearestNeibor :
def __init__(self) :
pass
### Memorize training data
def train(self , X , y) :
# X is N x D where each row is an examples. y is label which is 1-dim of size N
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self , X) :
# X is N x D where each row is an example we wish to predict label for
num_test = X.shape(0)
# let's make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
### For each test image(loop over all test rows)
### Find nearest training image & Return label of nearest image
for i in xrange(num_test)
# find the nearest training images to the i'th test image
# using the L1 distance (sum of absolute value difference)
distances = np.sum(np.abs(sel.Xtr - X[i,:]) , axis = 1)
# get the index with smallest distance
min_index = np.argmin(distances)
# predict the label of nearest example
Ypred[i] = self.ytr[min_index]
return Ypred해당 코드의 짜임새는 다음과 같다.
- 앞서 Nearest Neighbor가 train, predict function이 필요하다고 하였으므로 각각에 해당하는 함수를 포함하는 'NearestNeighbor'라는 클래스를 만든다.
- def __init__ 괄호 안의 'self'는 'NearestNeighbor'라는 클래스 자기 자신을 의미한다.
- train function을 정의한 부분에서 입력 받은 외부 변수 X, y(이때 X는 입력 이미지, y는 입력 이미지의 라벨이 될 것이다)를 각각 클래스 내에서 Xtr, ytr로 정의한다. tr은 train data임을 나타내기 위해 붙은 듯하다.
- predict function 정의부의 반복문에서 sel.Xtr(train data로 학습한 내용)과 X[i, :](test data로 들어온 내용) 사이의 거리를 측정함으로써 L1 distance를 적용한다.
- L1 distance(코드에서 distances로 표기)가 가장 작은 것이 train data와 test data 사이의 차이가 가장 작다는 의미이므로, 최솟값을 갖는 라벨을 결과(Ypred)로 출력한다.
(2) Nearest Neighbor의 문제점
시간 복잡도
Nearest Neighbor의 첫 번째 문제점은 '시간 복잡도' 측면에서 드러난다. train, predict function 각 함수의 시간 복잡도를 알아보자(시간 복잡도 개념은 자료구조에서 등장하는 것으로 알고 있는데, 언젠가 자료구조 시리즈도 다뤄보고 싶긴 하다! 잊고 지내실때 쯤 짜란 등장할지도..!).
- train function의 시간 복잡도 O(1): train function은 단순히 train data를 저장만 하기 때문
- predict function의 시간 복잡도 O(N): 모든 test data에 대해 train data와 비교를 수행해야 하므로 N개의 데이터가 주어졌을 때 시간복잡도는 O(N)
괄호 안에 있는 숫자가 커질수록 시간 복잡도가 증가한다, 즉 시간이 오래 걸린다고 보면 된다. N은 당연히 1보다는 훨씬 큰 숫자일 것이므로, train에 비해 predict에 많은 시간이 소요될 것임을 알 수 있다.
그런데 사실 우리에게 중요한 것은 predict 시간을 단축하는 것이다. train이야 얼마나 걸리든 크게 상관이 없지만(물론 빨리 된다면 좋을 것 같긴 하다), predict이 오래 걸린다면 결과가 빨리 나오길 기대하는 사용자 입장에서는 매우 답답할 것이다. 또한 해당 알고리즘이 항상 고성능의 기기에서 동작하리라는 보장이 없으므로, 다양한 성능 스펙트럼의 기기들에서 원활하게 작동하기 위해서는 predict에 걸리는 시간을 단축하는 게 필요하다.
그런데 Nearest Neighbor는 반대다. train에 비해 predict에 많은 시간이 소요된다. 이것이 Nearest Neighbor가 가지는 첫 번째 문제점이라 볼 수 있다.
Decision Boundaries
Nearest Neighbor의 두 번째 문제점은 'Decision Boundaries'를 만들 때 발생한다. 아래 그림에서 각각의 점이 train data이고, 점의 색깔은 해당 데이터의 라벨이라고 보면 된다. 배경색은 test data가 할당될 라벨에 해당한다.
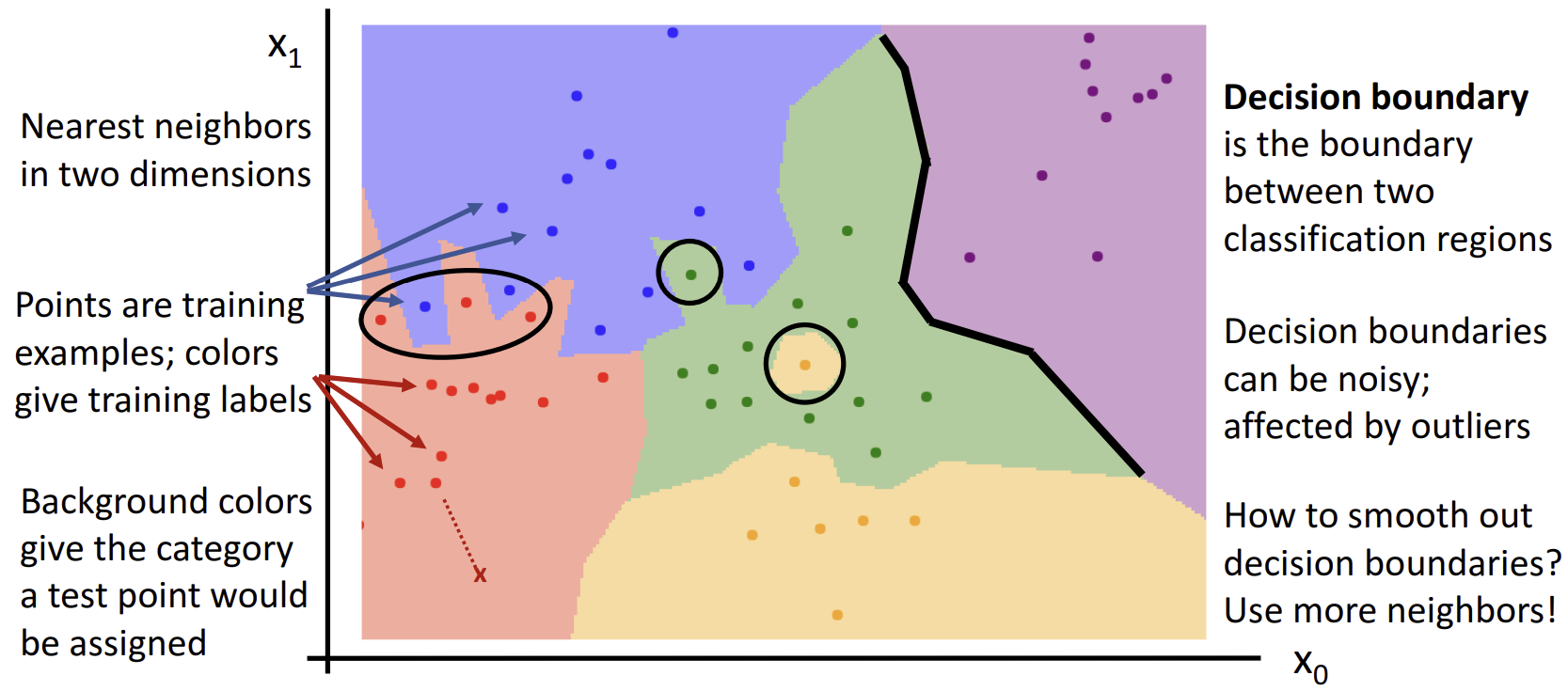
위 그림에서도 확인할 수 있는 Nearest Neighbor의 문제점이 두 개가 있다.
- 'Nearest', 즉 가장 가까운 데이터만을 이용해 boundary를 예측하기 때문에 이상치에 취약하다. 초록색 영역에 외따로이 들어가 있는 노란색 점이 이상치(outlier)인데, 이 경우 해당 영역을 노란색으로 예측하는 것이 아니라 초록색으로 예측하는 것이 '예측'이라는 목적 면에서는 더욱 타당하다.
- 마찬가지로 가장 가까운 데이터만을 이용한다는 특성 때문에, 영역의 경계면이 부드럽지가 못하다(빨간색-파란색 경계면을 보자). 이럴 경우 train data 하나하나에 과도하게 적합되어 버리는 '과적합'이 일어날 수 있다.
특히 두 번째 문제를 해결하고 경계선을 보다 스무스하게 만들기 위해 등장한 것이 'k-Nearest Neighbor'이다. 단 하나의 이웃만 고려하는 기존 방식에서 나아가, k개의 이웃을 고려하여 가장 많은 득표수를 가진 클래스로 예측하는 방식이다.
3) kNN(k Nearest Neighbor)
(1) k에 따른 변화
k는 인공지능 분야에서 보편적으로 사용하는 상수 문자이다(반복문에서 for i in range~ 이런 식으로 i, j를 주로 사용하는 것과 비슷한 맥락이라고 보면 된다). 앞서 Nearest Neighbor에서 발생한 문제들의 근본적인 원인이 '가장 가까운 데이터 하나'만 이용했기 때문이었으므로, 고려할 이웃 데이터의 수(k)를 조절함으로써 해당 문제를 해결해나가자는 아이디어이다.
실제로 아래 그림을 보면, k가 증가하니 경계면이 보다 스무스해진 것을 확인할 수 있다. 다만 경계 사이에 분류되지 않은 흰색 공백이 생기는 현상이 발생하는데, 이는 kNN이 해결해야 할 과제 중 하나로, 현재로서는 추론을 하거나 임의로 결정하여 채워나가야 한다.
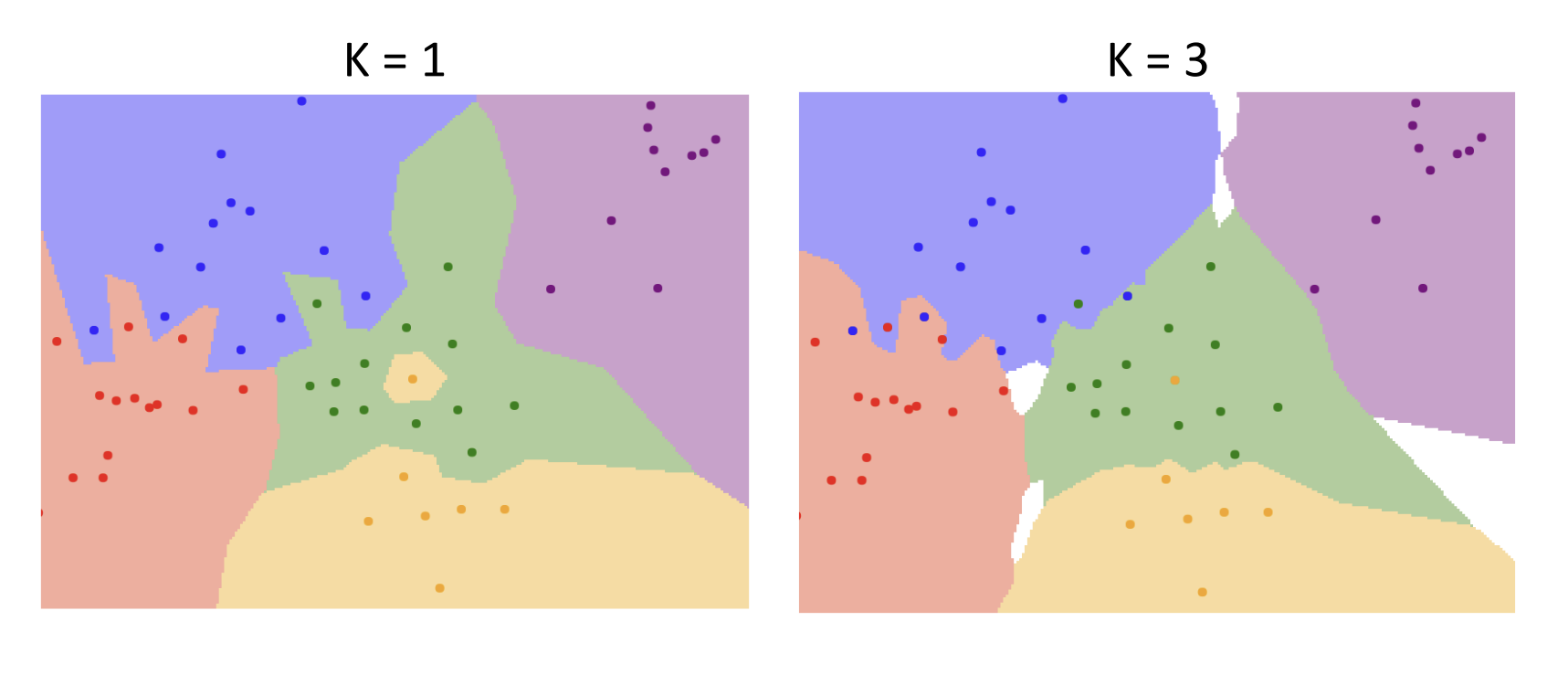
(2) Distance Metric(거리 척도)에 따른 변화
앞서 Nearest Neighbor 부분에서 등장한 L1 distance가 distance metric(거리 척도)의 일종이다. 또다른 대표적인 거리 척도로는 L2 distance가 있는데, 어떠한 거리 척도를 사용하냐에 따라 경계선의 모양에 약간의 차이가 발생한다.
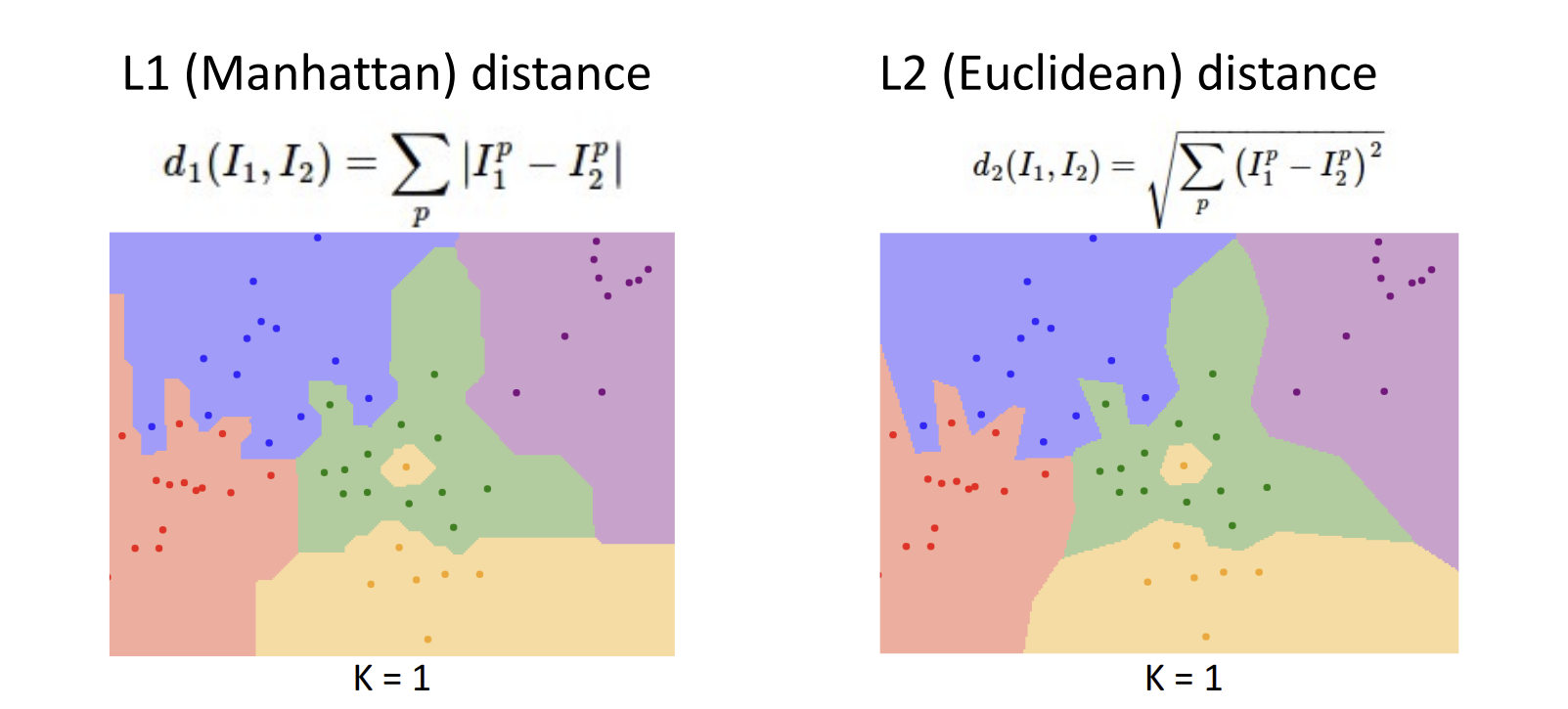
- L1 distance: 각각의 벡터 요소들이 개별적인 의미를 가지고 있을 때 사용
- L2 distance: 벡터 요소들의 의미를 모르거나, 의미가 별로 없을 때 사용
실제로 위 그림의 식을 보면 L1, L2 distance 모두 '거리' 개념이므로 계산 결과가 양수가 나와야 한다는 점은 같지만, 양수를 만들기 위해 사용한 방법이 다소 차이가 나는 것을 볼 수 있다. L1 distance는 차이에 절댓값을 취하는 방식이라 test data에서 train data를 뺀 값 자체를 보존할 수 있지만, L2 distance는 제곱->제곱근 순으로 값에 변형을 가하기 때문에 각각의 벡터 요소들이 개별적인 의미를 가지고 있을 때 이를 보존하기 위해 L1 distance를 사용하는 것을 권장하는 것이라고 이해했다.
아래 사이트에서 k값, distance metric의 변화에 따른 decision boundaries의 변화를 시각적으로 확인해볼 수 있다.
http://vision.stanford.edu/teaching/cs231n-demos/knn/
http://vision.stanford.edu/teaching/cs231n-demos/knn/
vision.stanford.edu
4) Hyperparameter
위에서 k값, distance metric 등이 변함에 따라 kNN에서 decision boundaries에 변화가 생기는 것을 확인할 수 있었다. k값, distance metric과 같이 학습에 영향을 미치면서, 우리가 조정할 수 있는 파라미터들을 '하이퍼파라미터(Hyperparameter)'라 한다. 하이퍼파라미터는 학습을 통해 선택하는 것이 아니라, 학습을 시작할 때 미리 결정하는 것이다.
(1) 첫 번째 아이디어. 원래의 데이터셋에 최적화된 하이퍼파라미터를 고르자!
문제점: 과적합의 우려가 있다. 일례로, kNN에서는 k=1일 때(그냥 nearest neighbor와 다를 게 없다)가 주어진 데이터셋(train data)에는 가장 잘 적합되는 상태인데, 이는 앞서 살펴봤던 것처럼 과적합을 일으킬 수 있다는 문제가 있다.

(2) 두 번째 아이디어. 데이터셋을 train, test data로 쪼개고, test data에 최적화된 하이퍼파라미터를 고르자!
문제점: 알고리즘이 새로운 데이터에 대해서 어떻게 동작할지 알 수 없고, test data에 최적화를 하더라도 정말 해당 test data에만 잘 맞는 하이퍼파라미터일 수도 있다.

(3) 세 번째 아이디어. 데이터셋을 train, validation, test data로 쪼개고 validation data를 이용해 하이퍼파라미터를 선정, test data를 이용해 하이퍼파라미터를 평가한다.
이것이 사실상 최선의 방법이다. test data는 단 한 번 사용할 수 있으므로(test data는 알고리즘이 '모르는', 즉 처음 보는 상태의 데이터여야 의미가 있으므로 한 번 사용한 test data는 test data로서의 기능을 잃는다고 보면 된다), 이것은 실전을 위해 남겨두고, validation data를 이용해서 하이퍼파라미터를 선정하는 방식이다. test data를 통해 실험한 결과를 토대로 새로운 데이터에 대한 성능을 예측할 수 있다.

(4) 네 번째 아이디어. cross validation(교차 검증)
아래 그림에서 초록색이 train, 노란색이 validation 데이터라고 보면 된다. 이런 식으로 데이터를 폴드로 쪼개고, 처음에 5번 폴드를 validation에 이용했다면 그다음은 4번, 그다음은 3번... 이렇게 train, validation 데이터를 섞어가며 '교차' 검증함으로써 최적의 하이퍼파라미터를 결정하는 방식이다. 딱 봐도 짐작되듯이 계산량이 많기 때문에 딥러닝과 같이 큰 모델을 학습시킬 때는 잘 사용하지 않고, 작은 데이터셋에만 적용한다.
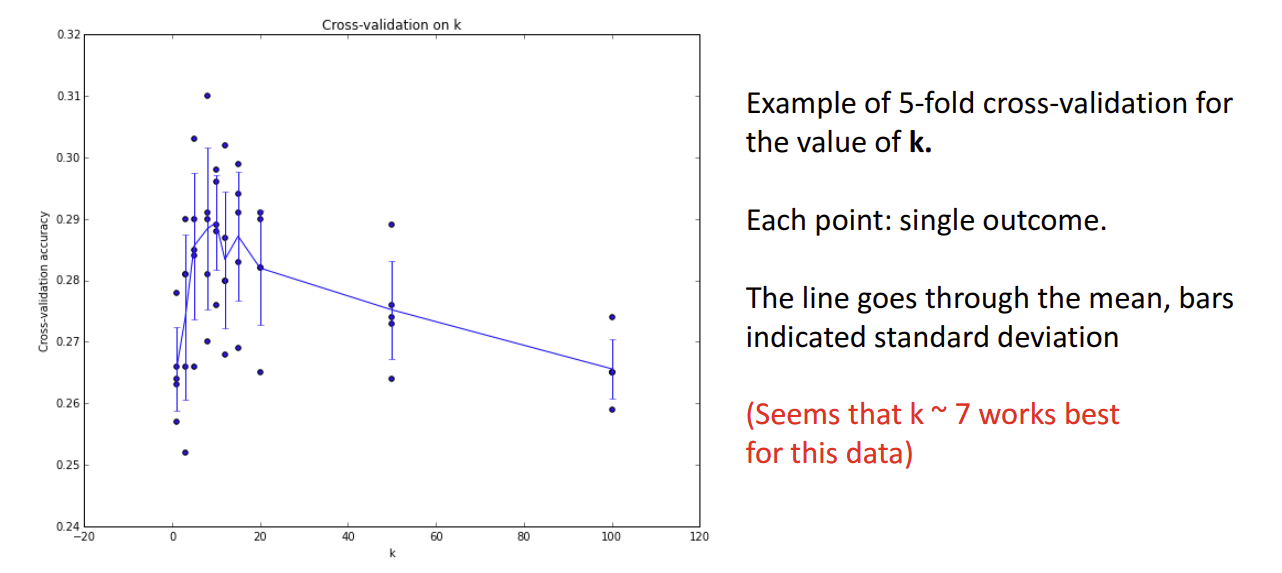
아래 그림은 k값을 결정하기 위해 위의 예시에서와 마찬가지로 5-fold cross validation을 수행한 결과를 나타낸 것이다.
- x축은 k의 수
- y축은 cross validation accuracy(교차 검증 정확도)
이때 각각의 점은 kNN을 한 번 돌릴 때마다 산출되는 outcome(Ypred)이다. 꺾은선 그래프처럼 표시되는 실선은 평균을 이은 것이고, y축 방향으로 위아래로 뻗은 선은 표준편차를 의미한다.
결과 그래프를 봤을 때, k = 7즈음일 때, cross validation accuracy가 가장 높은 것으로 보아 이 데이터에는 k = 7이 가장 적합함을 알 수 있다.
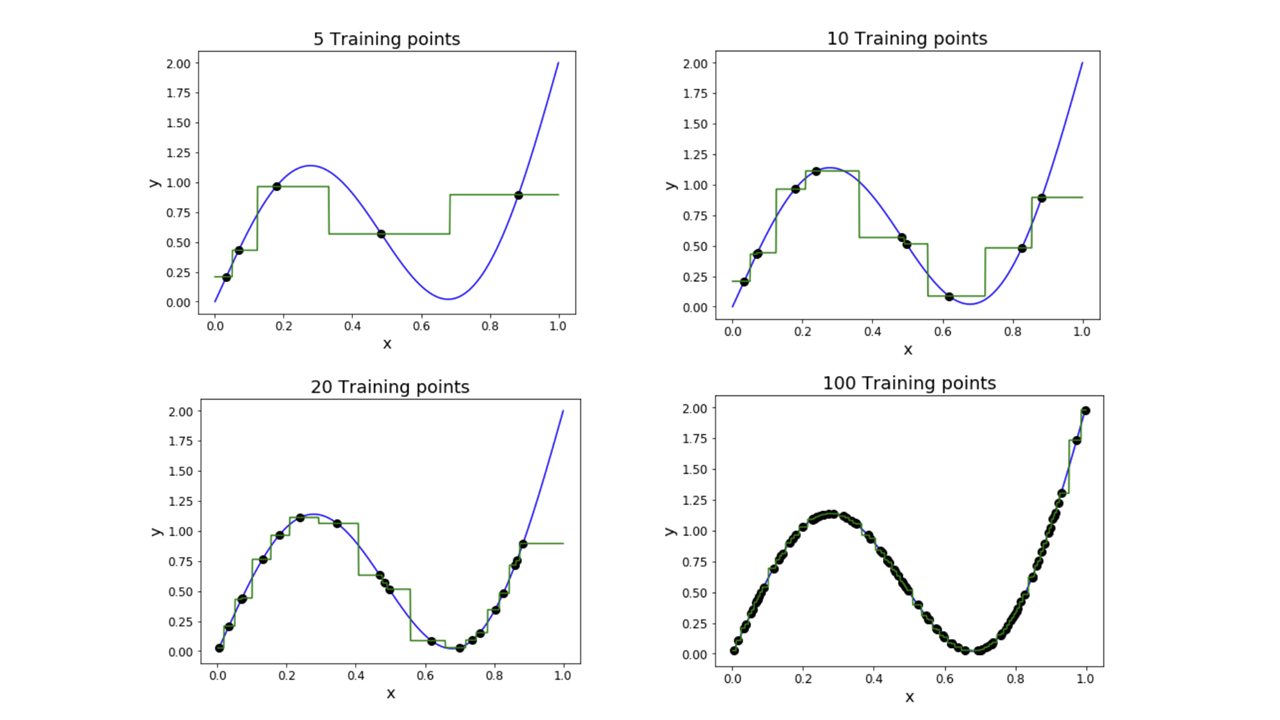
5) kNN의 특징: Universal Approximation
만일 train data의 개수가 무한대로 간다면, nearest neighbor는 어떤 함수든 나타낼 수 있다는 특징이다(어떤 함수든~이라고 쓰긴 했지만 사실 이걸 적용하려면 여러 조건을 우선적으로 만족시켜야 한다. 특정 도메인에서 연속이어야 한다거나, train point의 간격에 대한 가정이 필요하다거나 등등...).
아래 그림에서 파란색 실선은 true function(정답), 초록색 실선은 nearest neighbor function(nearest neighbor 알고리즘이 예측한 함수), 검은색 점은 training point(train data 각각의 값)이다. 실제로 training point가 늘어나면 늘어날수록 nearest neighbor function이 true function에 가까워지는 것을 볼 수 있다.
5) kNN의 문제점
(1) 차원의 저주
차원이 늘어남에 따라 공간을 균일하게 메우기 위해 필요한 training point의 개수가 기하급수적으로 증가한다. image classification에서 보편적으로 사용하는 CIFAR 데이터셋의 이미지를 분류한다고 생각해보자. 해당 데이터셋의 이미지 크기는 32*32이므로, 해당 공간을 균일하게 메워 균등한 학습이 이루어지도록 하려면 2의 32*32제곱 만큼의 training point가 필요하게 된다. image classification에서 kNN 알고리즘을 적용하는 것은 사실상 불가능하다는 뜻이다.

(2) distance metric은 이미지에 적용하기에 부적절하다
kNN을 image classification에 잘 사용하지 않는 첫 번째 이유는 2-(2) Nearest Neighbor의 문제점에서 살펴본 것처럼 test하는 데 시간이 매우 오래 걸리기 때문이었고, 두 번째 이유는 '차원의 저주'였다. 세 번째 이유는 kNN에서 predict function에 적용되는 distance metric이 이미지 분류에는 부적절하다는 데 있다. 아래 예시를 보자.

우리가 보기에는 다 다른 이미지들이지만, 위 네 이미지의 L2 distance는 서로 같다. 즉, L2 distance로는 네 이미지의 차이를 잡아낼 수 없다는 뜻이다(Boxed 이미지가 좀 무서웠는데 마인크래프트를 떠올리니까 나아졌다..).
Computer Vision 강의인데 정작 이미지 분류에는 써먹지도 못하는 알고리즘들을 왜 이리 열심히 공부했나,, 허탈하게 느껴질 수도 있을 것이다. 하지만 이런 기본적인 알고리즘을 통해 hyperparameter, train/validation/test data 등 앞으로 컴퓨터 비전뿐만이 아니라 인공지능을 공부할 때 꼭 필요한 핵심적인 개념들을 이해하는 것은 무척 중요한 일이다. 다음 글에서는 오늘 공부한 지식을 토대로 진정한 이미지 분류가 가능한 단계로 나아갈 수 있으니 기대하시라! 그럼 2강 내용은 여기서 마무리하도록 하겠다.
'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
|---|---|
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 3강. Linear Classifier (1) (0) | 2023.01.21 |
| [EECS 498-007/598-005] 2강. Image Classification (1) (1) | 2023.01.21 |



