
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- EECS 498-007/598-005
- object detection
- computer vision
- L2 distance
- 산술연산
- Graph Neural Networks
- data-driven approach
- algebraic viewpoint
- image classification
- GNN
- implicit rule
- cs224w
- cross-entropy loss
- visual viewpoint
- parametric approach
- feature cropping
- multiclass SVM loss
- human keypoints
- format이 없는 입출력문
- L1 distance
- fortran90
- FORTRAN
- Semantic Gap
- print*
- 내장함수
- gfortran
- implicit rules
- cv
- geometric viewpoint
- tensor core
- Today
- Total
수리수리연수리 코드얍
Linear Regression 본문
1. 지도 학습(Supervised Learning)
라벨(Y, 정답)이 존재하는 학습 방법, 모델에게 정답을 가르쳐주는 학습 방법. 지도 학습에는 크게 '회귀(regression)'와 '분류(classification)'의 두 가지 종류가 있다.
| 회귀(Regression) | 분류(Classification) |
| 변수들 간의 함수적 관계를 탐색 | 이미 정해진 몇 개의 클래스 라벨 중 하나를 예측 |
| 연속형 수치, 연속형 자료 예측 ex) 몸무게로 키 예측 |
이산형 수치, 범주형 자료 예측 ex) 이메일의 스팸 여부 |
| 단순선형회귀분석(Simple Linear Regression) 다중선형회귀분석(Multiple Linear Regression) |
이진 분류(binary classification) 다중 분류(multiclass classification) |
지도 학습을 할 때, 데이터를 받으면 우선 우리가 해야 하는 task가 무엇인지(회귀인지 분류인지) 명확히 해야 한다. 이후에 어떤 방법론을 사용할 것인지를 결정한다. task에 따라 어떤 방법론을 사용할 것인지가 달라진다.
- 회귀일 경우: linear regression, ridge, lasso...
- 분류일 경우: SVM, logistic regression
2. 회귀분석(Regression)
회귀분석(Regression)이란 변수들 사이의 함수적 관계를 탐색하는 과정이다.
- X(독립, 설명변수): 다른 변수에 영향을 주는 변수
- Y(종속, 반응변수): 다른 변수로부터 영향을 받는 변수
이때 Y가 supervised(지도식)이면서 연속형 자료라면 회귀분석을 이용하면 좋다.
1) 선형회귀분석(Linear Regression)
선형회귀분석(Linear Regression)이란 회귀분석의 일종이다. 회귀분석은 크게 선형회귀분석과 비선형회귀분석으로 나뉘는데, 그중 선형회귀분석은 독립변수와 종속변수 간 선형 상관관계를 모델링하는 기법이다. 데이터들에 가장 가까운 선형식(hyperplane $\widehat{y} = \beta_0 + \beta_1x_1 + ... + \beta_kx_k$)을 찾는 것이 선형회귀분석의 목표이다.
(1) 단순선형회귀(Simple Linear Regression)
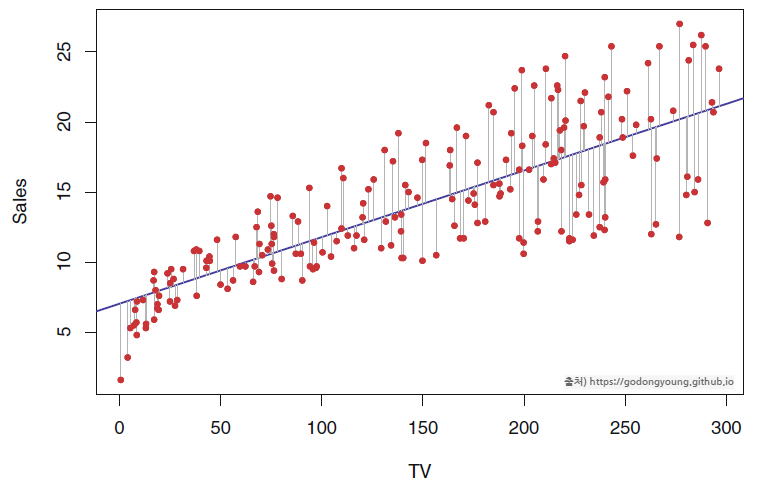
독립변수 1개로 종속변수를 예측하는 선형회귀분석의 일종. 입력 데이터($x$)가 1개인 경우, 출력 데이터($\widehat{y}$)는 y절편이 $\beta_0$, 기울기가 $\beta_1$인 1차 함수로 표현할 수 있다. 이때 출력 데이터($\widehat{y}$)에서 y 위에 모자처럼 얹어진 기호를 실제로도 'hat'이라 하는데, 이는 '추정치'라는 의미이다.
$\widehat{y} = \beta_0 + \beta_1x_1$
이때, $\beta_0$, $\beta_1$: 회귀계수(학습 파라미터)
(2) 다중선형회귀(Multiple Linear Regression)
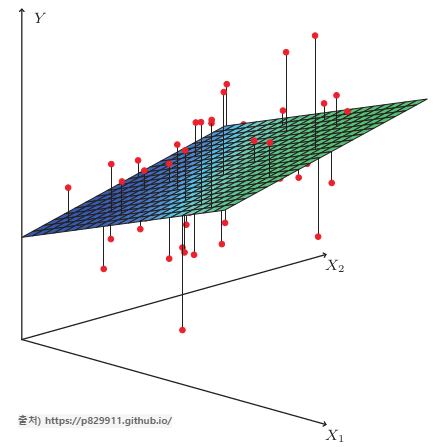
독립변수 여러 개로 종속변수를 예측하는 선형회귀분석의 일종. 독립변수(입력 데이터 $x$)가 여러 개인 경우 아래와 같이 절편과 기울기로 이루어진 초평면(hyperplane)의 식을 통해 회귀 모델을 설정할 수 있다. 예를 들어 특성($x$)이 2개일 경우, 회귀 모델은 3차원 공간에 있는 데이터를 설명하는 평면이 된다.
$\widehat{y} = \beta_0 + \beta_1x_1 + ... + \beta_kx_k$
이때, $\beta_0$, $\beta_1$, $\beta_2$, ..., $\beta_k$: 회귀계수(학습 파라미터)
2) 회귀계수 $\beta$를 추정하는 방법
회귀분석을 통한 우리의 목표는 입력 데이터 $x$가 주어졌을 때 출력 데이터 $\widehat{y}$를 추정하는 것이다. 그런데 위 식들을 통해 $\widehat{y}$를 추정하기 위해서는 $\beta$들, 즉 회귀계수들을 알아야 한다. 그렇다면 회귀계수 $\beta$는 어떻게 추정할 수 있을까? 그 방법은 크게 아래와 같다.
- 최소제곱법(Ordinary Least Squares Method, OLS)
- 정규방정식을 이용
- 특잇값 분해로 유사역행렬을 구하여 정규방정식을 변형
- 경사 하강법(Gradient Descent, GD)
- 최대우도법(Maximum Likelihood Estimation, MLE)
이제 각각의 방법에 대해 보다 자세하게 살펴보도록 하자.
(1) 최소제곱법(OLS)
최소제곱법은 말그대로 제곱 값이 최소가 되도록 하는 회귀계수를 찾는다는 뜻으로, 여기서 제곱 값이란 잔차제곱합(Sum of Squared Errors, SSE)을 의미한다. 잔차란 실제 출력변수와 예측한 출력변수의 차이, 즉 오차이므로 최소제곱법의 의미는 결국 오차를 최소화하는 회귀계수를 찾는다는 뜻으로 귀결된다.
- 잔차(residual): 실제 출력변수와 예측한 출력변수의 차이, $$e_i = y_i - \widehat{y}_i$$
- 잔차제곱합(Sum of Squared Errors, SSE), $$SSE = \sum_{i=1}^{n}{e_i}^{2} = \sum_{i=1}^{n}({y_i-\widehat{y}_i})^{2}$$
- 평균제곱오차(Mean of Squared Errors, MSE), $$MSE = \frac{1}{n-k-1}\sum_{i=1}^{n}{e_i}^{2} = \frac{1}{n-k-1}\sum_{i=1}^{n}({y_i-\widehat{y}_i})^{2}$$
이때 n은 총 데이터의 수, k는 독립변수의 개수(선형회귀식이 몇 차원인지 나타내는 값으로, 독립변수가 1개라면 2차원 평면에 선형회귀식을 직선으로 나타낼 수 있고, 독립변수가 2개라면 3차원 공간에 선형회귀식을 평면으로 나타낼 수 있다)이다.
① 정규방정식 이용
최소제곱법을 적용하는 첫 번째 방법은 정규방정식을 이용하는 것이다. 최소제곱법을 통한 우리의 목표, 즉 '잔차제곱합(SSE)'을 최소화하는 회귀계수 $\beta$ 값을 찾자'를 식으로 표현하면 아래와 같다. $$\underset{\beta}{min}\sum_{i=1}^{n}({y_i-\widehat{y}_i})^{2}$$
이제 우리는 위와 같은 목표를 달성하기 위해 SSE로부터 $\beta$에 대한 정규방정식을 이끌어낼 것이다. 그 과정은 다음과 같다.

위와 같은 유도 과정을 통해 우리는 최종적으로 정규방정식 $\mathbf{\widehat{\beta}} = (\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\mathbf{y}$을 구해낼 수 있다.
② 특잇값 분해로 유사역행렬을 구하여 정규방정식을 변형
정규방정식은 비교적 어렵지 않은 수식적 아이디어를 이용해 회귀계수를 찾을 수 있게 해준다는 장점이 있지만, 대표적인 단점이 두 가지 존재한다.
- 모델이 복잡해질수록 연산 시간이 크게 증가한다.
- $(\mathbf{X}^{T}\mathbf{X})$의 역행렬을 구할 수 없을 때 사용할 수 없다(실제로 정규방정식 유도의 마지막 부분에서 역행렬이 존재하는 경우에만 최종적으로 $\mathbf{\widehat{\beta}}$에 대한 식을 끌어낼 수 있었다).
그래서 우리는 이러한 단점을 해결하기 위해, 특잇값 분해를 이용해서 유사역행렬을 구하고, 기존 정규방정식을 변형해볼 것이다. 역행렬은 기본적으로 n*n 형태의 정방 행렬(sqaure matrix)에서만 정의되는데, 정방 행렬이 아닌 다른 모양의 행렬에 대해서는 '유사역행렬'을 적용할 수 있다. 다시 말해, 유사역행렬은 역행렬과 달리 항상 구할 수 있는 것이다. 유사역행렬의 또다른 장점으로는 정규방정식을 이용한 ①번 방법보다 계산 복잡도가 낮다는 점도 있다.
유사역행렬이란?
$Ax = I$ 식을 만족하는 벡터 $x$를 구하기 위해 우리는 $A$의 역행렬인 $A^{-1}$을 양변에 곱하여, $$A^{-1} A x = A^{-1} I$$와 같은 방식으로 $x$를 찾곤 했다. 그런데 이처럼 $A$의 역행렬을 구하기 위해서는 $A$가 $n*n$ 꼴의 정사각 행렬이어야만 한다. 만약 $m*n$ 꼴의 비정사각 행렬인 $A$에 대해서 $x$를 구하고 싶다면 어떻게 해야 할까? 이럴 때 사용하는 것이 바로 유사역행렬이다. $$A^T A x = A^T$$우선 위와 같이 식의 양변에 A의 transpose를 곱해줌으로써 $A$를 억지로 $n*n$의 정사각 행렬로 만들어준다. $A$가 $m*n$ 꼴이라면 $A$의 tranpose인 $A^T$는 $n*m$ 꼴을 가지고 있을 텐데, 위의 식처럼 곱할 경우 결과적으로 $n*n$의 정사각 행렬이 만들어지게 된다. 그런 다음, $$(A^T A)^{-1} A^T A x = (A^T A)^{-1} A^T$$ 위와 같이 $A^T A$ 전체에 대한 역행렬을 곱해주면 마침내 우리는 식을 원하던 대로 $x$에 대해서 정리할 수 있게 된다. $$x=(A^T A)^{-1} A^T$$ 이때 우변에 위치한 $(A^T A)^{-1} A^T$ 이러한 형태가 바로 유사역행렬이다(여기서는 $A$의 유사역행렬). 유사역행렬은 + 첨자를 붙여서 나타내며, 여기서처럼 $A$의 유사역행렬을 구한 경우 $A^+$로 표시한다.
앞서 구한 정규방정식 $\mathbf{\widehat{\beta}} = (\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\mathbf{y}$을 보면, 우변에 $(\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}$ 이렇게 유사역행렬 형태가 들어 있는 것을 확인할 수 있다. 이를 유사역행렬 $\mathbf{X}^+$로 대체하면 다음과 같이 나타낼 수 있다. $$\mathbf{\widehat{\beta}} = \mathbf{X}^+ \mathbf{y}$$ 그리하여 좀 더 확장성이 증가하는 방향으로 정규방정식을 변형시킬 수 있다.
③ 경사하강법
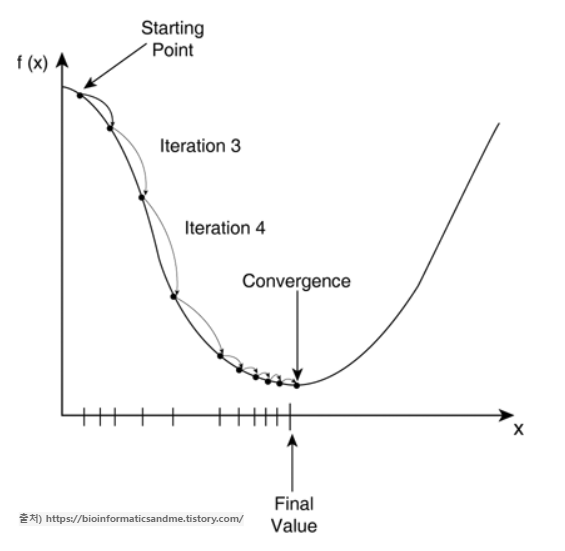
딥러닝이나 머신러닝을 공부한 경험이 있으신 분들은 딥러닝에서 등장하던 용어가 여기서 나타난 것에 의아할 수도 있겠다. 경사하강법은 딥러닝에서 손실함수를 최소화하기 위해 매개변수를 반복적으로 조정하는 과정을 말하는데, 이때 딥러닝에서의 '회귀 손실함수'가 곧 머신러닝에서의 '선형회귀 목적함수'에 대응된다.
그렇기 때문에 딥러닝에서 다루는 경사하강법은 머신러닝에서도 적용할 수 있고, 반복적인 학습을 통해 모델의 최적 파라미터를 찾는 것이 머신러닝에서의 경사하강법의 목표라 할 수 있다.