
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- object detection
- image classification
- FORTRAN
- format이 없는 입출력문
- human keypoints
- implicit rule
- algebraic viewpoint
- print*
- cross-entropy loss
- L1 distance
- implicit rules
- geometric viewpoint
- fortran90
- 내장함수
- GNN
- gfortran
- 산술연산
- visual viewpoint
- L2 distance
- cv
- tensor core
- EECS 498-007/598-005
- data-driven approach
- multiclass SVM loss
- parametric approach
- Graph Neural Networks
- computer vision
- Semantic Gap
- cs224w
- feature cropping
- Today
- Total
목록분류 전체보기 (24)
수리수리연수리 코드얍
 [CS224W] 2-3. Traditional Feature-based Methods: Graph
[CS224W] 2-3. Traditional Feature-based Methods: Graph
1. Graph-Level Features Goal: We want features that characterize the structure of an entire graph Background: Kernel Methods Kernel methods란 graph-level prediction을 위한 전통적인 ML에서 보편적으로 쓰이는 방법론이다. 이 방법론의 아이디어는 이름처럼, feature vector 대신 'kernel'을 디자인하자는 것이다. Kernel K(G, G') ∈ R은 두 그래프(G) 사이의 유사도를 측정한다. Kernel matrix K는 항상 positive semi-definite이며(이는 해당 matrix가 항상 양의 eigenvalue를 가짐을 의미)..
 [CS224W] 2-2. Traditional Feature-based Methods: Link
[CS224W] 2-2. Traditional Feature-based Methods: Link
1. Link Prediction as a Task Link prediction task에는 크게 두 가지 종류가 있다. 랜덤하게 사라진 link 찾기(ex. protein-protein interaction network와 같은 static network에 적합) 시간에 따라 생겨나는 link 찾기(ex. citation network, social network, collaboration network...) 이제부터는 어떻게 주어진 pair of nodes에 대해 feature descriptor를 생성할 수 있는지를 알아보도록 하자. pair of nodes x, y에 대해서 몇 가지 score를 비교하는 것이 기본 아이디어가 된다(score의 예시로는 node x, y 간의 common neig..
 [CS224W] 2-1. Traditional Feature-based Methods: Node
[CS224W] 2-1. Traditional Feature-based Methods: Node
1. Traditional ML Pipeline Traditional ML(Machine Learning) Pipeline이란 적절한 feature를 디자인하는 것에 대한 모든 것이라 할 수 있다. feature는 크게 structural feature, attribute feature로 나눌 수 있는데, 이 강의에서는 각각의 node과 자신과 연관 있는 attribute를 가지고 있다고 가정하고, structural feature에만 집중한다. structural feature는 더 넓은 surrounding of the network에 대해 link structure를 표현할 수 있도록 해주고, 관심 있는 node 근처의 이웃 관계를 볼 수 있게 해주며, 전체 그래프의 구조를 파악할 수 있도록 해준다..
 [CS224W] 1-3. Choice of Graph Representation
[CS224W] 1-3. Choice of Graph Representation
1. Components of a Network Objects: nodes, vertices → N Interactions: links, edges → E System: network, graph → G(N, E) Graph는 일반적인 언어이다. 배우와 배우 사이의 관계, 사람과 사람 사이의 관계, 단백질과 단백질 사이의 관계를 나타내는 세 개의 모식도는 모두 우측 아래 검은색 그래프와 같은 공통된 수학적인 표현으로 나타낼 수 있다. 2. Choosing a Proper Representation 당연한 이야기지만, 적절한 graph representation을 선택하는 일은 매우 중요하다. 일례로 같은 개인을 연결하더라도 professional한 관계를 따지느냐, sexual한 관계를 따지느냐에 따라 ..
 [CS224W] 1-2. Applications of Graph ML
[CS224W] 1-2. Applications of Graph ML
1. Different Types of Tasks 지난 글, 1-1. Why Graphs에서도 잠깐 언급한 바 있지만, 그래프에 대한 딥러닝 모델링에서 output인 prediction은 여러 수준에서 이루어질 수 있다. 개별 node level일 수도 있고, edge(pairs of nodes) level일 수도 있고, community(subgraph) level일 수도, graph 혹은 graph generation level일 수도 있다. 아래에서 각각 level에서의 task가 무엇이 있는지, 그 응용 사례에는 어떤 것이 있는지 소개하겠다. Node Classification: predict a property of a node(ex. categorize online users/items) Li..
 [CS224W] 1-1. Why Graphs
[CS224W] 1-1. Why Graphs
※ Machine Learning with Graphs 카테고리의 글 시리즈는 Stanford University의 동명의 강의(CS224W) 내용을 정리한 것입니다. 혹시 오류를 발견하신다면 언제든지 댓글로 알려주시면 감사하겠습니다! 강의 영상: https://www.youtube.com/playlist?list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn Stanford CS224W: Machine Learning with Graphs This course covers important research on the structure and analysis of such large social and information networks and on models and algorith..
 Linear Regression
Linear Regression
1. 지도 학습(Supervised Learning) 라벨(Y, 정답)이 존재하는 학습 방법, 모델에게 정답을 가르쳐주는 학습 방법. 지도 학습에는 크게 '회귀(regression)'와 '분류(classification)'의 두 가지 종류가 있다. 회귀(Regression) 분류(Classification) 변수들 간의 함수적 관계를 탐색 이미 정해진 몇 개의 클래스 라벨 중 하나를 예측 연속형 수치, 연속형 자료 예측 ex) 몸무게로 키 예측 이산형 수치, 범주형 자료 예측 ex) 이메일의 스팸 여부 단순선형회귀분석(Simple Linear Regression) 다중선형회귀분석(Multiple Linear Regression) 이진 분류(binary classification) 다중 분류(multicl..
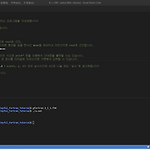 4. Fortran의 산술연산과 format이 없는 입출력문(실전편)
4. Fortran의 산술연산과 format이 없는 입출력문(실전편)
실습 코드: ydduri 깃허브 - Joyful_Fortran_Tutorial 목차 1. format이 없는 입출력문 2. 산술연산 연습하기 3. 내장함수 1. format이 없는 입출력문 1) 세 점수 입력 받아 평균 계산(4_1_1.f90) 전글인 4. Fortran의 산술연산과 format이 없는 입출력문(이론편)에서 format이 없는 입출력문에 대해서 배웠다. format은 입출력의 형태를 지정하는 방식을 이야기하는 것인데, 이번에는 format을 지정하지 않고 입력문, 출력문을 어떻게 작성하는지에 초점을 맞추었다. Fortran에서 입력문은 read, 출력문은 print로 나타낸다. 매우 직관적이다. 그렇다면 입출력문에 format을 지정하지 않겠다는 것을 Fortran에게 어떻게 전달해야 할..
 [EECS 498-007/598-005] 16강. Detection and Segmentation(3)
[EECS 498-007/598-005] 16강. Detection and Segmentation(3)
4. Segmentation: Instance Segmentation 지금까지의 16강에서 object detection, semantic segmentation 등의 내용을 다루었는데, computer vision의 task는 아직 끝나지 않았다. 또다른 segmentation 방법을 소개하기에 앞서 things와 stuff에 대해 정의하고 가도록 하자. object는 크게 things와 stuff로 분류될 수 있는데, things란 instances로 나뉠 수 있는 object, 예를 들면 고양이, 자동차, 사람 등을 의미하고, stuff란 instances로 나뉠 수 없는 object, 일례로 하늘, 풀, 물, 나무 등이 이에 속한다. 지금까지 본 computer vision task 중 objec..
 [EECS 498-007/598-005] 16강. Detection and Segmentation(2)
[EECS 498-007/598-005] 16강. Detection and Segmentation(2)
3. Segmentation: Semantic Segmentation Segmentation에는 여러 종류가 있는데, 첫 번째로 semantic segmentation을 보겠다. 이는 이미지의 각각의 픽셀에 카테고리 label을 붙이는 것이다. Instance를 구분하는 것이 아니라 오직 픽셀에만 집중하기 때문에, 오른쪽 그림에서처럼 두 마리의 소가 붙어 있더라도 이를 소 1, 소 2로 구분하는 것이 아니라 ‘소’라는 하나의 카테고리 라벨로 통칭한다. 1) Sliding Window 강연자께서 semantic segmentation task를 해결하는 ‘멍청한’ 아이디어라고 소개한 내용인데, 바로 sliding window다. 이는 이미지의 각 픽셀에 대해 그 주변부를 포함한 작은 patch를 추출하고,..