
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- fortran90
- EECS 498-007/598-005
- implicit rule
- cs224w
- L1 distance
- computer vision
- Semantic Gap
- FORTRAN
- Graph Neural Networks
- algebraic viewpoint
- data-driven approach
- cross-entropy loss
- GNN
- print*
- 산술연산
- image classification
- human keypoints
- tensor core
- multiclass SVM loss
- gfortran
- feature cropping
- visual viewpoint
- geometric viewpoint
- parametric approach
- implicit rules
- format이 없는 입출력문
- 내장함수
- object detection
- cv
- L2 distance
- Today
- Total
수리수리연수리 코드얍
[EECS 498-007/598-005] 16강. Detection and Segmentation(2) 본문
[EECS 498-007/598-005] 16강. Detection and Segmentation(2)
ydduri 2023. 3. 3. 14:383. Segmentation: Semantic Segmentation
Segmentation에는 여러 종류가 있는데, 첫 번째로 semantic segmentation을 보겠다. 이는 이미지의 각각의 픽셀에 카테고리 label을 붙이는 것이다. Instance를 구분하는 것이 아니라 오직 픽셀에만 집중하기 때문에, 오른쪽 그림에서처럼 두 마리의 소가 붙어 있더라도 이를 소 1, 소 2로 구분하는 것이 아니라 ‘소’라는 하나의 카테고리 라벨로 통칭한다.

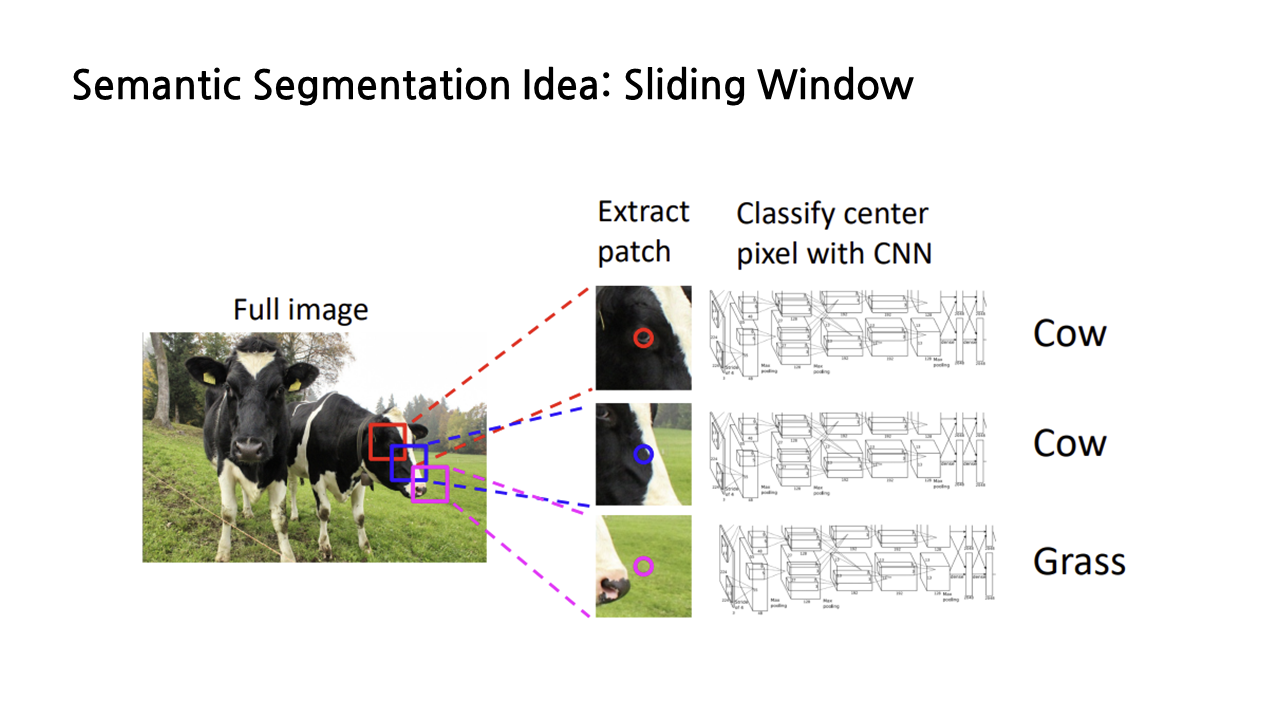
1) Sliding Window
강연자께서 semantic segmentation task를 해결하는 ‘멍청한’ 아이디어라고 소개한 내용인데, 바로 sliding window다. 이는 이미지의 각 픽셀에 대해 그 주변부를 포함한 작은 patch를 추출하고, 그 patch들 각각을 CNN에 넣어서 라벨링을 하는 방식이다. 이걸 모든 픽셀에 대해서 계속해서 반복한다고 생각하면… 생각만 해도 아찔하다. 워낙 느리고 매우 비효율적인 방법이라 잘 사용하지 않는다.
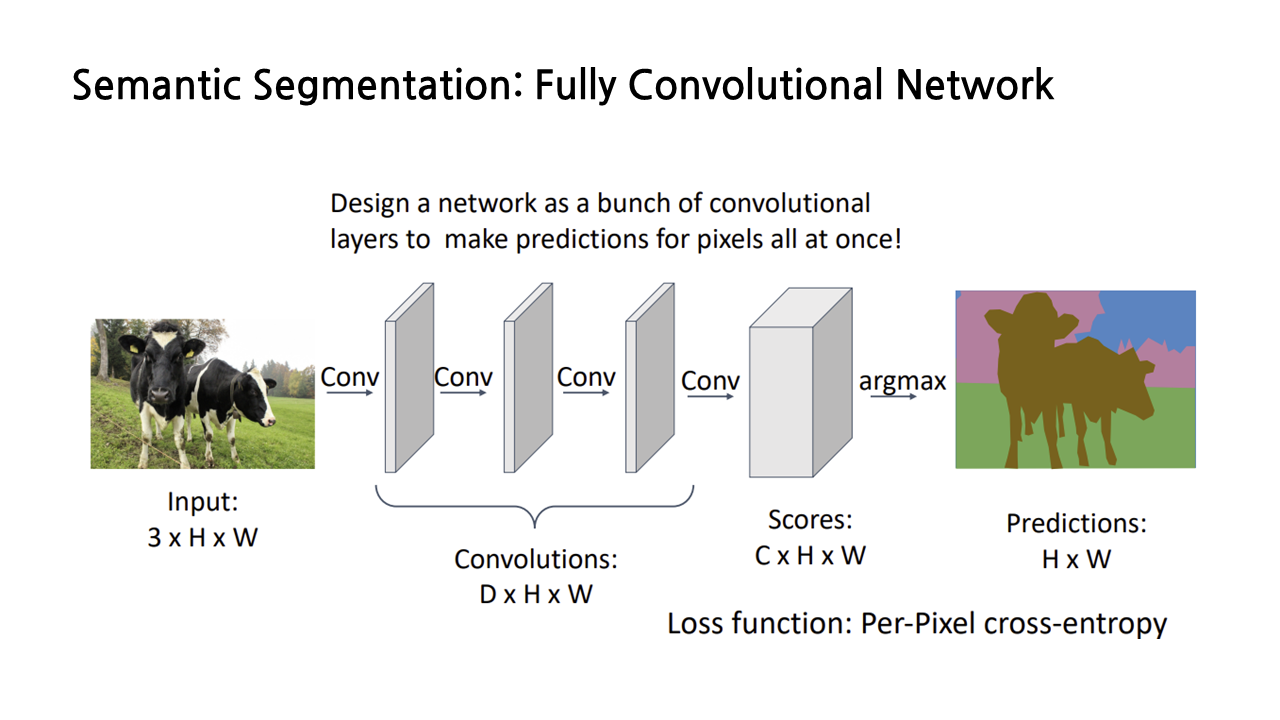
2) Fully Convolutional Network
대신에 더 보편적으로 쓰이는 방법은 fully convolutional network라 불리는 CNN architecture를 활용하는 것이다. 이는 fully connected layer나 global pooling layer가 없는, convolution layer의 ‘big stack’이다.
해당 신경망을 통과하고 난 output은 각각의 픽셀에 대한 class scores 정보를 가지게 된다. 예를 들어 사이즈 3*3, padding=1, stride=1의 convolution layer를 쌓으면, output은 input과 같은 size를 가지게 되며, 채널의 개수는 우리가 구분하고자 하는 카테고리의 개수와 같아지게 된다. output인 score layer는 말그대로 각 픽셀마다의 카테고리 label score를 가지게 되며, 우리는 softmax를 이용해 확률값을 반환함으로써 각 픽셀에 대한 label을 판단할 수 있다. 해당 모델은 픽셀 별 cross entropy loss를 구함으로써 train 시킬 수 있다.
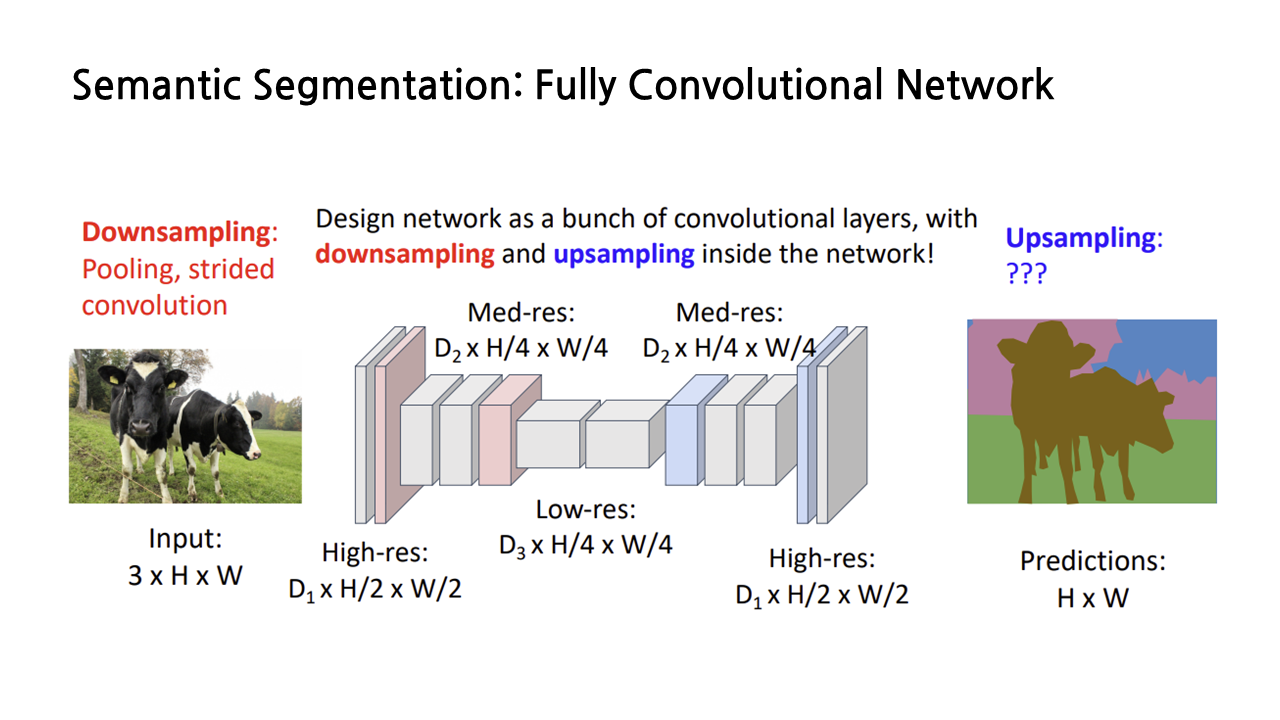
그런데 이 방식에는 두 가지 문제점이 있다. 첫 번째는 사이즈 3*3, padding=1, stride=1인 convolution layer를 계속해서 쌓기 때문에 receptive field의 크기가 convolution layer 개수에 따라 linearly하게 증가한다는 점이다. L개의 layer를 쌓으면 receptive field의 개수는 1+2L 만큼 증가한다고 한다. 두 번째는 고해상도 이미지에서 convolution이 비싸다는 것이다. 그래서 필요한 것이 바로 ‘downsampling’이다.

그런데 downsampling을 하더라도, 결과물은 input 이미지와 동일한 해상도로 나와야 할 것이기 때문에 다시 upsampling을 해주어야 한다. downsampling은 pooling이나 stride 조절을 통해 할 수 있다는 걸 알고 있는데, upsampling은 어떻게 할까? 지금부터 upsampling의 방법에 대해 다루겠다.
3) Upsampling
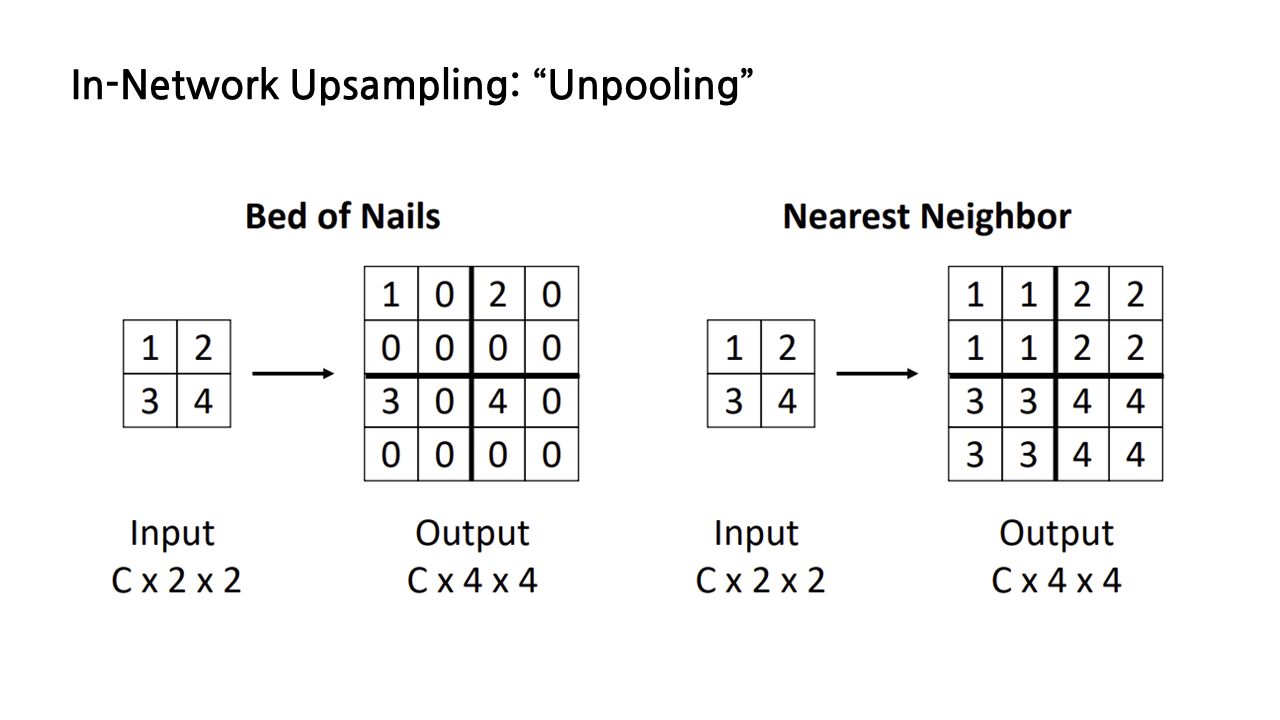
(1) In-Network Upsampling: "Unpooling"
앞서 언급했듯이 pooling이 downsampling을 수행하게 해주는 방법이었으므로, upsampling을 수행하려면 그 반대인 ‘unpooling’을 하면 된다. unpooling을 하는 방법 첫 번째는 ‘bed of nails’라는 방식인데, 아래 그림과 같은 방식으로 왼쪽 위에 input feature들을 넣고, 사이즈를 키우면서 생긴 나머지 칸을 모두 0으로 채우는 방법이다. 딱 봐도 감이 올 테지만 그리 좋지 못한 방법이라 자주 사용하진 않는다고 한다.
좀 더 보편적으로 사용되는 다른 unpooling 기법은 nearest neighbor로, 아래 그림과 같이 input feature 값을 복사하여 확대된 칸을 채우는 방식이다.
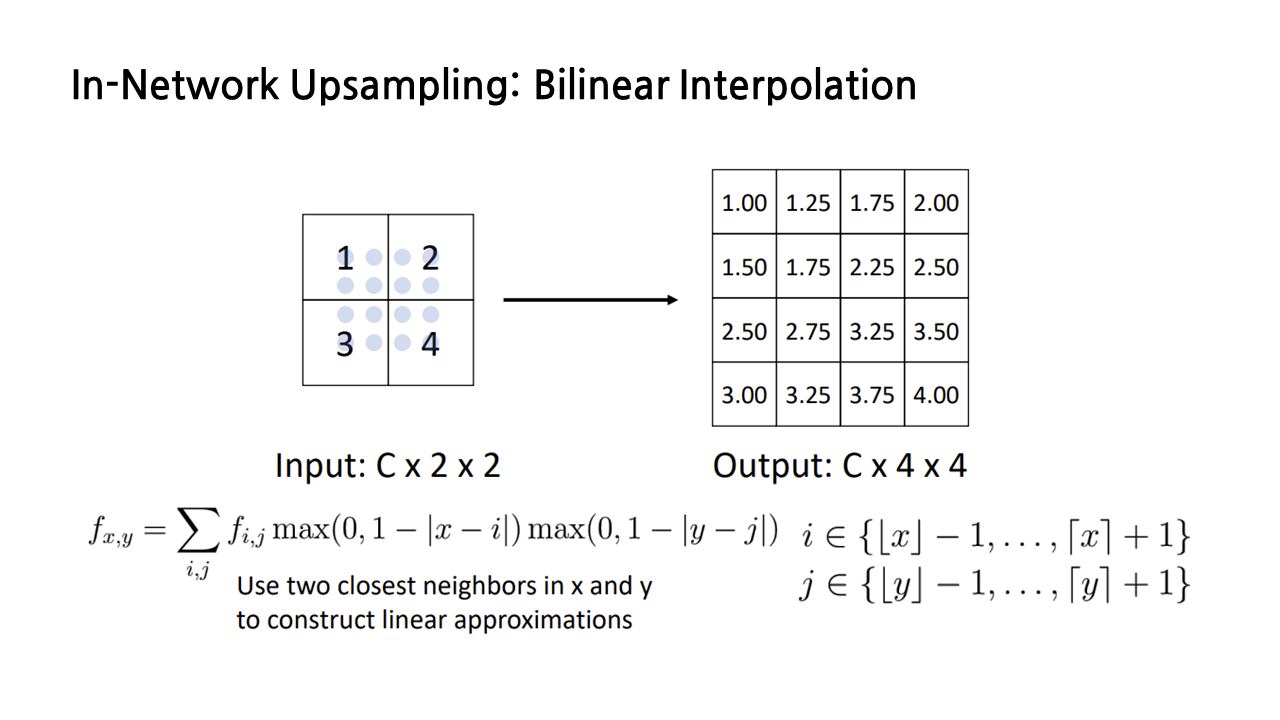
(2) In-Network Upsampling: Bilinear Interpolation
또다른 방법은 아까 RoI Align 할 때 사용했던 쌍선형 보간법을 이용하는 것이다. 아래 그림에서 옅은 하늘색 점으로 표시된 것이 sample point이고, 보간 과정은 앞서 자세히 설명했기 때문에 생략하도록 하겠다. 그 결과로 나오는 upsampling output이 nearest neighbor에 비해 스무스하다는 특징이 있다.
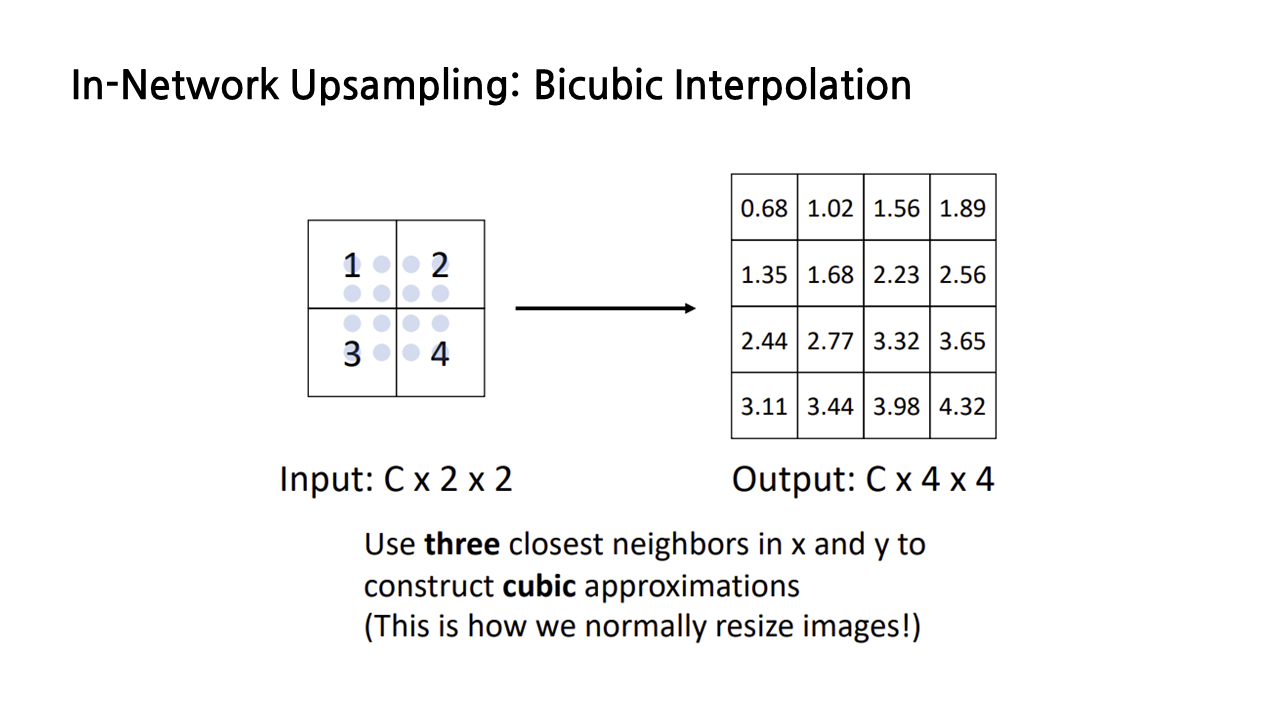
다른 종류의 interpolation을 이용하는 방법도 있다. 바로 bicubic interpolation인데, bilinear는 x, y 방향으로 각각 2칸씩 고려했다면, bicubic은 3칸씩 고려하는 방식이다.
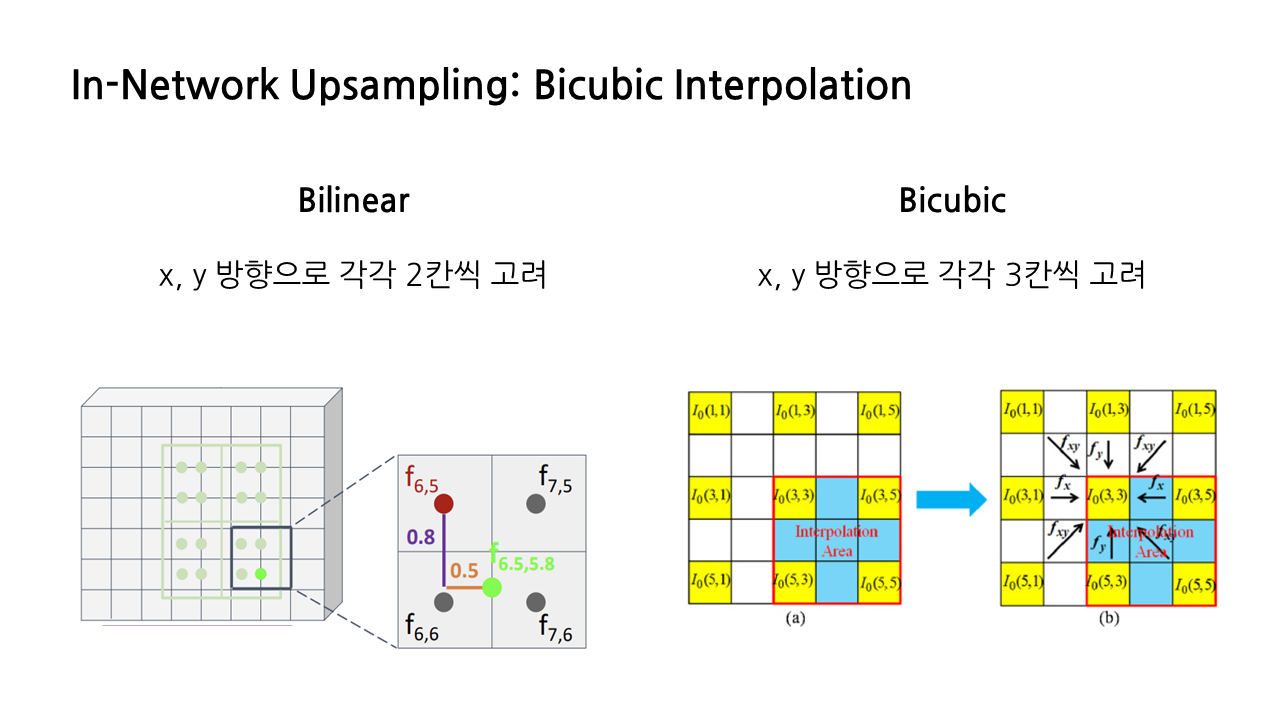
강의에서는 bicubic interpolation에 대해 자세히 다루지는 않았는데, JPEG 이미지를 resizing하는 데 좋다는 것을 포함해 여러 장점이 있어 가장 보편적으로 사용되는 upsamling 방식이라고 한다.
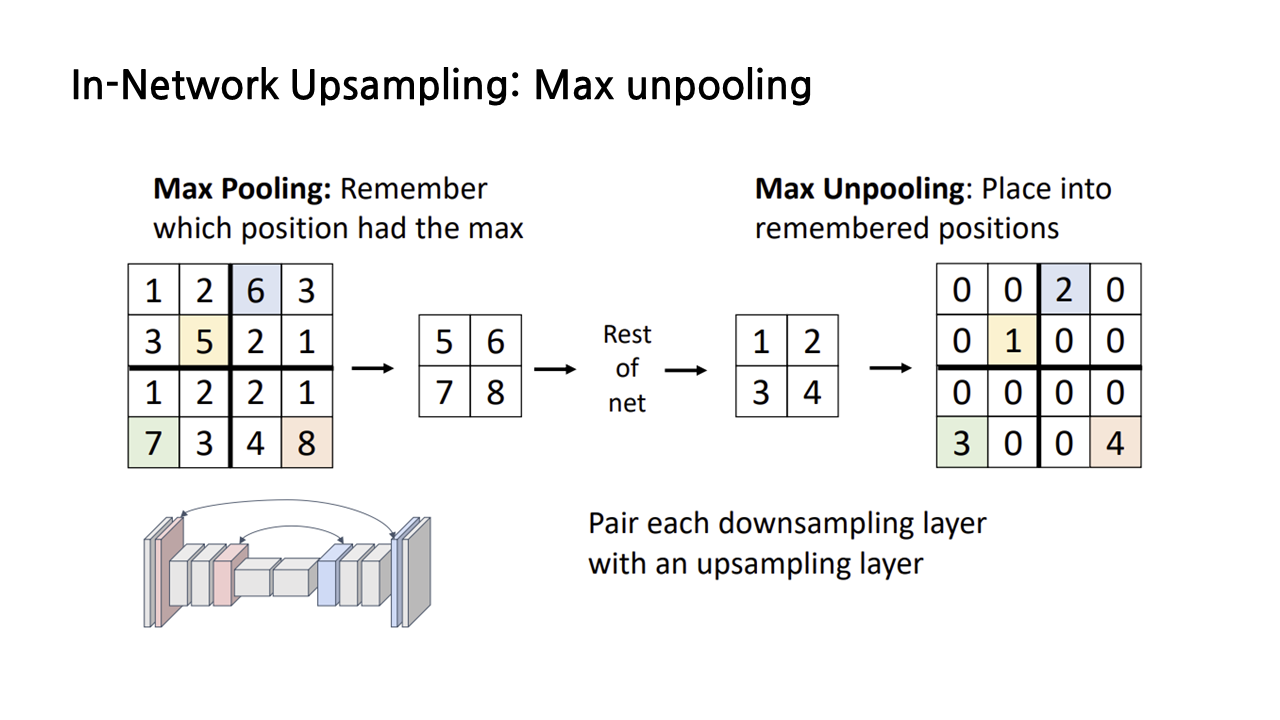
(3) In-Network Upsampling: Max Unpooling
max pooling으로 downsampling이 가능할 경우에 적용할 수 있는 max unpooling이라는 기법도 있다. max unpooling의 특징은 max pooling을 수행할 때 각각의 구역별로 최댓값이 나타나는 위치를 기억한다는 것이다. 그 뒤로는 아래 그림에서 보이는 예시처럼 bed of nails 방식이나 bilinear 등 앞서 살펴봤던 방식을 적용해서 upsampling을 수행하면 된다.
network에서 먼저 수행된 max pooling과 대응되기 때문에 downsampling 전과 upsampling 후의 misalignment를 방지할 수 있다는 장점이 있다. 경험적으로 봤을 때, pooling을 할 때 max pooling을 이용했다면 이와 같은 max unpooling을 사용하는 것이 좋고, average pooling 등 다른 pooling 방법을 사용했다면 앞에서 소개했던 다른 방식을 적용해도 무방하다고 한다.
(4) Learnable Upsampling: Transposed Convolution
지금까지 살펴본 upsampling 방식은 fixed function으로, 학습시켜야 할 파라미터가 없었는데, ‘transposed convolution’이라 불리는 learnable upsampling 방법도 존재한다. 그림에서 볼 수 있듯이 stride의 크기가 1 이상이라면 learnable downsampling을 할 수 있다. 그렇다면 stride 크기를 1보다 작게 하면 learnable upsampling을 할 수 있지 않을까? 해서 등장한 것이 바로 transposed convolution이다.
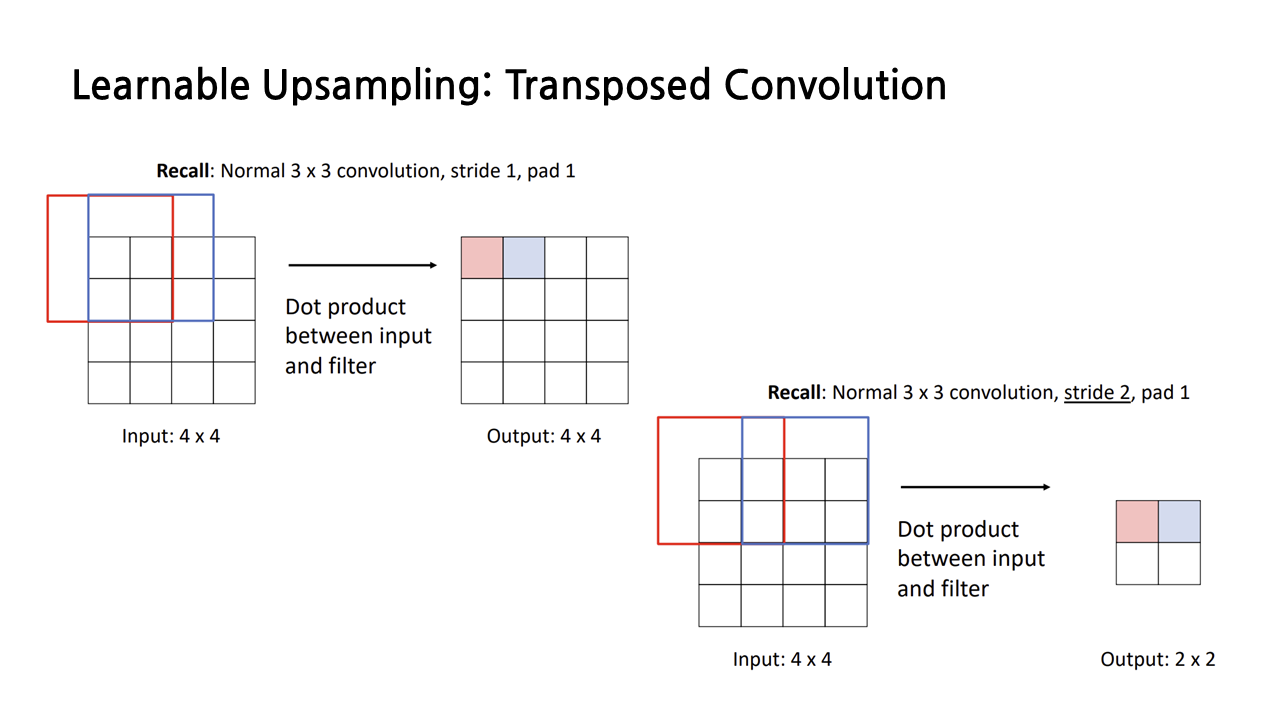
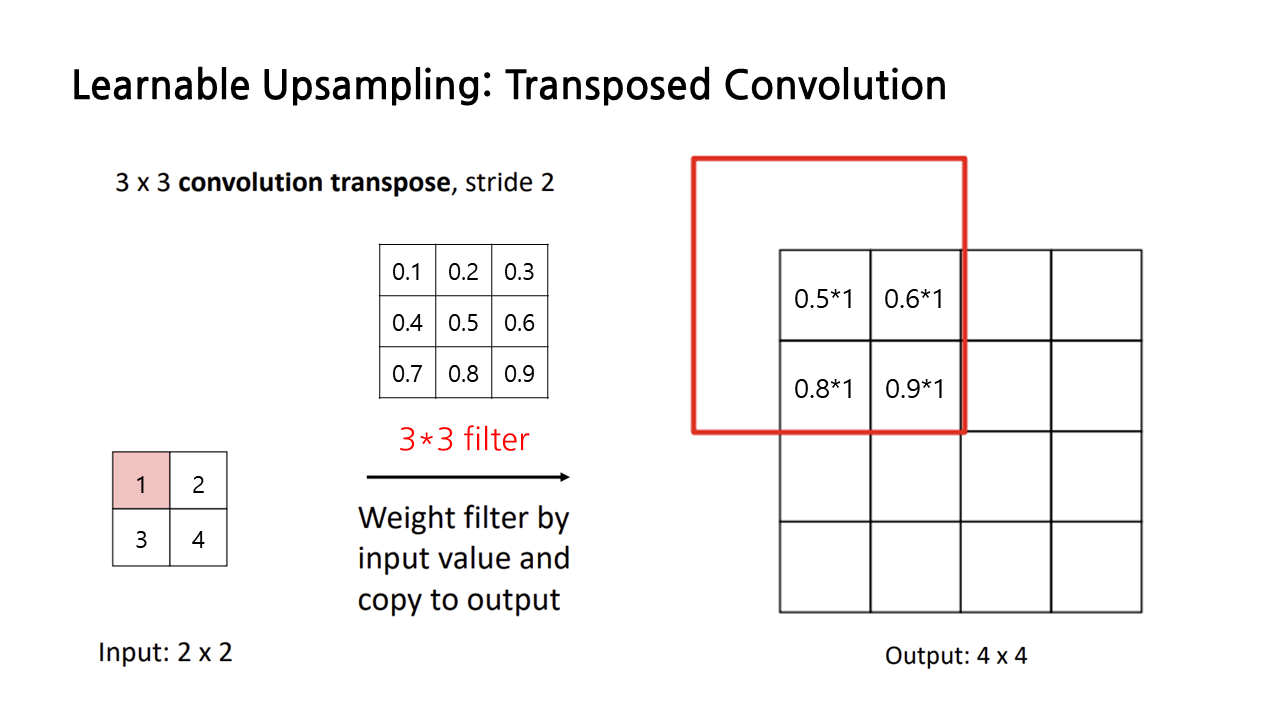
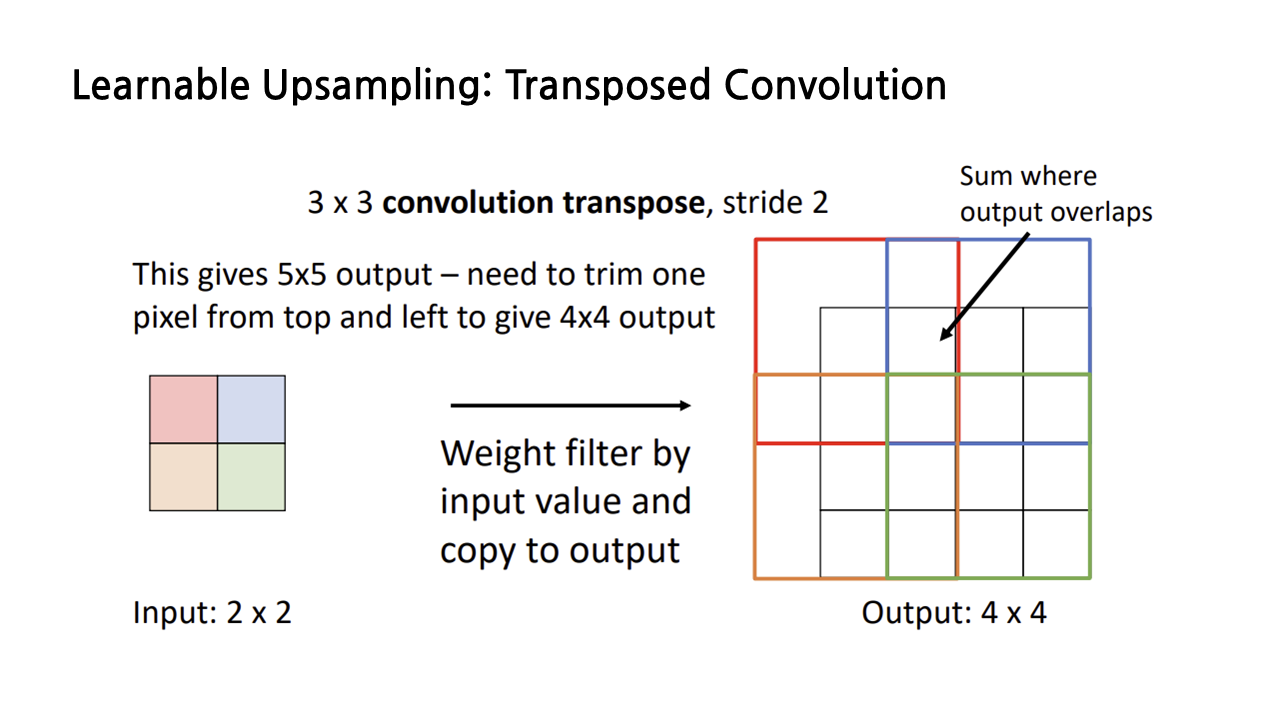
transposed convolution을 시각적으로 이해해보자. transposed convolution의 목표는 input보다 output의 크기를 키우는 것이므로, input feature들을 필터에 곱해서 더 큰 output으로 확장시켜야 한다. 아래 그림과 같은 filter와 input이 있을 때, input과 filter의 해당 부분을 곱해서 이런 방식으로 output의 각 칸을 채워 나가는 과정이 transposed convolution이다.
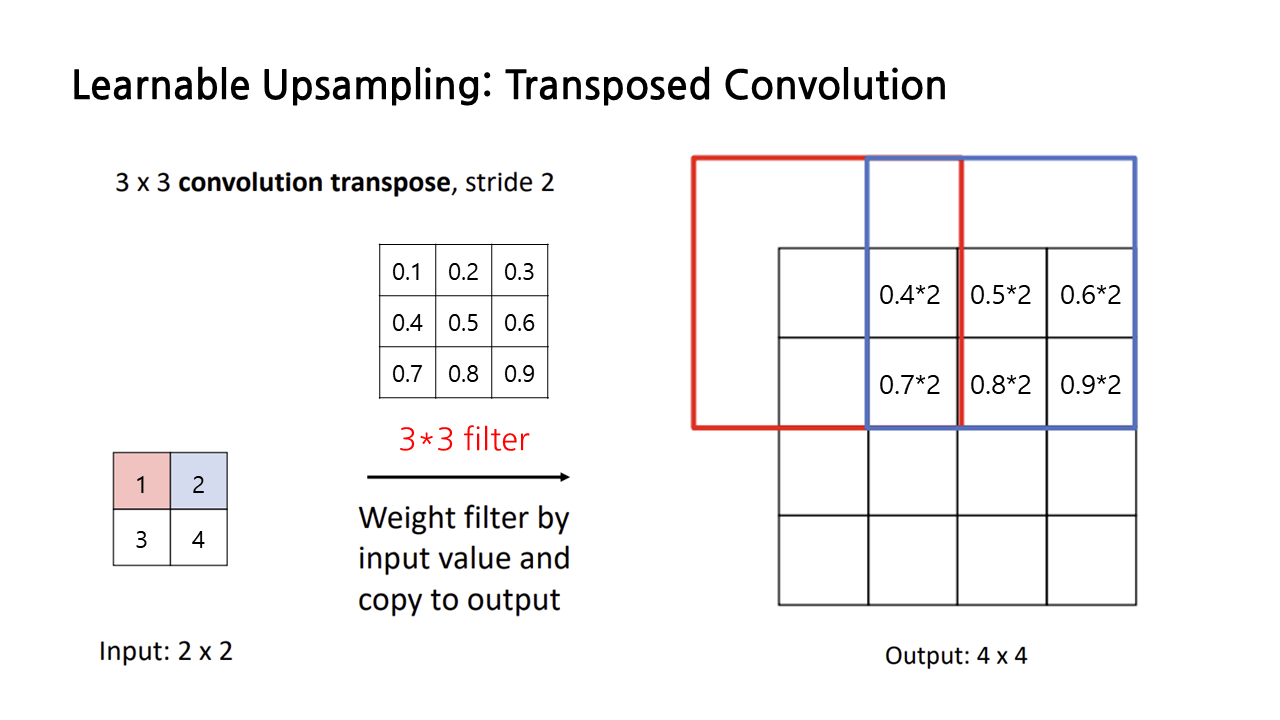
한 번 더 예시를 들면 다음과 같다. 그런데 이런 식으로 연산을 계속하다 보면 필터가 서로 겹치는 칸이 생기기 마련인데 어떻게 할까?
그럴 경우 아래 그림에서와 같이 각각의 연산 결과를 더해서 최종 output을 구한다.
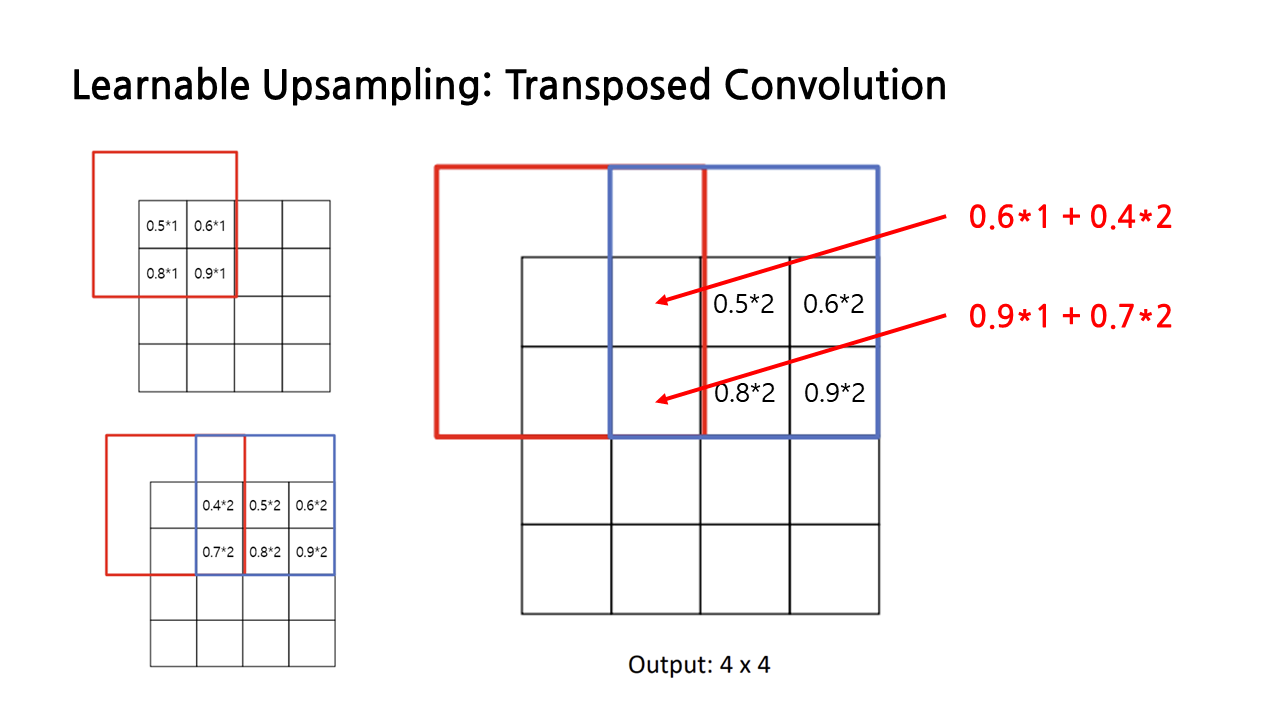
이런 방식으로 모든 칸에 대해서 연산을 수행한 결과는 아래 그림과 같이 표현할 수 있다.
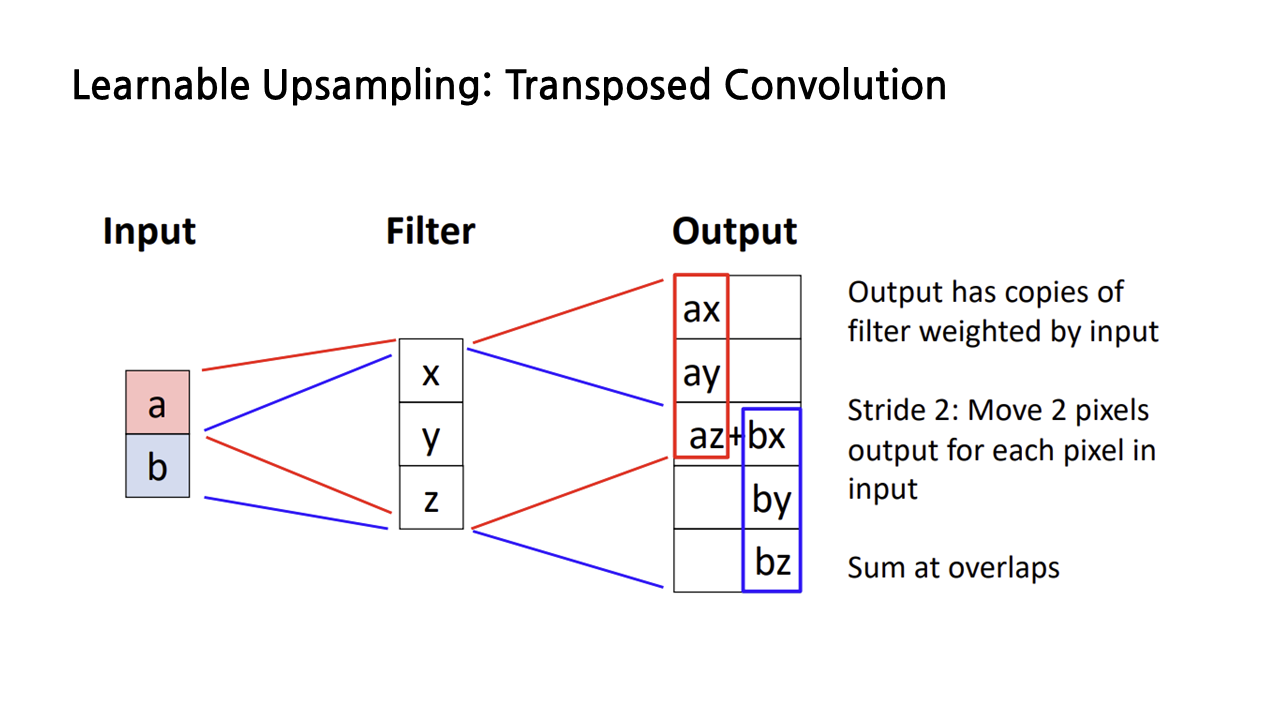
1차원으로 예시를 들어 보면 아래 그림과 같다.
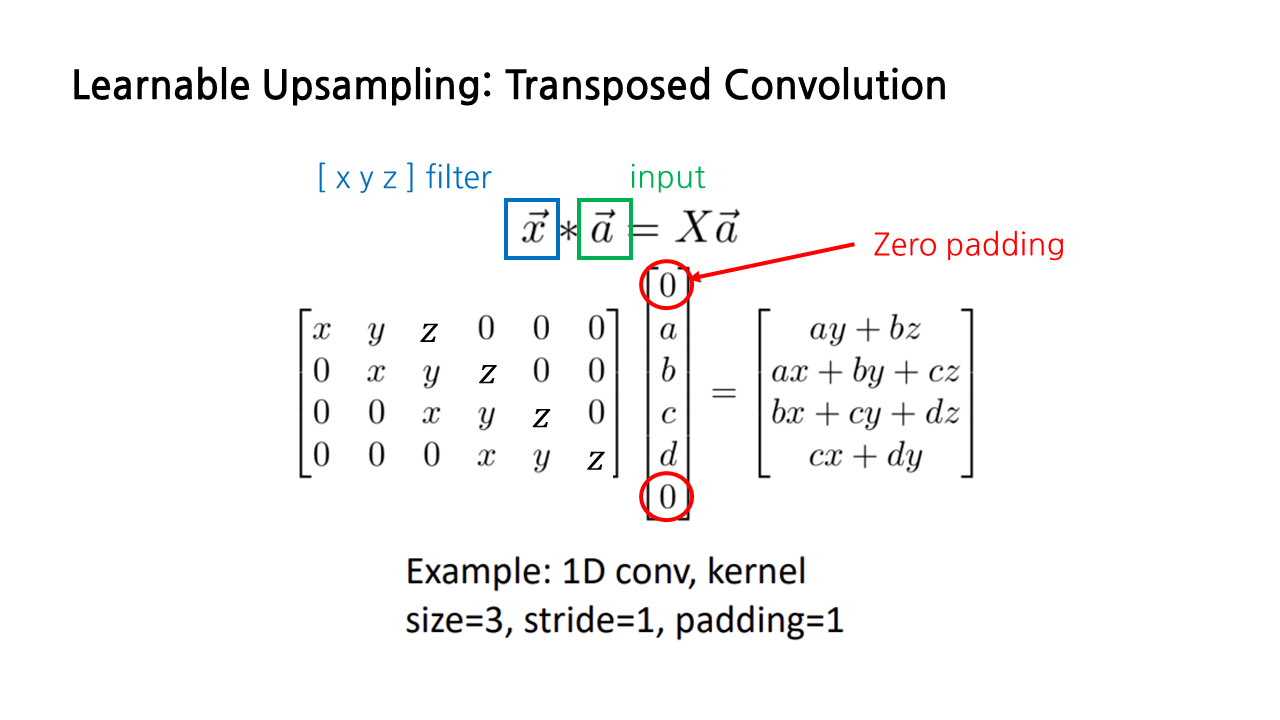
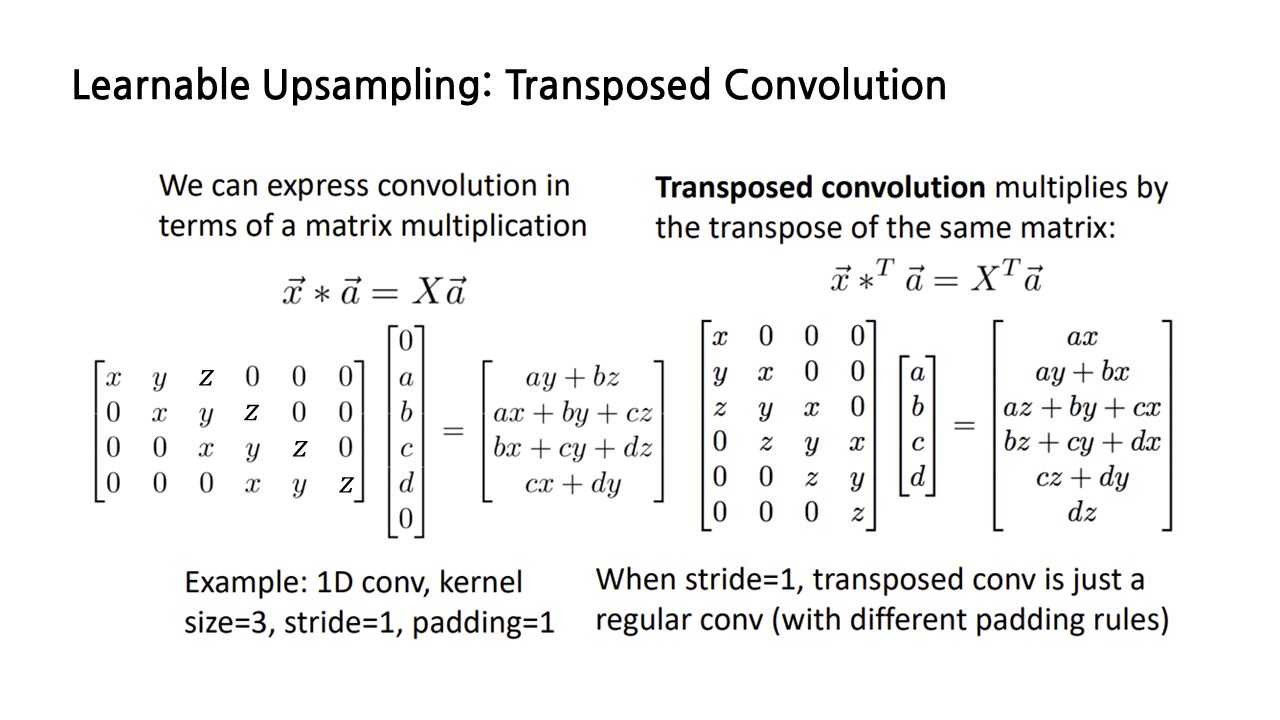
이 연산에 ‘transposed’ convolution이라는 이름이 붙게 된 이유는 convolution 연산을 matrix multiplication으로 나타내면 쉽게 알 수 있다. 이 슬라이드는 x y z로 구성된 길이가 3인 벡터 x와 a b c d로 구성된 a 사이의 convolution을 나타낸 것이다. 이때 x는 필터, a는 input에 해당하고, 벡터 a의 위아래에 있는 0은 zero padding을 의미한다.
우리가 살펴보고자 하는 transposed convolution은 벡터 x를 transpose한 상태로 convolution을 수행하는 것을 말한다.
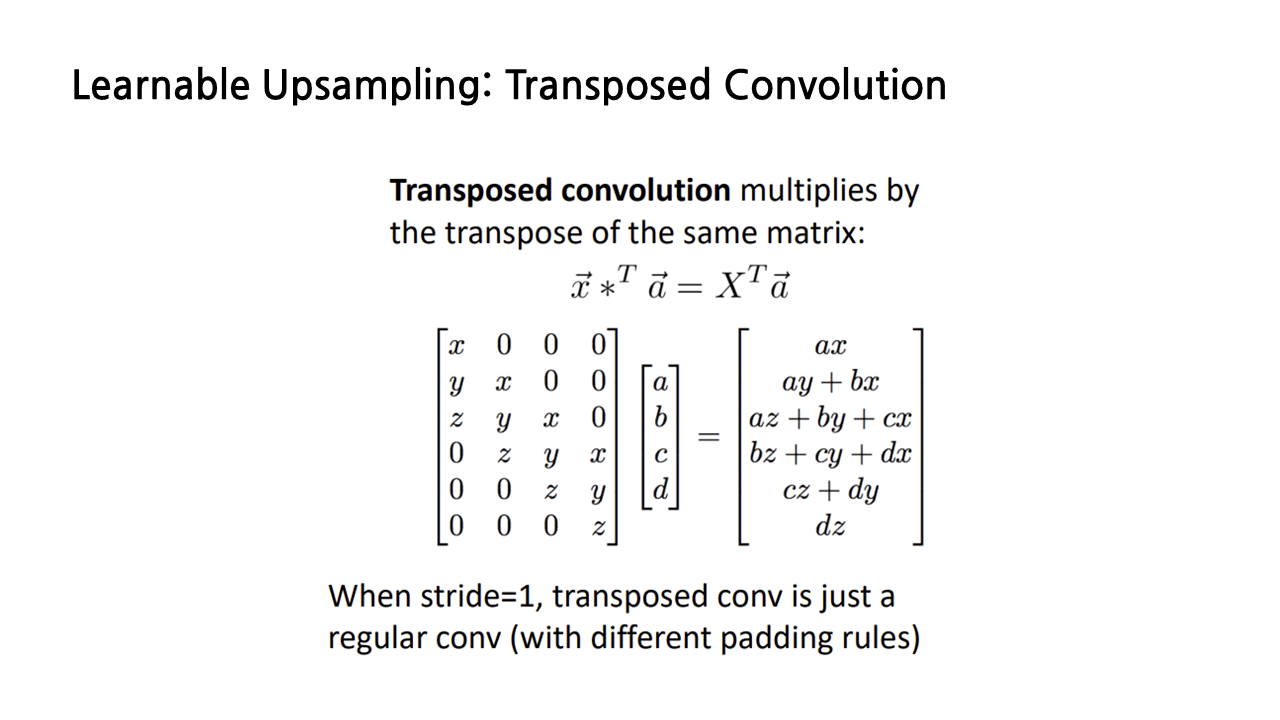
(사실 이 부분은 강의를 들으면서 아리까리했는데, 우선은 내가 이해한 대로 써보겠다...) stride가 1인 경우 normal convolution과 transposed convolution을 비교해보면, padding 규칙이 약간 달라졌을 뿐, 둘 다 convolution 연산을 수행하고 있음을 확인할 수 있다. transposed convolution과 normal convolution은 수학적으로 동일한 연산이다.
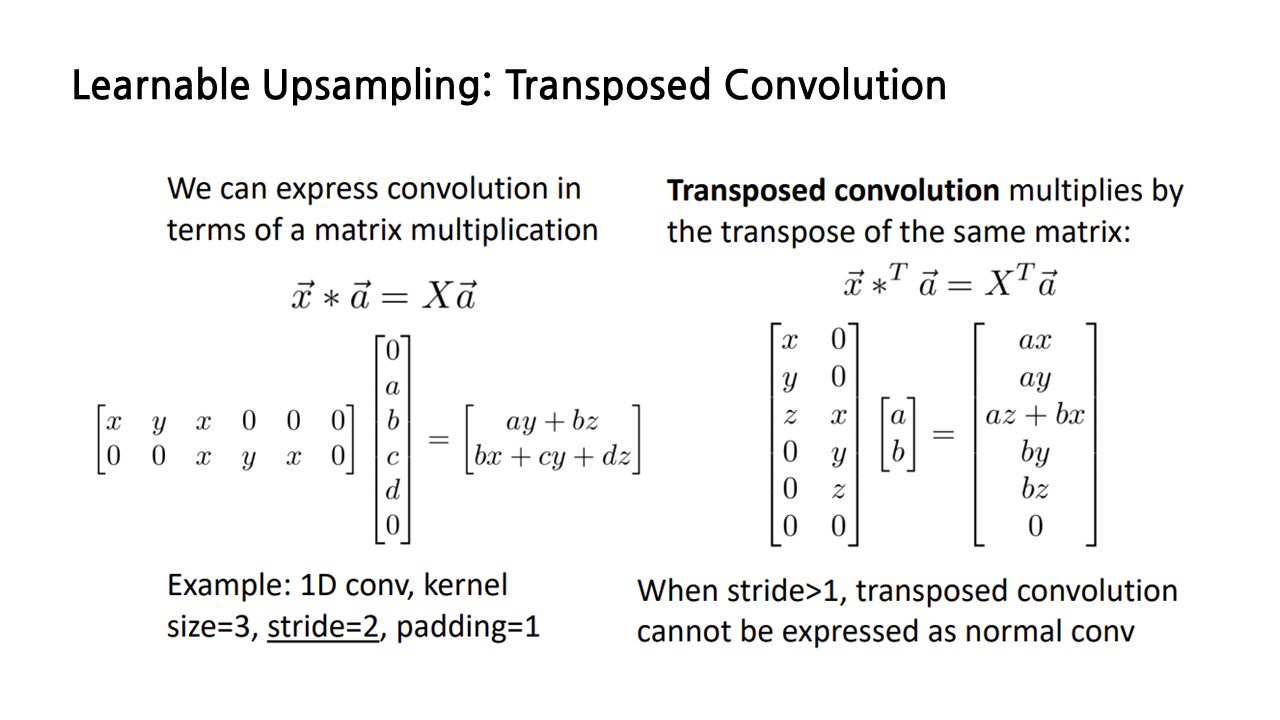
그런데 stride가 1보다 커질 경우 상황이 좀 달라진다. stride가 1일 때의 normal convolution과 transposed convolution은 padding이 있냐 없냐의 차이였는데, 여기서는 아예 input 행렬의 형태 자체가 다르다. 따라서 이때의 transposed convolution은 normal convolution으로 바꿔서 나타내는 것이 불가능하다.
종종 transposed convolution을 deconvolution이라 부르는 경우가 있는데, deconvolution은 convolution의 역과정이라는 의미인데, 방금 보았듯이 stride가 2 이상이 되면 transposed convolution은 normal convolution과 완전히 다른 연산이 되므로, 역과정이라는 것이 성립하지 않는다. 그렇기 때문에 deconvolution은 틀린 용어라고 보면 된다.
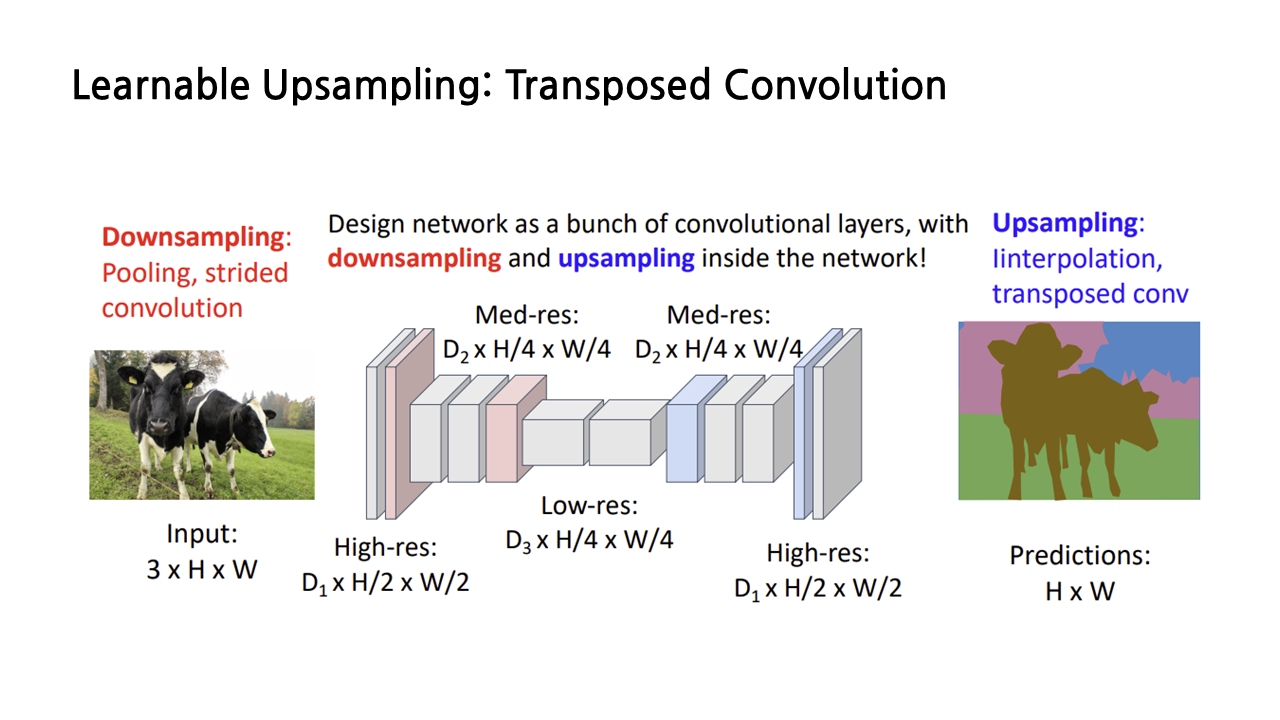
방금까지 본 upscaling 연산은 semantic segmentation의 과정 중에 수행되는 것으로, 앞서 다룬 interpolation, transposed convolution 등 여러 종류 중 적절한 것을 택해서 사용하면 된다.
이후로는 Instance Segmentation 등 새로운 내용이 등장하기 때문에 강의의 남은 부분은 다음 글에서 마저 정리하도록 하겠다.
'놀라운 Deep Learning > Deep Learning for Computer Vision' 카테고리의 다른 글
| [EECS 498-007/598-005] 16강. Detection and Segmentation(3) (1) | 2023.03.03 |
|---|---|
| [EECS 498-007/598-005] 16강. Detection and Segmentation(1) (0) | 2023.02.26 |
| [EECS 498-007/598-005] 9강. Hardware and Software (2) (0) | 2023.02.23 |
| [EECS 498-007/598-005] 9강. Hardware and Software (1) (0) | 2023.02.20 |
| [EECS 498-007/598-005] 3강. Linear Classifier (2) (0) | 2023.01.21 |



