
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- feature cropping
- GNN
- cross-entropy loss
- human keypoints
- cs224w
- EECS 498-007/598-005
- visual viewpoint
- Semantic Gap
- L1 distance
- gfortran
- fortran90
- format이 없는 입출력문
- print*
- multiclass SVM loss
- 내장함수
- tensor core
- computer vision
- Graph Neural Networks
- implicit rules
- L2 distance
- parametric approach
- object detection
- algebraic viewpoint
- geometric viewpoint
- implicit rule
- FORTRAN
- cv
- data-driven approach
- 산술연산
- image classification
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 16강. Detection and Segmentation(1) 본문
[EECS 498-007/598-005] 16강. Detection and Segmentation(1)
ydduri 2023. 2. 26. 21:351. Detection: R-CNN 변천사
먼저 Detection 파트부터 살펴보겠다. 사실 여기는 바로 전 강의의 후반부와 겹치는 부분인데, 지난 강의 끝나고 학생들의 질문이 폭주해서 보다 명확한 이해를 위해 강연자께서 더 자세히 설명해주신 내용이다(이 파트 내용이 너무 어려워서 이해하고 정리하는 데 애를 많이 먹었는데, 미시간대 학생들도 그렇게 느꼈다고 하니 조금 위안이 되는 것 같다…ㅎㅎ).
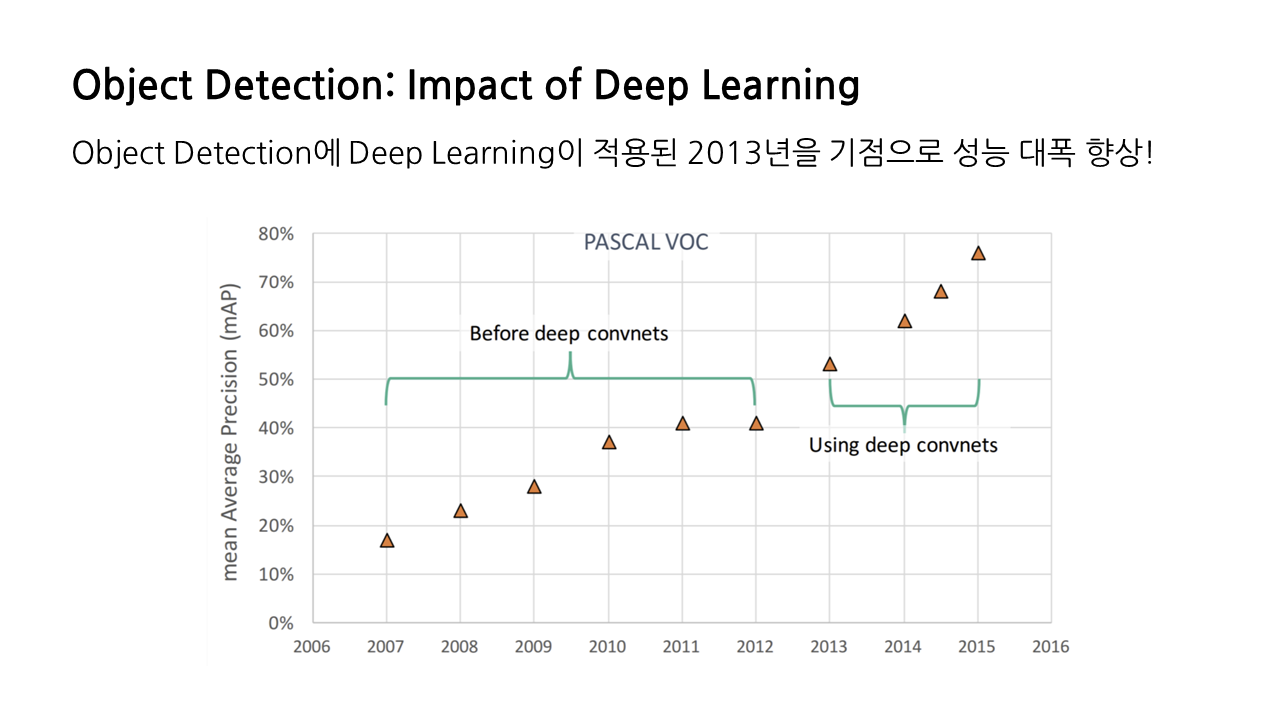
본격적인 시작에 앞서 그래프를 하나 보도록 하자. 이것은 시간이 흐름에 따라 Object Detection의 정확도가 어떻게 변화하는지 나타내는 그래프이다. 2013년을 기점으로 정확도가 대폭 향상하는데, 바로 이때가 ‘딥러닝’이 적용된 시점이다. 그래프가 2015년에서 멈춘 것은 성능 향상이 더 이루어지지 않은 것이 아니라, 모델이 발전함에 따라 이 그래프에서 성능 측정의 기준이 된 데이터셋인 'PASCAL VOC' 정도는 간단하게 처리하는 지경에 이르러 이제는 더 어려운 데이터셋에 도전하고 있기 때문이다.
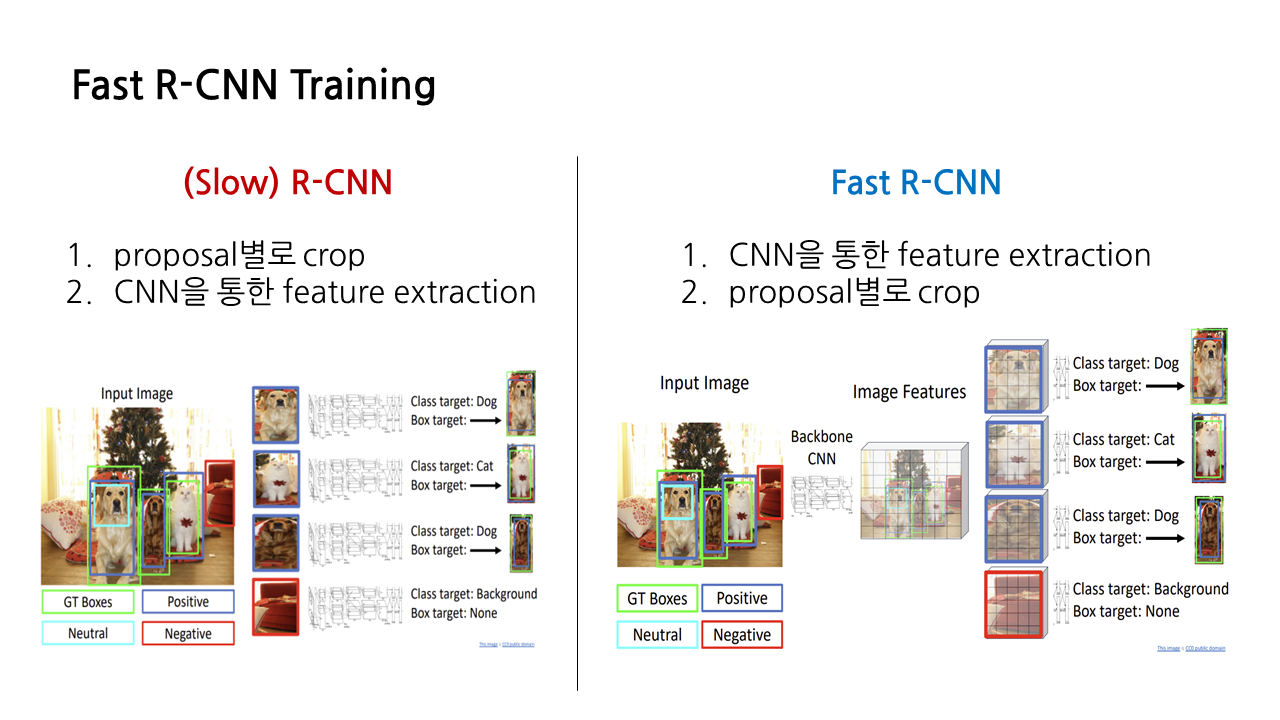
1) 'Slow' R-CNN Training
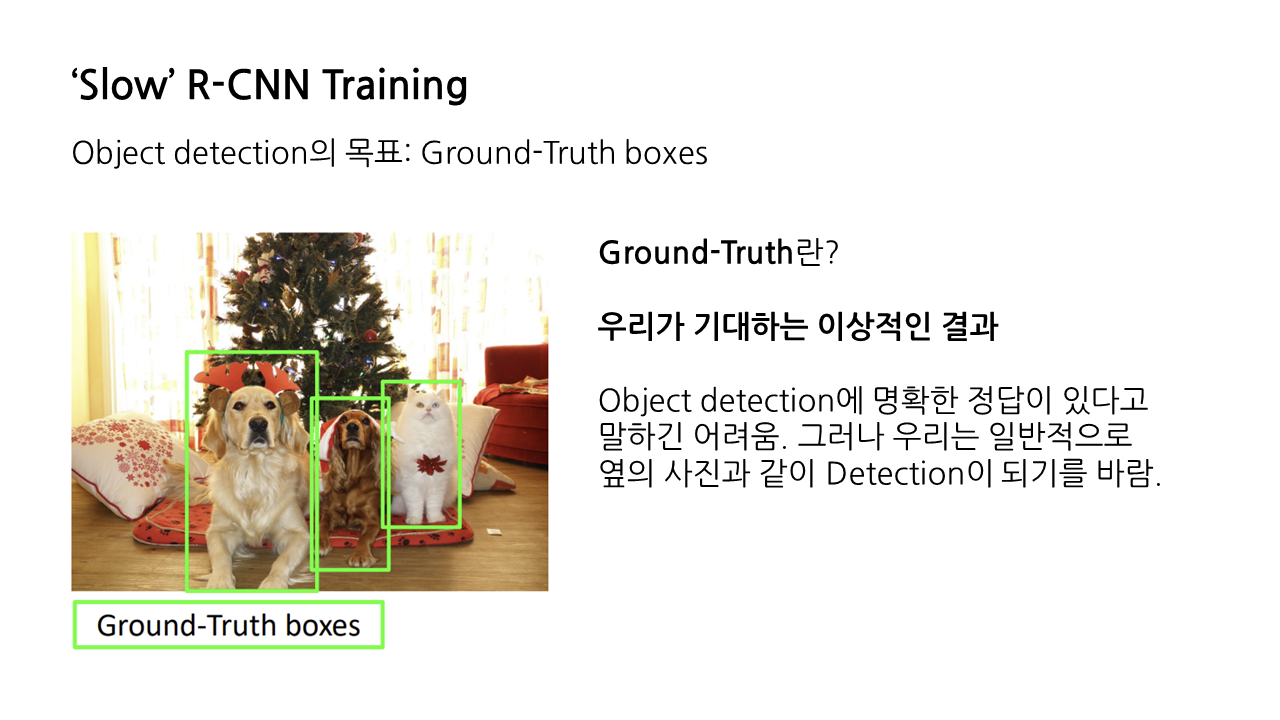
지난 강의 내용을 이어가서, object detection의 가장 토대가 되는 모델이라 할 수 있는 R-CNN을 살펴보겠다. object detection의 목표는 ‘ground-truth’ boxes를 찾는 것이라고 할 수 있다. 이때 ground-truth(이하 GT)란 우리가 기대하는 이상적인 결과를 의미한다.
object detection에 명확한 정답이 있다고 말하긴 어렵다. 그러나 우리는 아래와 같은 input image가 주어졌을 때 일반적으로 이런 식으로 detection이 되기를 바라므로, 해당 박스가 GT라고 볼 수 있다.
R-CNN은 object detection을 수행하기 위해, 우선은 object가 있을 것 같다 싶은 부분을 모두 잡아내어 ‘region proposal’을 생성한다. 그 종류는 GT와 얼마나 맞아떨어지냐에 따라 positive, negative, neutral의 크게 세 가지로 구분할 수 있다.
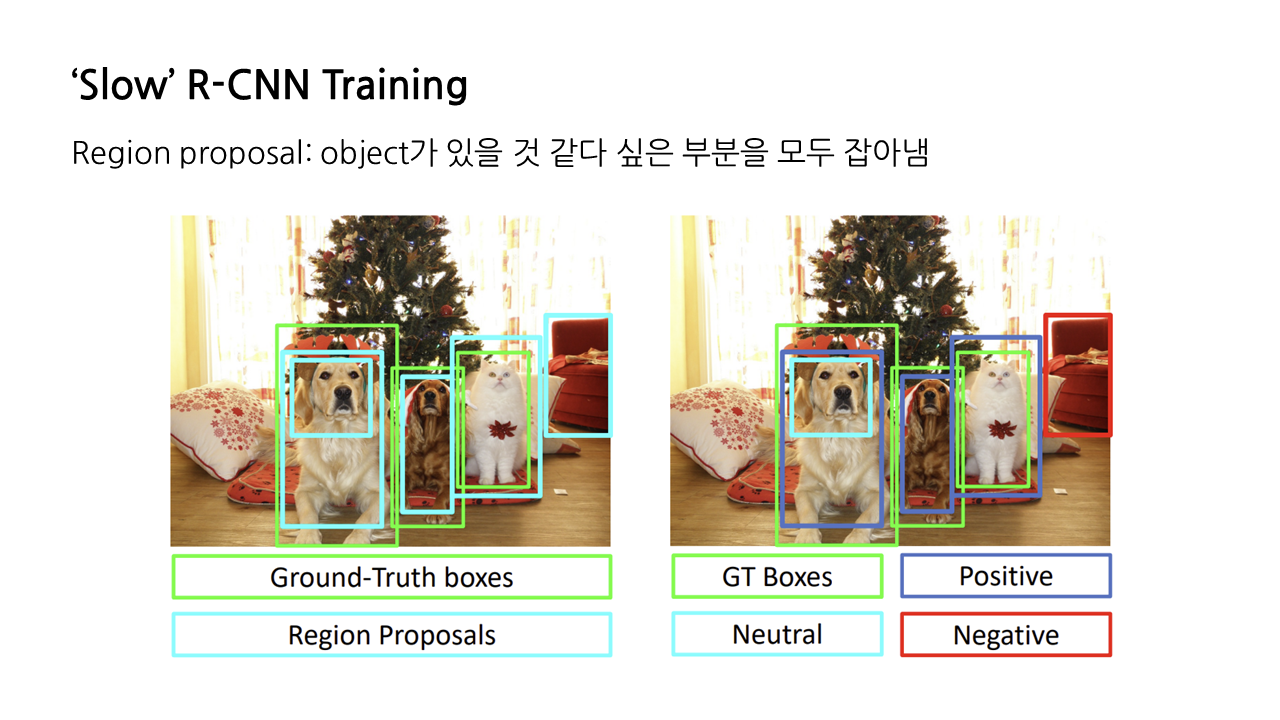
- positive: GT와 겹치는 부분이 많은 region proposal
- negative: positive와 반대, 특히 GT와의 IoU가 0.3보다 작은 region proposal
- neutral: GT의 일부기 때문에 negative는 아니지만 positive가 되기에는 부족한 region proposal
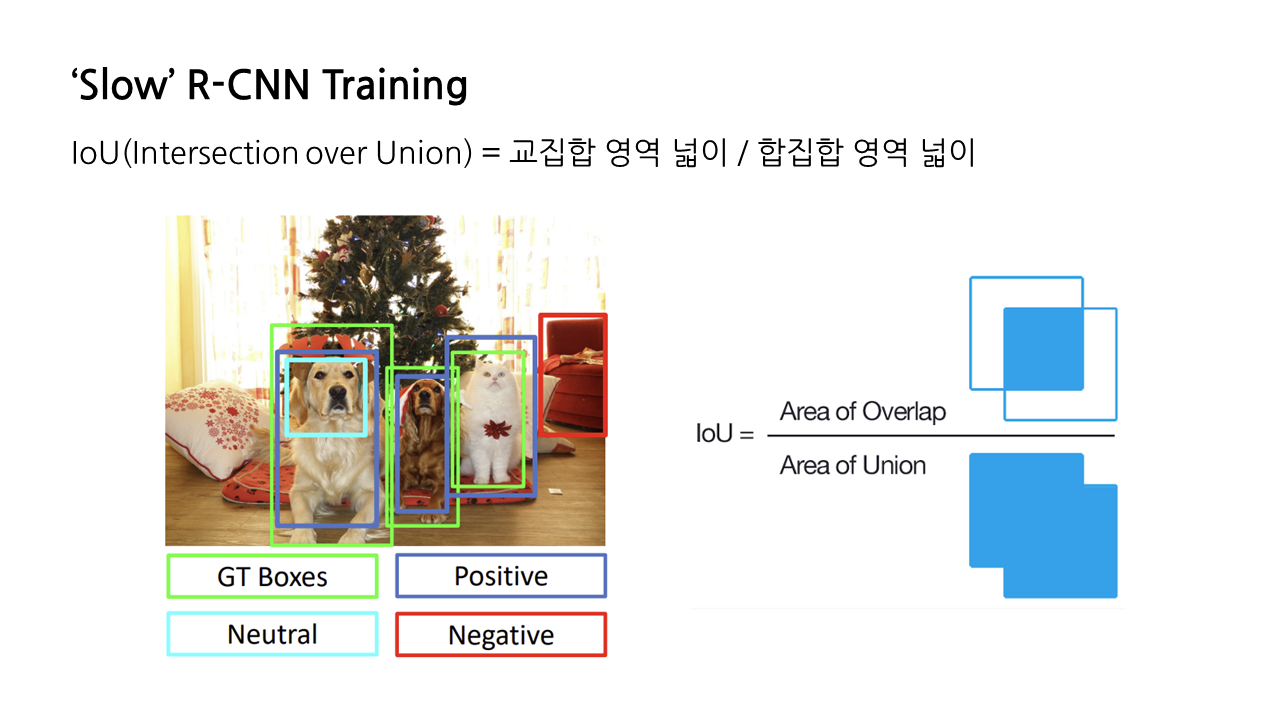
※ IoU(Intersection over Union): 합집합 영역 넓이에 대한 교집합 영역 넓이비를 나타내는 것으로, 이것이 클수록 GT Boxes와 겹치는 부분이 크다는 것을 의미
보통 R-CNN을 학습시킬 때 neutral은 제외하는데, positive도 아니고 negative도 아니라는 특성 때문에 혼돈을 줄 수 있기 때문이다. 그러고 positive와 negative를 구분할 수 있도록 만든다.
netural을 제외한 뒤, positive, negative proposal에 해당하는 부분을 잘라내어 224*224 등 특정 크기로 resize를 한다. 이렇게 잘라내고 나면 이것은 ‘image classification’ task와 유사해진다. 잘린 이미지는 각각 CNN을 통과하게 되는데, 이를 통해 해당 이미지의 class target을 예측하고, regression transform을 통해 box target을 알아내는 것이다.
positive proposal의 경우 class target은 개인지, 고양이인지 등을 의미하고, box target은 해당 positive proposal에 매칭되는 GT boxes를 의미한다(이때 box target은 bounding box라고도 불리는데, 둘 다 많이 쓰이는 용어니 알아두면 좋을 것 같다). negative proposal의 경우 class target은 ‘background’로 출력되게 되고, 이에 해당하는 box target은 없다.
다만 이 방식은 몇 가지 단점을 가지고 있는데, 첫 번째는 loss 계산이 복잡하다는 점이다. 앞서 언급했다시피 이 방식에서 각 CNN은 class target, box target이라는 두 가지 결과를 산출한다. 이는 곧 loss 또한 classification loss, regression loss라는 두 가지 종류로 나뉜다는 걸 의미한다.
classification의 경우 negative proposal 또한 ‘background’라는 라벨로 분류가 되기 때문에 classification loss는 모든 proposal에 대해 존재하지만, regression transform의 경우 negative proposal은 아예 결과를 낼 수 없기 때문에 regression loss는 일부 proposal에 대해서만 계산이 가능하고, 이런 차이 때문에 loss 계산이 복잡해지는 편이다.
또다른 단점은 제목처럼 느리다는 것이다. 모든 proposal이 각각의 CNN을 통과하는 방식이라 시간이 오래 걸리는데, 그래서 속도 향상을 위해 등장한 방식이 바로 fast R-CNN이다.

2) Fast R-CNN
R-CNN과 fast R-CNN은 다 비슷한데 딱 하나의 차이점만 가지고 있다. 바로 crop과 feature extraction의 순서다. 앞서 본 R-CNN은 우선 proposal별로 이미지를 crop한 뒤 각각의 proposal들이 CNN을 통과하며 feature extraction이 진행되었다. 반면 fast R-CNN은 crop을 먼저 하지 않고, 원본 이미지에 대해 CNN을 적용하여 feature extraction을 우선 진행한다. Crop은 그 다음이다. 이렇게 순서를 바꿈으로써 약간의 속도 향상 효과를 볼 수 있다는 장점이 있다.
3) Faster R-CNN
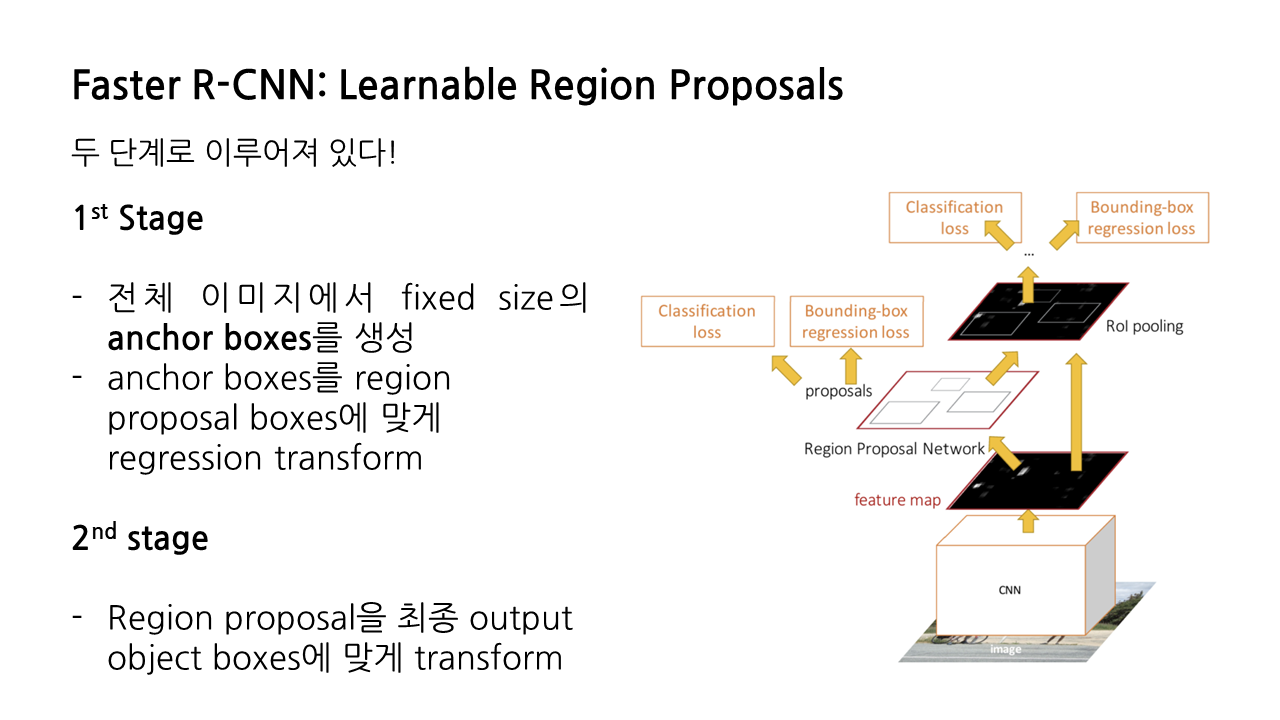
그런데 fast R-CNN 또한 fast라고는 하지만 region proposal을 구하는 과정에서 계산 병목 현상이 발생한다는 문제가 있어 속도 향상에 한계가 있었기 때문에, 사람들은 더 빠른 R-CNN을 고민하기 시작했고 그렇게 Faster R-CNN이 탄생했다.
faster R-CNN은 크게 두 단계로 이루어진다. 첫 번째 단계에서는 전체 이미지에서 fixed size의 anchor boxes를 생성하고, regression transform을 통해 이를 region proposal boxes에 맞게 조정한다. 두 번째 단계에서는 region proposal을 최종 output object boxes에 맞게 transform한다. 이제 각 단계를 더 자세히 보도록 하겠다.
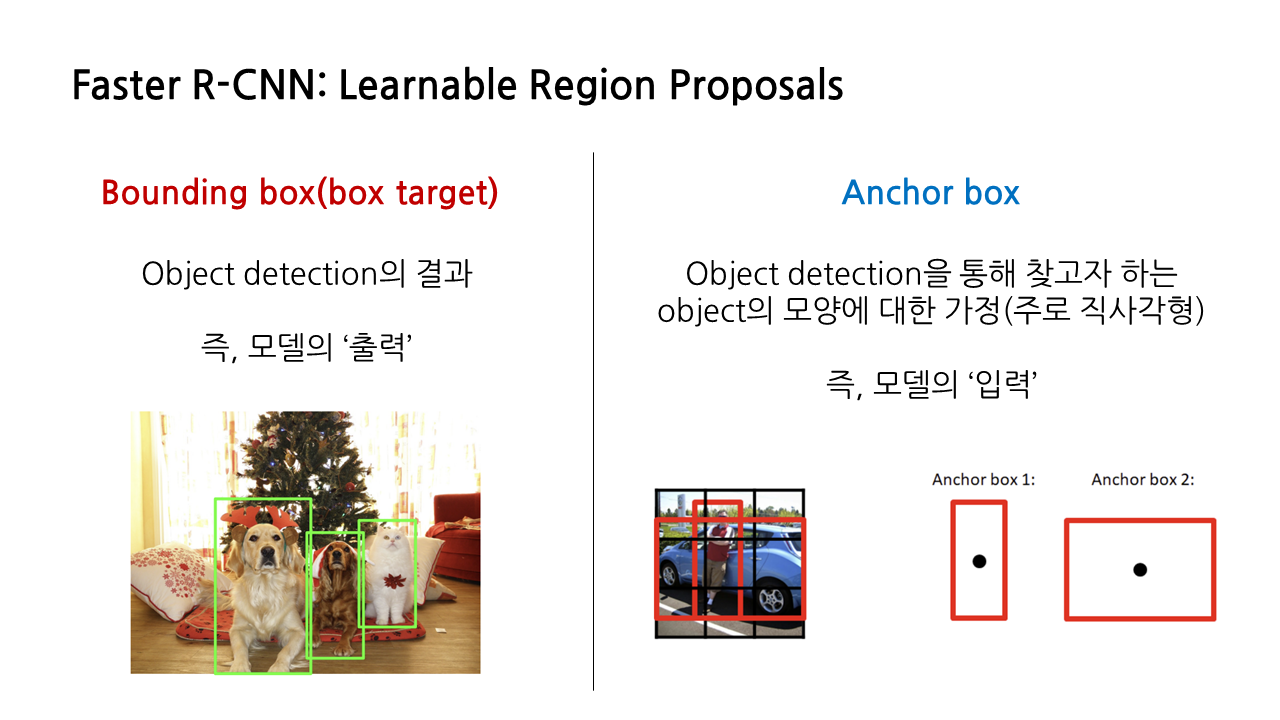
이때 anchor boxes라는 새로운 개념이 등장한다. anchor box 또한 아래 그림과 같이 직사각형 박스 형태로 표시하는 경우가 많아서 앞서 봤던 ‘bounding box’, 다른 말로는 ‘box target’과 헷갈릴 수도 있는데, 둘은 다른 개념이다. 앞서 본 bounding box는 object detection의 결과기 때문의 모델의 ‘출력’이라 볼 수 있고, 지금 등장하는 anchor box는 object detection을 통해 찾고자 하는 object의 모양에 대한 가정으로, 모델의 ‘입력’이라 볼 수 있다.
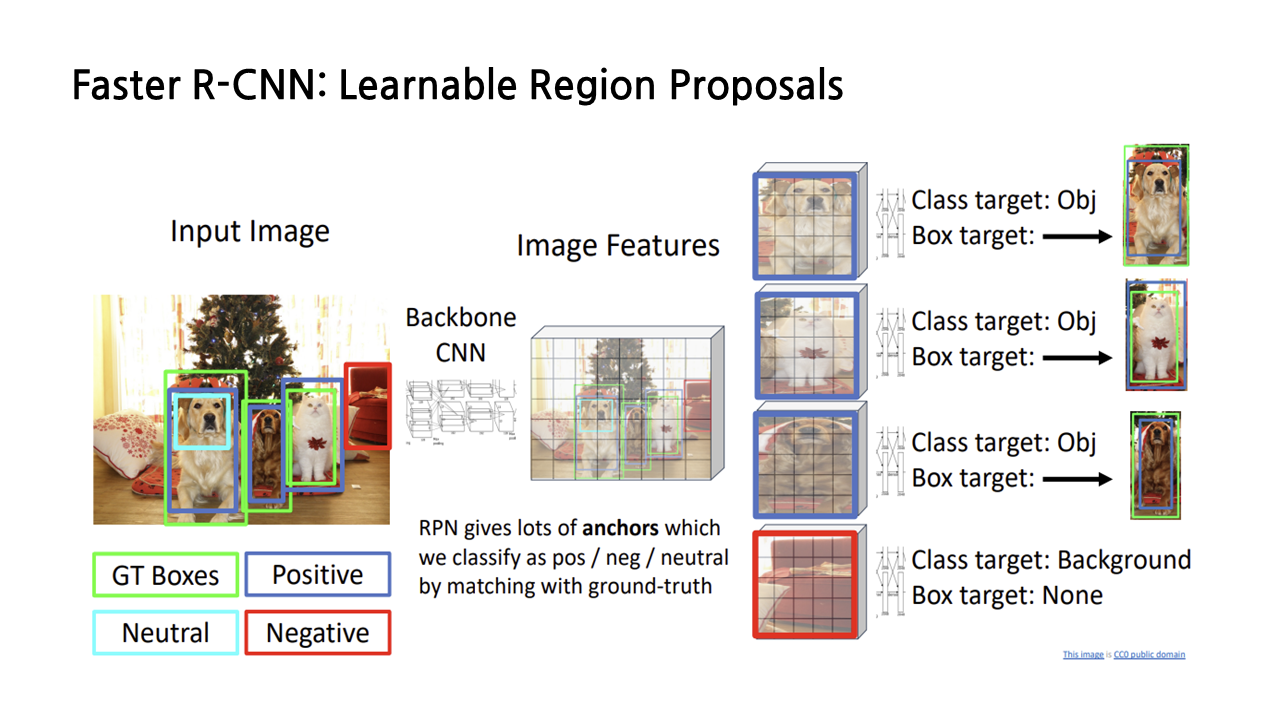
faster R-CNN의 전체적인 과정은 앞서 살펴본 R-CNN이나 fast R-CNN과 유사하다. 차이점이라면 이번엔 selective search 알고리즘을 통해 생성되는 region proposal이 아니라, ‘anchor box’에 대해서 positive, negative, neutral을 구분한다는 것이다. anchor box는 그 사이즈를 하이퍼파라미터로서 우리가 설정할 수 있기 때문에, 우리가 원하는 대로 지정이 가능하다.
이렇게 첫 번째 단계에서 anchor box를 활용한다는 점을 제외하면, 두 번째 단계에서 region proposal을 GT Box에 대응시키고, class target과 box target을 산출하는 과정은 동일하다.
2. Detection: Feature Cropping
이제 feature crop에 대해 살펴보겠다. 지난 강의에서 feature들을 cropping 하는 방법으로 ‘RoI Pool’를 소개했는데, RoI Pool을 수행하는 이유는 cropping operation의 결과로 산출되는 feature map을 network의 마지막 단계인 fully connected layer에 집어넣기 위해서는 일정한 크기를 가지고 있어야 하기 때문이다.
그런데 해당 방법에는 크게 두 가지 문제가 있다. 그중 첫 번째는 snapping에 의해 feature들이 사실은 잘못 정렬되어 있다는 점이다. 이때 snap은 input image를 feature map의 grid cell에 맞게 조정하는 과정이라고 보면 된다. snap은 region proposal을 feature map의 grid cell에 딱 맞게 만들어줌으로써 결과적으로 우리가 원하는 크기, 즉 CNN 모델의 FC layer에 맞는 크기로 변형할 수 있도록 해준다. 그런데 이렇게 gird cell에 맞게 위치를 조정하는 과정에서 원래의 GT와는 약간 맞지 않게 되어버린다는 문제가 생긴다. 이것이 바로 RoI Pool의 첫 번째 문제다.
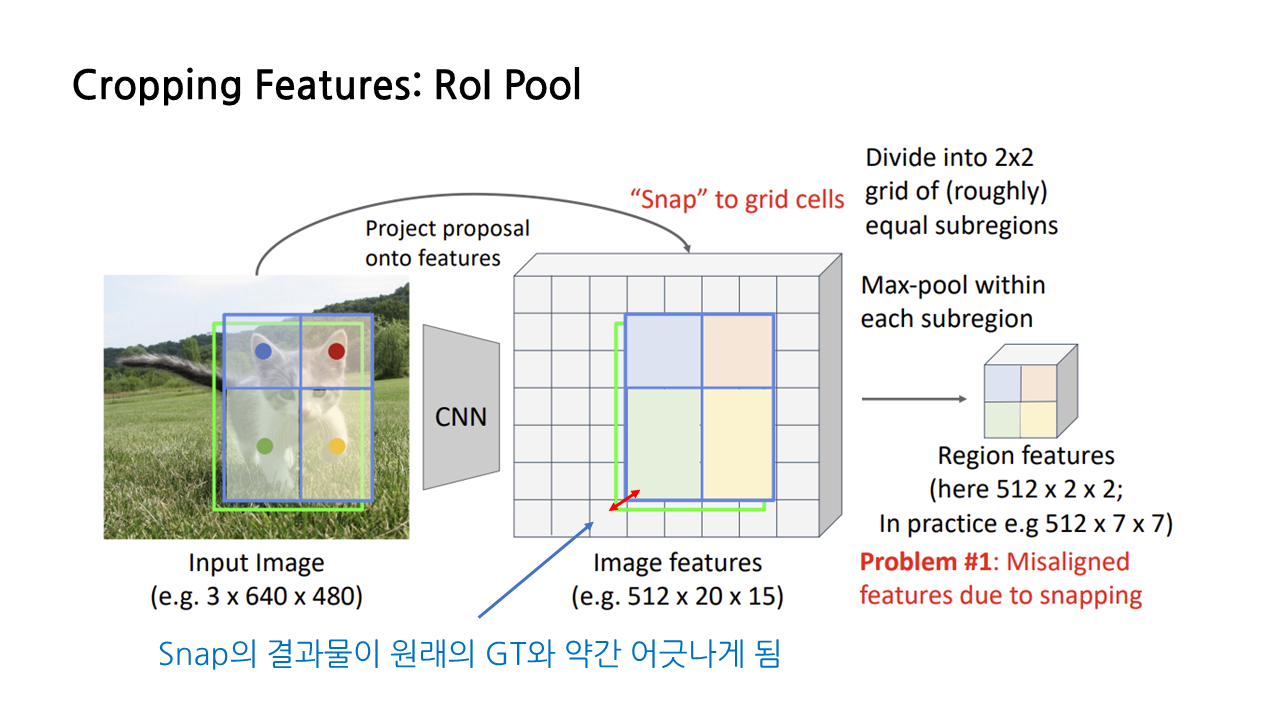
두 번째 문제 또한 snapping과 관련된 것으로, 앞서 설명한 첫 번째 문제와 연결되는 문제다. snapping 및 max pooling 결과 생성되는 region features는 원본 이미지에 대한 feature map과 crop하기를 원하는 bounding box를 토대로 만들어지므로, feature map과 bounding box(box target)를 input으로 하는 일종의 함수라고 생각해볼 수 있다.
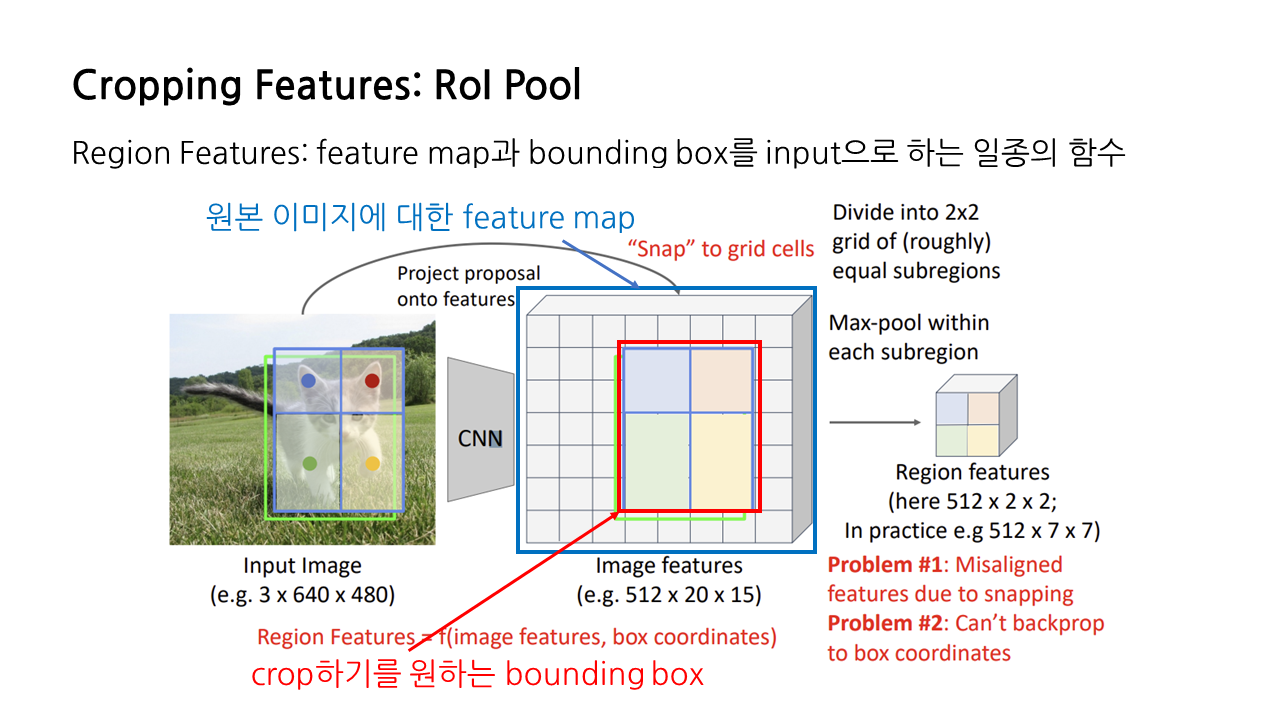
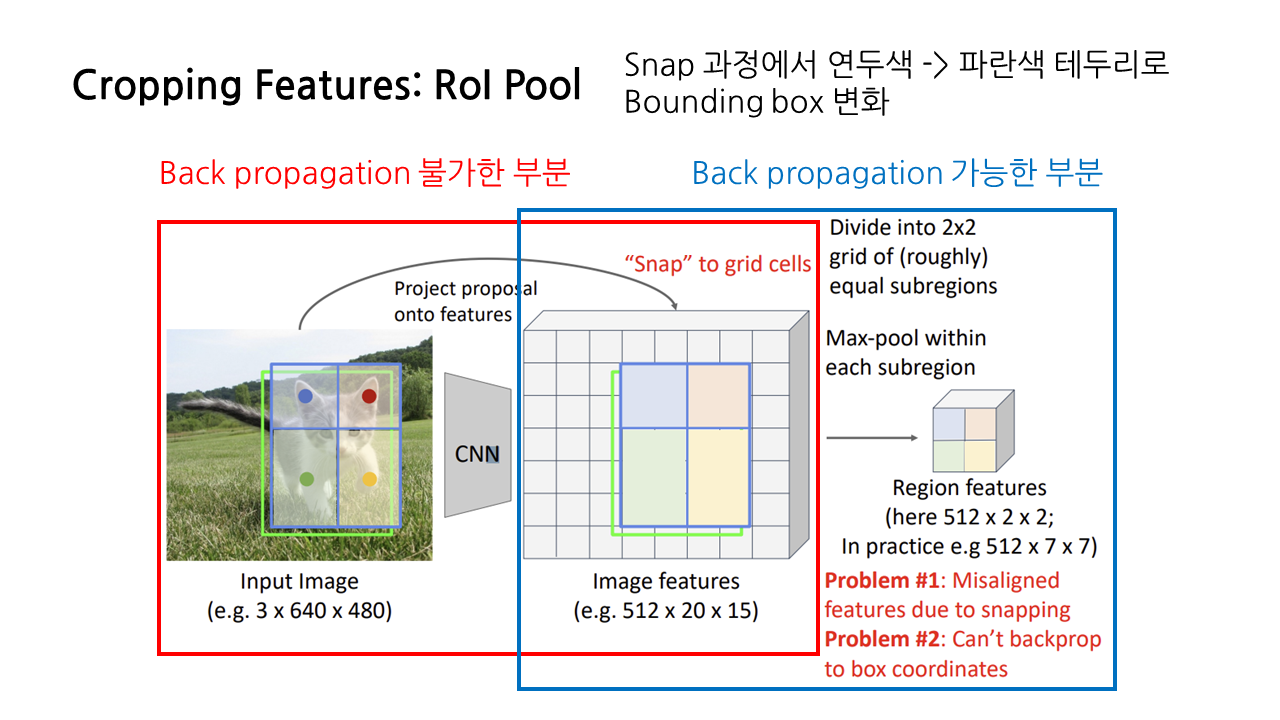
그런데 snapping을 하면 RoI의 bounding box가 항상 grid cell에 맞춰지는 방식으로 변형이 일어나서 기존의 GT와 맞지 않게 되기 때문에, 이에 대한 back propagation이 불가능해진다. RoI pooling에서는 region feature로부터 feature map을 향한 back propagation은 가능하지만, 연두색으로 표현된 원본 이미지의 bounding box를 향한 back propagation이 불가하다는 문제가 생긴다.
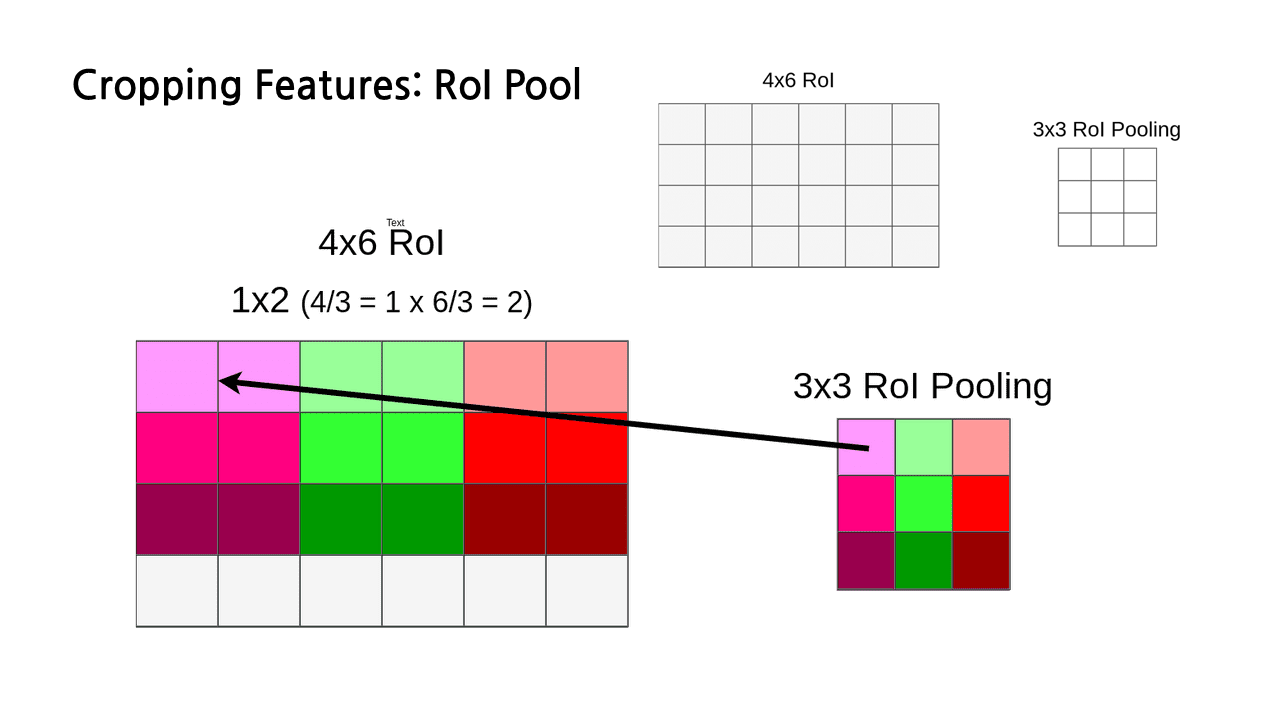
앞서 설명한 문제들에 대해 좀 더 부연 설명을 해보겠다. 원래의 RoI가 4.53*6.25의 사이즈를 가지고 있었다고 생각해보자. RoI 크기가 실수라서 일부 셀이 분할되어 있기 때문에 이 상태로는 pooling layer를 적용할 수 없으므로 가로, 세로 크기를 내림하여 4*6의 정수로 만들어줌으로써 grid에 딱 맞도록 한다. 이것이 바로 snapping이다. 이러면 이미 크기를 내림했기 때문에 데이터 손실도 발생하고, GT와도 차이가 생긴다는 문제가 있다.
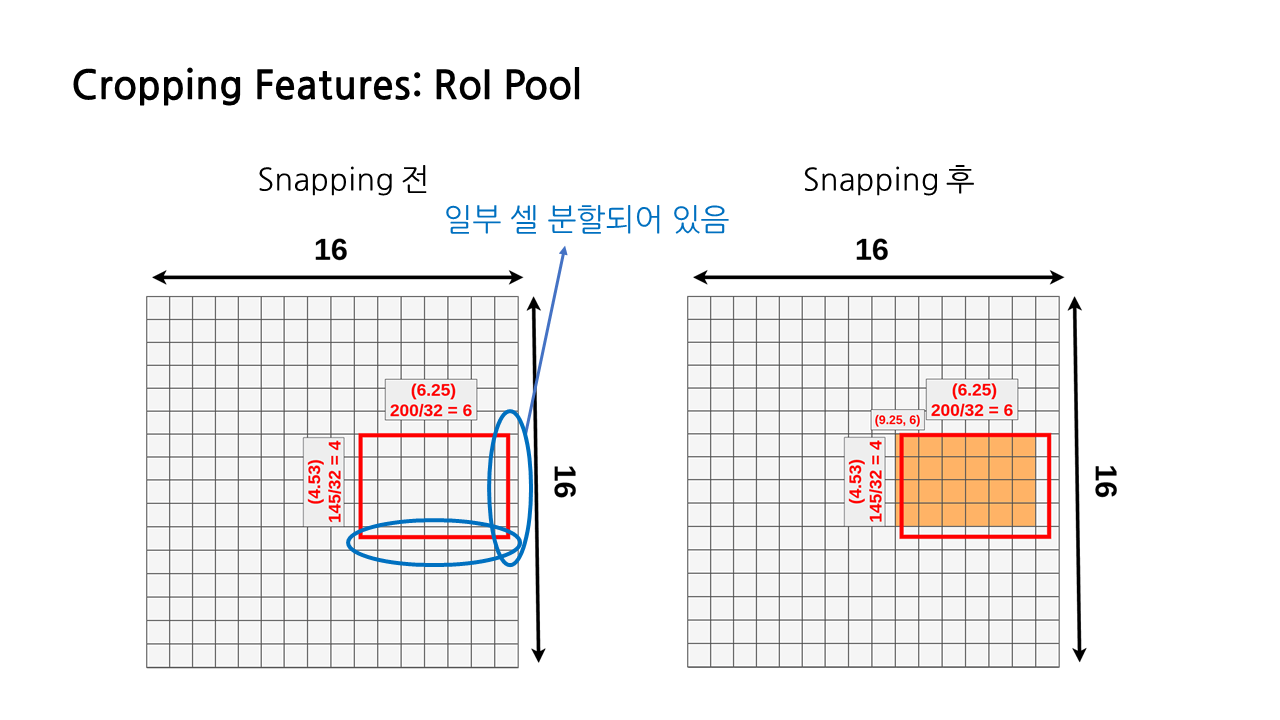
조금 더 나아가자면, 이제 우리는 6*4 크기의 RoI를 가지게 되었고, region feature를 생성하기 위한 max pooling 과정에서 사용하고자 하는 레이어의 크기는 3*3이다. 그런데 가로 6은 3으로 나누어 떨어지지만, 세로 4는 그렇지 못하다. 4를 3으로 나눴을 때 나머지는 1이다. 그래서 나머지에 해당하는 마지막 한 행 전체가 또 한 번 손실되게 된다. snapping을 하며 크기를 조정하는 과정에서 이미 일부 데이터가 손실되었는데, pooling 과정에서 한 번 더 손실이 일어나게 되는 것이다.
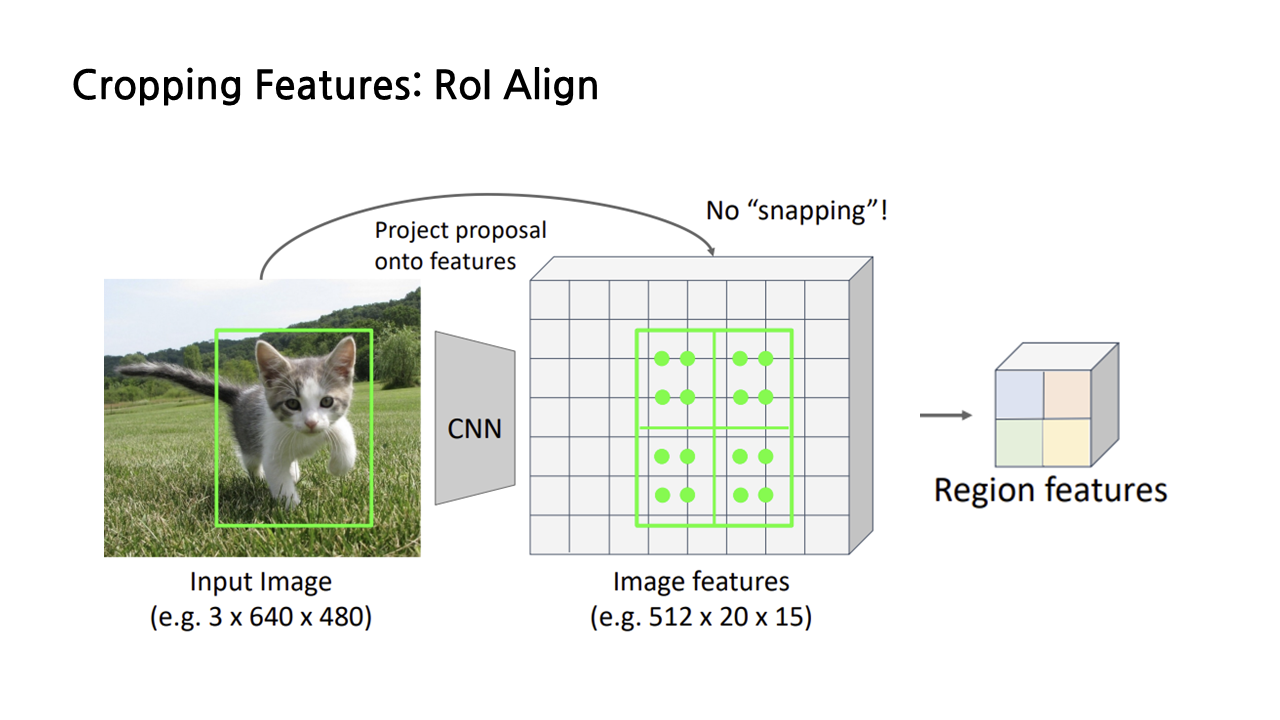
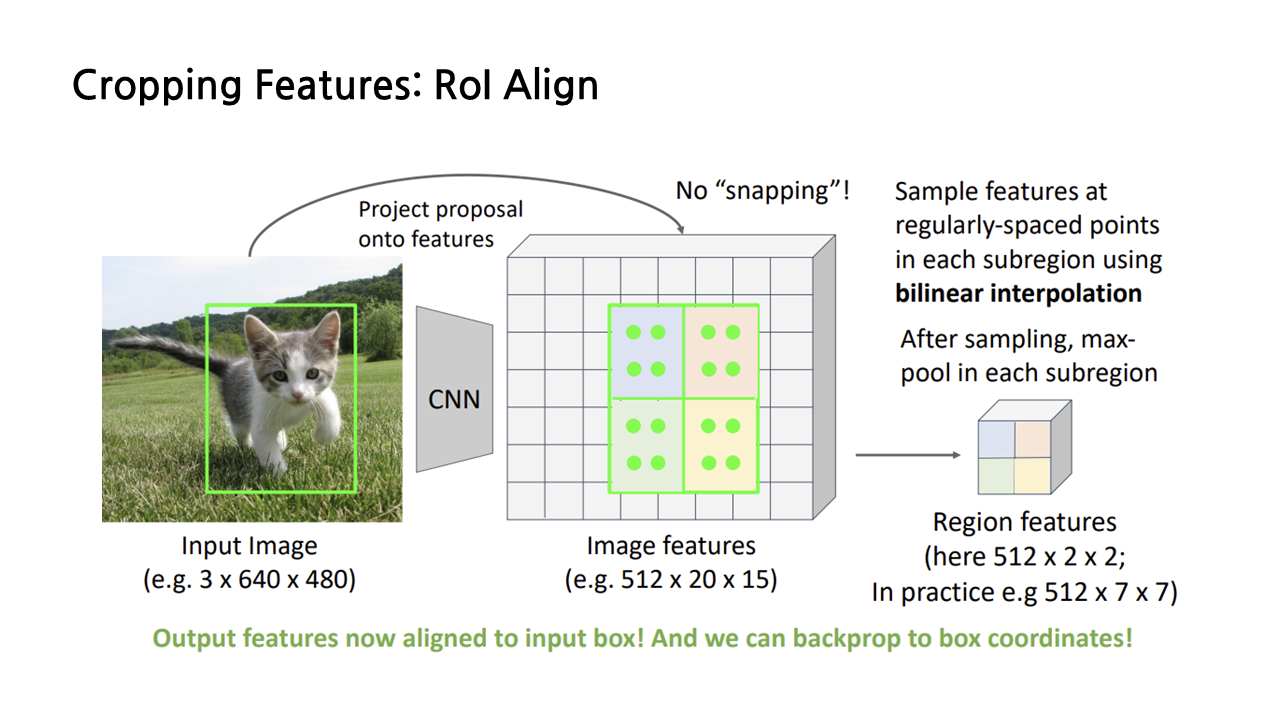
RoI Pooling에서 이렇듯 snapping이 여러 문제를 발생시키자, snapping 과정을 없앤 RoI Align이 등장했다. Input image를 feature map에 projection 시키는 것까지는 RoI Pooling과 동일한데, 이후에 snapping을 진행하는 대신 이런 방법을 사용한다.
우선 projection을 통해 생성된 RoI를 우리가 만들고 싶은 region features의 크기에 맞춰 등분해준다. 예시에서 저희는 2*2 크기의 region features를 생성하고자 하므로 아래와 같이 4등분을 하면 된다.
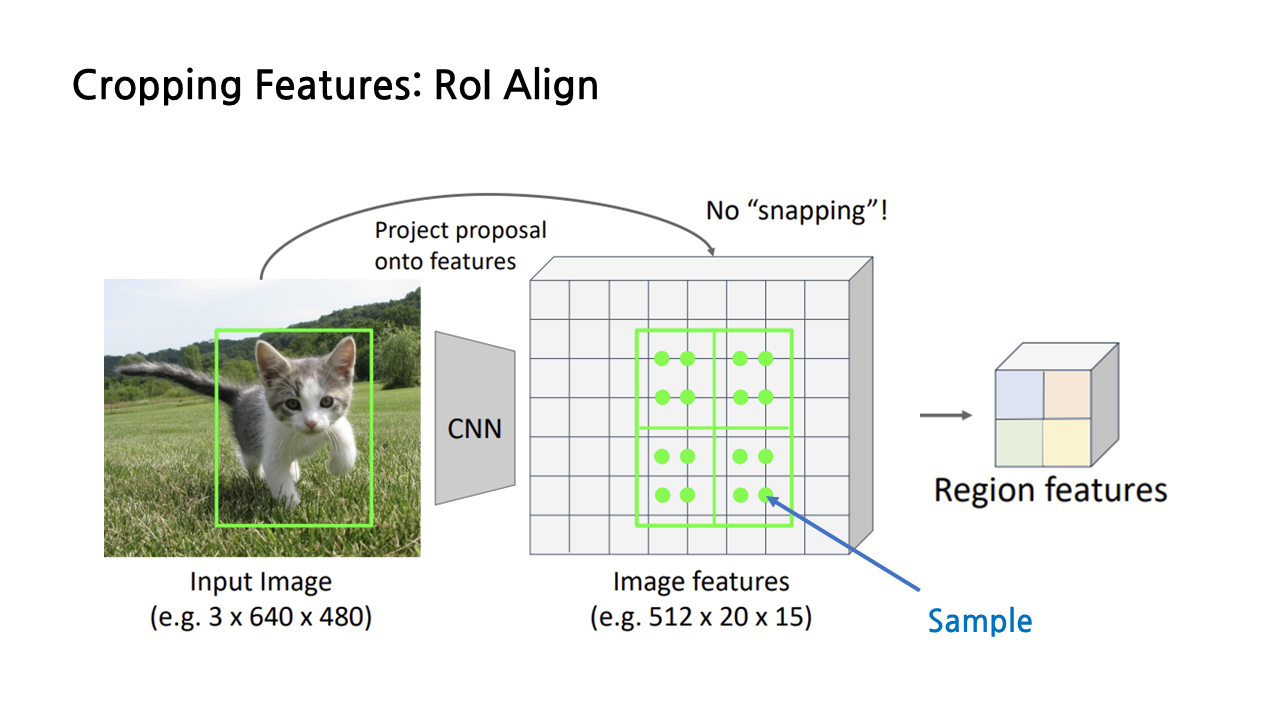
그러고 난 뒤에는 그림에서 연두색 점으로 표시된 ‘sample point’들을 잡는다. 4등분한 각각의 subregions별로 같은 간격으로 균일하게 퍼지게끔 잡으면 된다. 그러고 난 뒤에는 sample point마다 ‘bilinear interpolation’, 즉 쌍선형 보간법을 적용하여 각 sample point가 하나의 값, feature를 갖도록 만든다.
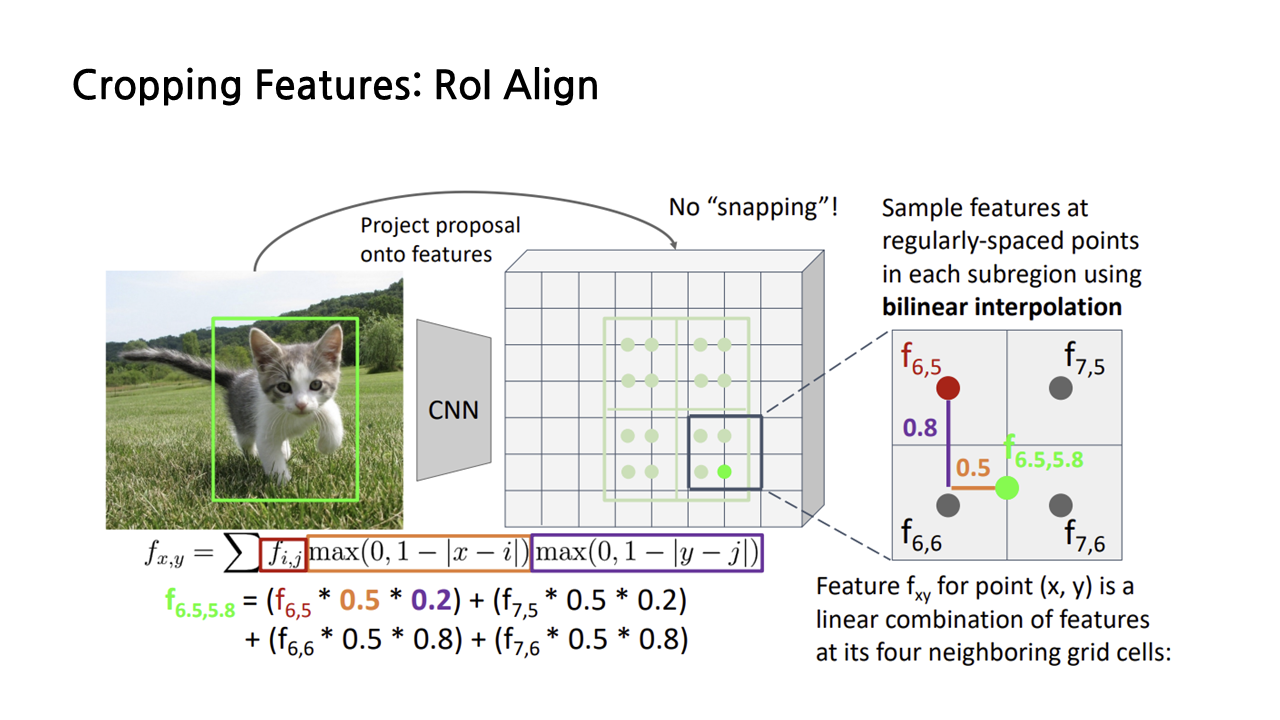
진한 연두색의 sample point를 예시로 들어 쌍선형 보간법을 하는 과정을 자세히 보겠다. 보간을 할 때는 아래 그림과 같이 해당 sample point를 기준으로 가까운 4개의 grid cell의 feature 값을 이용한다. 가까운 거리의 feature에 더 큰 가중치를 주는 방식으로 feature 값들을 더하는 방식으로 보간이 이루어지며, 그 식은 좌측 하단과 같다.
이렇게 계산이 끝나고 나면 연두색 점으로 표현된 각각의 sample point는 각기 하나의 feature 값을 가지게 되고, average pooling 혹은 max pooling을 이용해 최종적으로 우리가 원하는 region features 사이즈인 2*2로 축소한다.
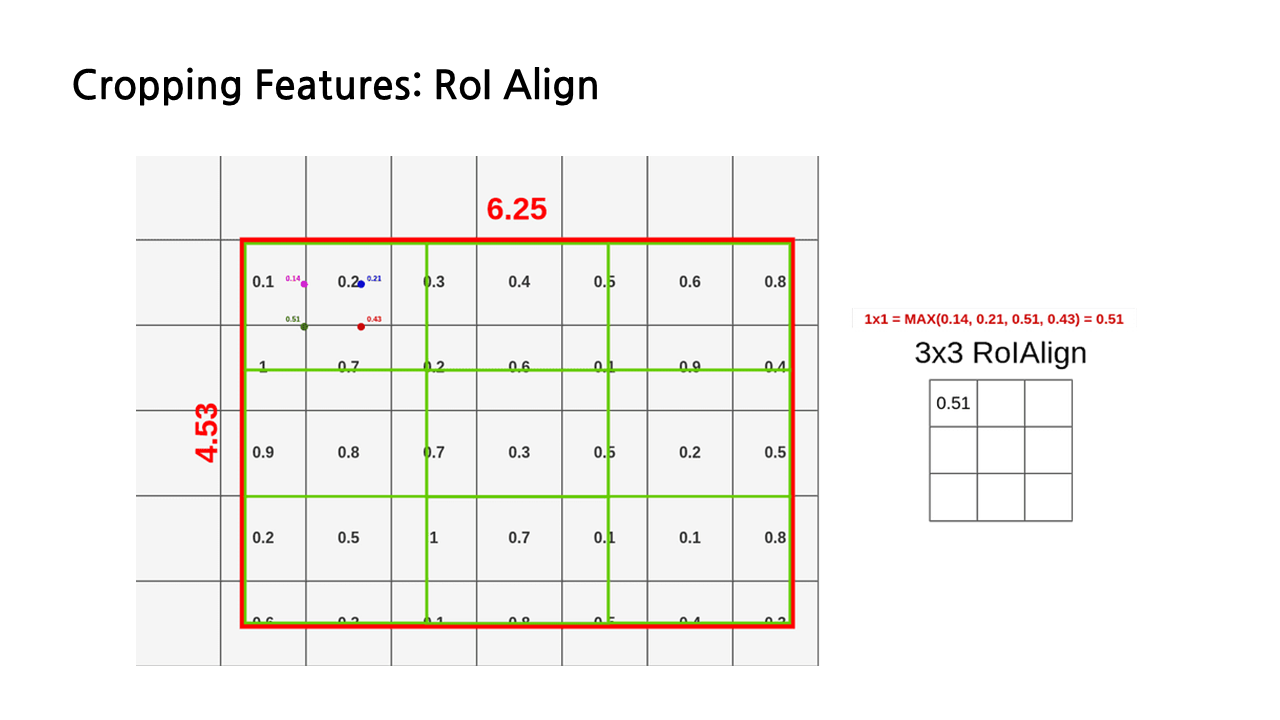
다른 예시를 통해 다시 한 번 보도록 하자. 이 예시에서는 3*3의 region feature를 산출하는 것이 목표라서 전체 RoI를 9등분 한 모습을 볼 수 있다. 작아서 잘 보일지 모르겠지만 첫 번째 칸의 분홍색, 파란색, 초록색, 빨간색 점들이 sample point이고, 이미 쌍선형 보간법이 끝나서 각각의 sample point에 0.14, 0.21, 0.51, 0.43이라는 feature 값이 계산된 상태이다.
RoI Align에서는 대체로 max pooling을 이용하기 때문에, 이 네 개의 sample feature 중에서 가장 큰 값인 0.51을 region feature의 첫 번째 칸의 feature로 사용하게 된다.
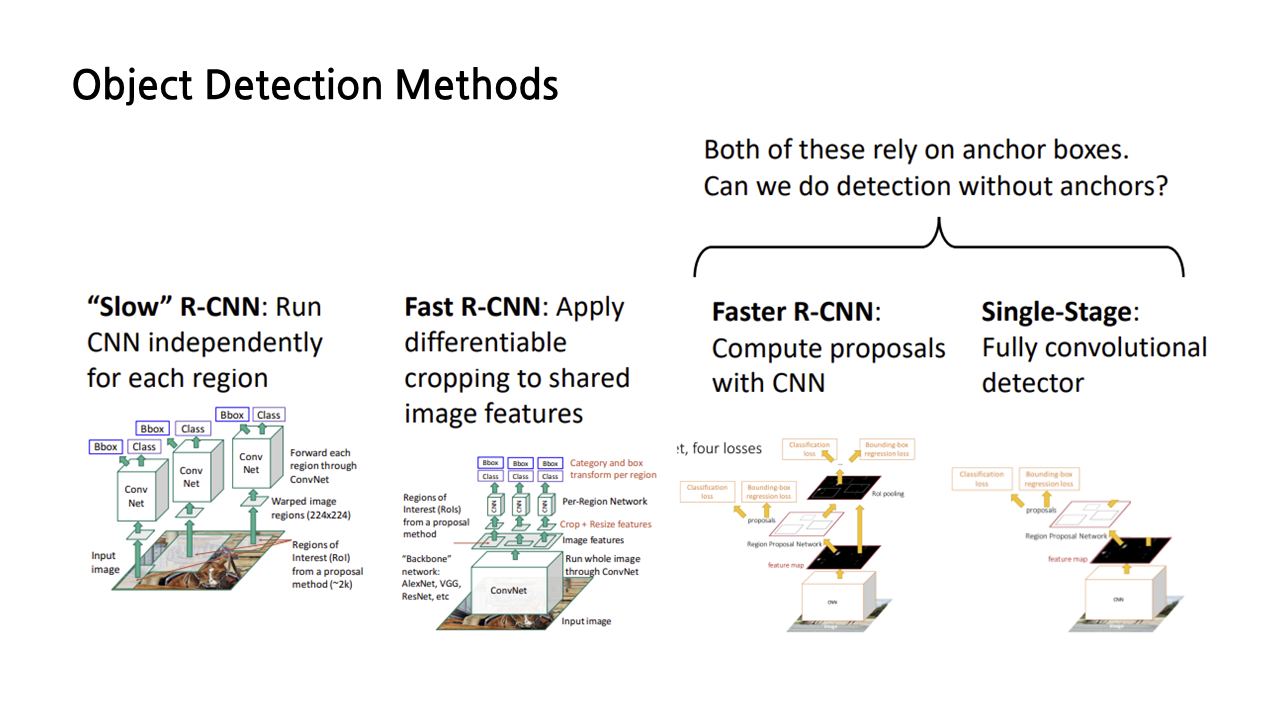
지금까지 배운 내용을 정리하면, object detection methods에는 R-CNN, fast R-CNN, faster R-CNN, singe-stage 등이 있다. 이중에는 faster R-CNN과 single stage가 가장 발전된 형태라고 볼 수 있는데, 둘 다 작동 방식이 ‘anchor box’와 연관되어 있다는 공통점이 있다. 혹시 anchor boxes 없이도 detection을 할 수 있는 방법이 없을까?
이러한 질문에서 출발한 것이 바로 ‘CornerNet’이다. 이는 지금까지와는 굉장히 상이한 방식으로 bounding boxes를 만드는데, 아래 그림에서 보이는 것처럼 왼쪽 위와 오른쪽 아래 코너의 point pair를 통해 bounding box를 표현한다(이 방법에 대해서는 강연자께서 아이디어 소개 정도로 간단하게만 알려주고 넘어가서, 강의에서 소개한 정도로만 가볍게 설명하도록 하겠다).
왼쪽 위, 오른쪽 아래 코너를 정할 때는 각 object 별로 어떤 픽셀이 해당 코너로 적합한지에 대한 확률을 계산해서 이를 토대로 결정한다. 우선 image level features를 얻기 위해 backbone CNN에 input image를 넣는다. 이렇게 생성된 image features에서, 우리가 예측하고자 하는 각각의 object 별로 왼쪽 위와 오른쪽 아래 코너에 대한 heatmap을 그린다. 이를 통해 feature map의 모든 위치 중에서 왼쪽 위 코너, 오른쪽 아래 코너가 될 확률을 산출할 수 있고, 각 픽셀에 대해 cross entropy loss를 구함으로써 해당 과정을 train할 수 있다.
그런데 우리는 왼쪽 위, 오른쪽 아래 코너 각각을 찾는 것에서 끝나는 것이 아니라, 각각의 코너를 서로 매칭시켜 하나의 bounding box를 이룰 수 있도록 해야 한다. 이를 위해 모든 위치에 대해 embedding vector를 함께 예측하고, embedding vector가 비슷한 왼쪽 위, 오른쪽 아래 코너끼리 짝을 짓게 된다.

다음으로 segmentation 파트가 이어지는데, 여기서부터는 다음 글에서 다루도록 하겠다.
'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 16강. Detection and Segmentation(3) (1) | 2023.03.03 |
|---|---|
| [EECS 498-007/598-005] 16강. Detection and Segmentation(2) (0) | 2023.03.03 |
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |



