
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Semantic Gap
- geometric viewpoint
- format이 없는 입출력문
- multiclass SVM loss
- L2 distance
- visual viewpoint
- GNN
- computer vision
- object detection
- data-driven approach
- cv
- EECS 498-007/598-005
- gfortran
- algebraic viewpoint
- human keypoints
- implicit rule
- print*
- tensor core
- FORTRAN
- Graph Neural Networks
- parametric approach
- implicit rules
- fortran90
- image classification
- cs224w
- 내장함수
- cross-entropy loss
- L1 distance
- feature cropping
- 산술연산
- Today
- Total
수리수리연수리 코드얍
[CS224W] 2-1. Traditional Feature-based Methods: Node 본문
[CS224W] 2-1. Traditional Feature-based Methods: Node
ydduri 2023. 9. 3. 14:311. Traditional ML Pipeline
Traditional ML(Machine Learning) Pipeline이란 적절한 feature를 디자인하는 것에 대한 모든 것이라 할 수 있다. feature는 크게 structural feature, attribute feature로 나눌 수 있는데, 이 강의에서는 각각의 node과 자신과 연관 있는 attribute를 가지고 있다고 가정하고, structural feature에만 집중한다. structural feature는 더 넓은 surrounding of the network에 대해 link structure를 표현할 수 있도록 해주고, 관심 있는 node 근처의 이웃 관계를 볼 수 있게 해주며, 전체 그래프의 구조를 파악할 수 있도록 해준다. 우리는 이러한 feature를 ML model에 feed함으로써 예측을 생성해낼 수 있다.
전통적인 ML Pipeline에는 두 가지 단계가 있다.
- 우리의 data points, nodes, links, entire graph를 feature vector로 변환해 랜덤 포레스트, SVM, feed-forward neural network 등 classical ML 모델을 학습시킴
- 위에서 학습시킨 모델을 새로운 node, link, graph에 적용하여 예측을 생성함
graph에 대한 effective features를 사용하는 것은 좋은 테스트 성능을 발휘하는 key라고 할 수 있다. Traditional ML pipeline에서는 위에서 살펴본 바와 같이 hand-designed feature를 사용했다. 이번 강의에서는, 이러한 traditional feature를 node-level, link-level, graph-level 등 다양한 level에서의 prediction에 대해서 살펴볼 것이다. simplicity를 위해, undirected graph에 초점을 두어 살펴볼 예정이다.
2. Machine Learning in Graphs
Goal: Make predictions for a set of objects
Design choices:
- Features: d-dimensional vectors
- Objects: Nodes, edges, sets of nodes, entire graphs
- Objective function: What task are we aiming to solve?
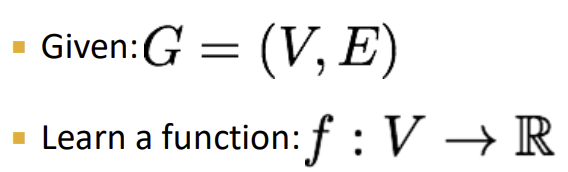
우리의 목표는 function을 학습시키는 것이다. 예를 들면, 각각의 node에 대해 real valued prediction을 생성하는 위와 같은 함수 f가 있을 수 있겠다. 적절한 prediction을 생성하기 위한 함수 f를 어떻게 찾을 것인가? 이것이 우리가 풀어야 할 질문이다.
3. Node-level Tasks
1) Node-Level Features: Overview
Goal: Characterize the structure and position of a node in the network
이를 위해 사용할 수 있는 접근법은 아래와 같다. 앞으로 각각의 접근법에 대해서 자세히 살펴볼 예정이다.
- Node degree
- Node centrality
- Clustering coefficient
- Graphlets
2) Node Features: Node Degree
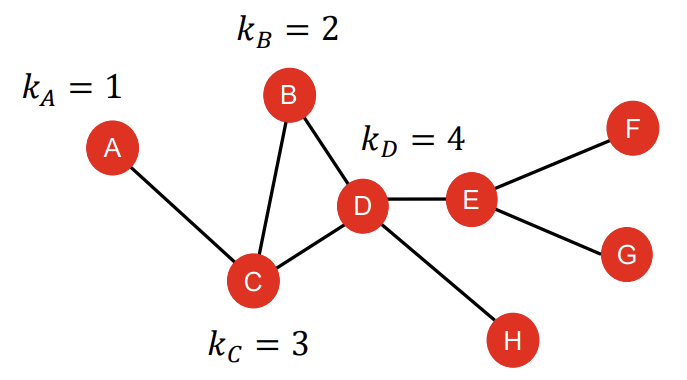
Node degree에 대해서는 지난 강의 1-3. Choice of Graph Representation에서 이미 살펴본 바 있기에, 개념적인 설명은 건너뛰도록 하겠다. 다만 ML model을 구축하는 데 있어서 node degree가 가지는 단점이 있는데, node degree가 같은 node가 있을 때, ML model이 그들끼리 잘 구분하지 못한다는 것이다. 일례로, 아래 그래프 예시에서 node C와 E는 모두 node degree가 3으로 같다. node A, F, G, H도 node degree가 1로 같다. 우리가 눈으로 볼 때는 이들 각각이 다른 node라는 것을 알지만, ML model 입장에서는 같은 node degree를 가지기 때문에 이들 사이를 구분하기가 어렵고, 같은 feature value를 부여하게 된다. 이는 같은 node degree를 가지는 node에 대해서 같은 예측을 생성할 수 있다는 문제로 이어진다.
3) Node Features: Node Centrality
위에서 살펴본 바와 같이, node degree가 각 node의 이웃의 개수만 count하고, 각각의 node가 정녕 무엇인지는 포착하지 못한다는 문제점을 해결하기 위해 등장한 것이 node centrality이다. node centrality는 '해당 node가 이 그래프에서 얼마나 중요한가?'에 대한 notion을 포함한다. node의 중요도를 model하는 방법은 아래와 같이 여러가지가 있을 수 있다.
(1) Eigenvector Centrality
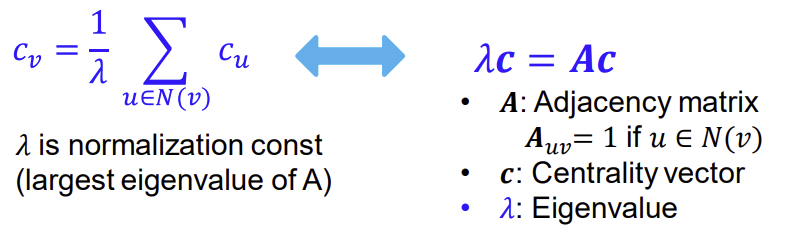
중요한 node와 더 많이 이웃해 있는 node가 중요한 node다! 라는 아이디어를 기반으로 한다. 이를 수식으로 나타내면 아래의 왼쪽 식과 같다. 이는 어떤 node의 중요도는 이것과 연결되어 있는 node들의 중요도의 normalized sum과 같다는 의미이다. 이 식은 오른쪽의 eigenvalue-eigenvector problem처럼 변형이 가능하다. 이 equation을 풀면, Perron-Frobenius Theorem에 의해 largest eigenvalue $\lambda_{max}$는 항상 positive하고 unique하게 된다. 그리고 leading eigenvector인 $C_{max}$가 centrality를 나타내는 지표로서 쓰이게 된다.
(2) Betweenness Centrality
어떤 node가 교통의 중심지라면 중요한 node라는 아이디어다. 즉, 다른 node와의 최단 경로가 많은 node가 중요한 node라고 보는 아이디어이다. 이를 식으로 나타내면, 어떤 node v의 centrality는 해당 node v를 포함하는 다른 node s, t 사이의 shortest path의 개수를, s와 t 사이의 total number of shortest paths로 normalize함으로써 구할 수 있다.

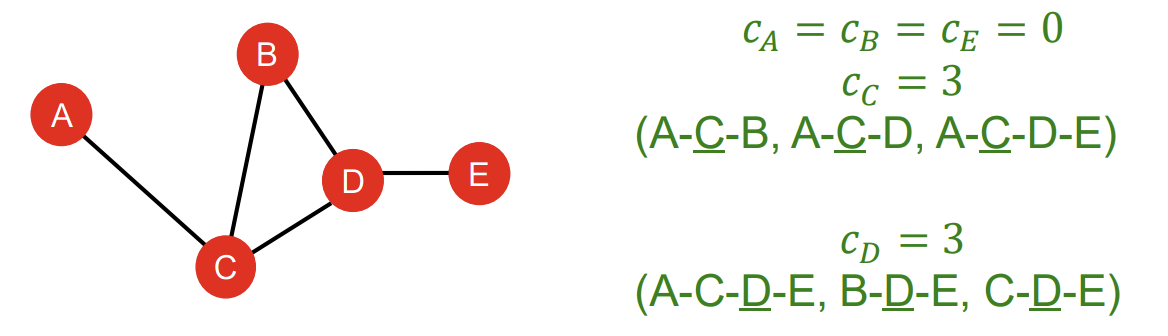
글로만 설명하면 잘 안 와닿으니 예시를 보도록 하겠다. Betweenness Centrality 관점에서 봤을 때, node A, B, E의 centrality는 0으로 같다. 반면 node C의 centrality는 3인데, A에서 B로 가는 최단 경로가 C를 거쳐야 하고, A에서 D로 가는 최단 경로도 C를 거쳐야 하며, A에서 E로 가는 최단 경로도 C를 거쳐야 하기 때문에 3이라는 숫자가 나온 것이다. 마찬가지로 D의 centrality 또한 3이다. B에서 E로 가는 최단 경로가 D를 거치며, C에서 E로 가는 최단 경로도 D를 거치고, A에서 E로 가는 최단 경로도 D를 거치기 때문이다.
(3) Closeness Centrality
다른 모든 node와의 최단 경로 길이의 합이 작을수록 중심에 위치한 node일 확률이 크고, 따라서 더 중요하다는 아이디어이다. 식은 1 나누기 다른 모든 node와의 최단 경로 길이의 합으로 매우 간단하다.
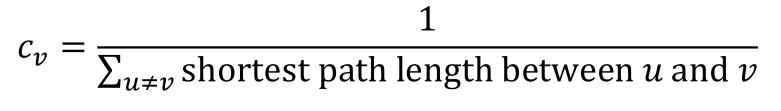
여기서 또한 예시를 보도록 하겠다. node A의 경우 B로 가기 위해서는 2개의 edge, C로 가기 위해서는 1개의 edge, D로 가기 위해서는 2개의 edge, E로 가기 위해서는 3개의 edge를 거쳐야 한다(각 edge의 길이는 1이라고 가정하는 듯하다). 이들의 합이 분모에 들어가고, node A의 closeness centrality는 1/8이 된다. node D의 경우 A로 가기 위해서는 2개의 edge, 나머지 B, C, E와는 직접 연결되어 있기에 하나의 edge만 거치면 되기 때문에, 1/5의 closeness centrality를 가지게 된다. closeness centrality 관점에서는 node A보다 D가 더 중요한 node인 것이다.
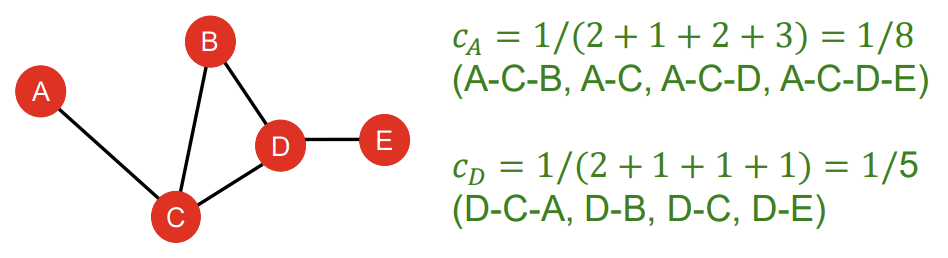
4) Node Features: Clustering Coefficient
Clustering Coefficient는 어떤 node의 이웃들끼리 얼마나 연결되어 있는가를 측정한다. 식은 어떤 node v의 이웃 간 연결된 경우의 수를 이웃 node끼리 서로 짝을 지어 연결될 수 있는 전체 경우의 수로 나누어준다는 뜻이다. 이웃 노드끼리 모두 연결되어 있으면 clustering coefficient가 1, 모두 연결되어 있지 않다면 0이 된다.
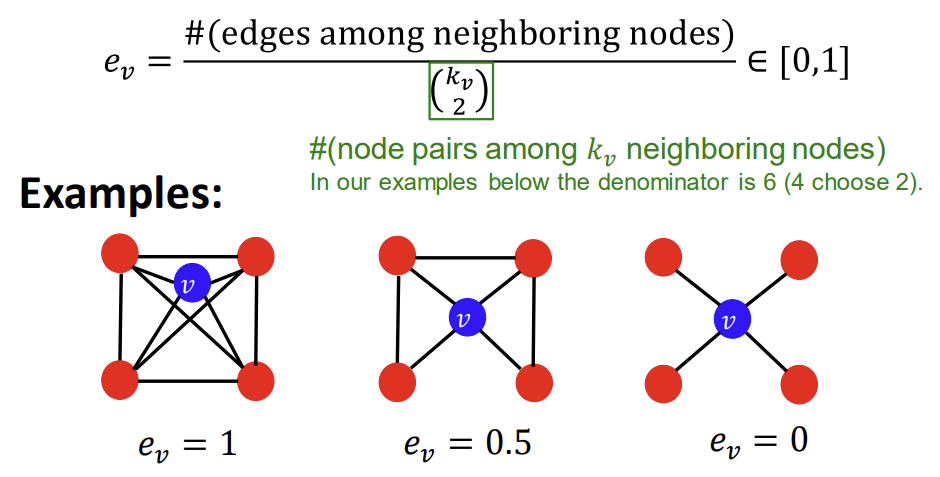
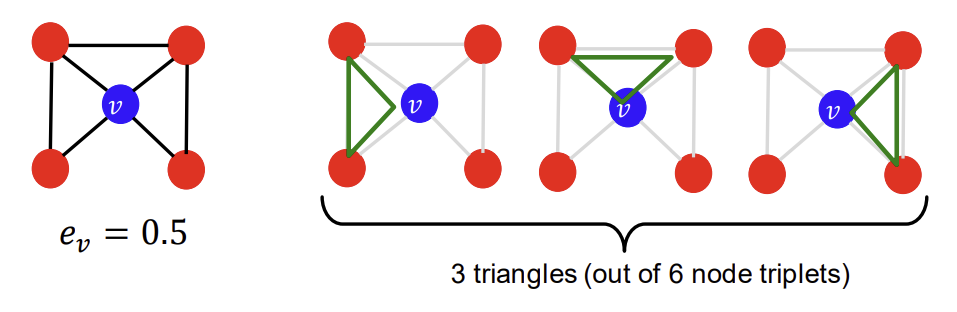
재미있는 점은, clustering coefficient를 ego-network(clustering coefficient를 따지고자 하는, 관심 있는 node v를 포함하는 네트워크)에서의 삼각형의 개수를 셈으로써 구할 수도 있다는 것이다. 우리는 이를 pre-specified subgraph의 개수를 세는 것으로 일반화할 수 있는데, 이것이 바로 다음에서 살펴볼 Graphlets의 개념이다.
5) Node Features: Graphlets
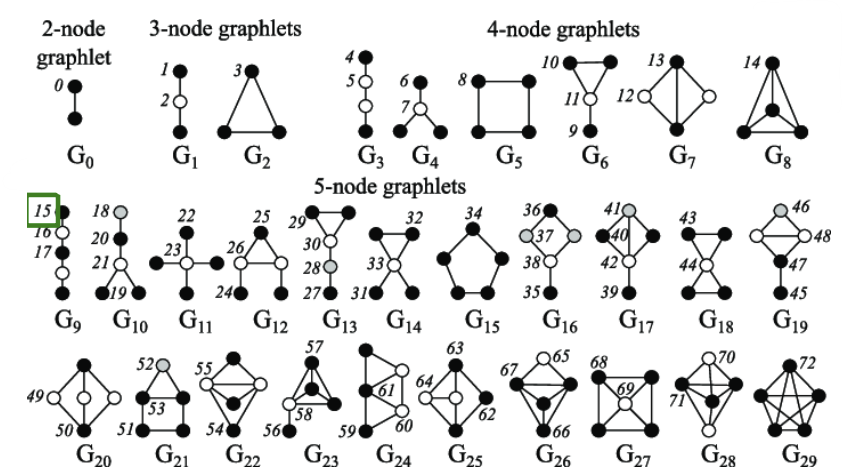
Graphlets란 rooted connected non-isomorphic(같은 모양이 아닌) subgraphs라 할 수 있다. 아래 그림은 node 개수에 따라 가능한 graphlets의 모양을 나열한 것이다.
graphlets에 대해 이야기할 때 빠질 수 없는 중요한 개념이 'Graphlet Degree Vector(GDV)'이다. 이는 우리가 관심 있는 node에 대하여, 해당 node를 포함하는 graphlets이 몇 번이나 나타나는지를 벡터로 표현한 것이다. 아래의 예시를 보면 쉽게 이해할 수 있다. 우리가 관심 있는 node u가 각각 graphlet의 a, b, c, d node라고 할 때 각각의 graphlets에 대해서 케이스가 몇 개씩 나타나고 있는가를 벡터로 나타내면 [2, 1, 0, 2]가 된다.
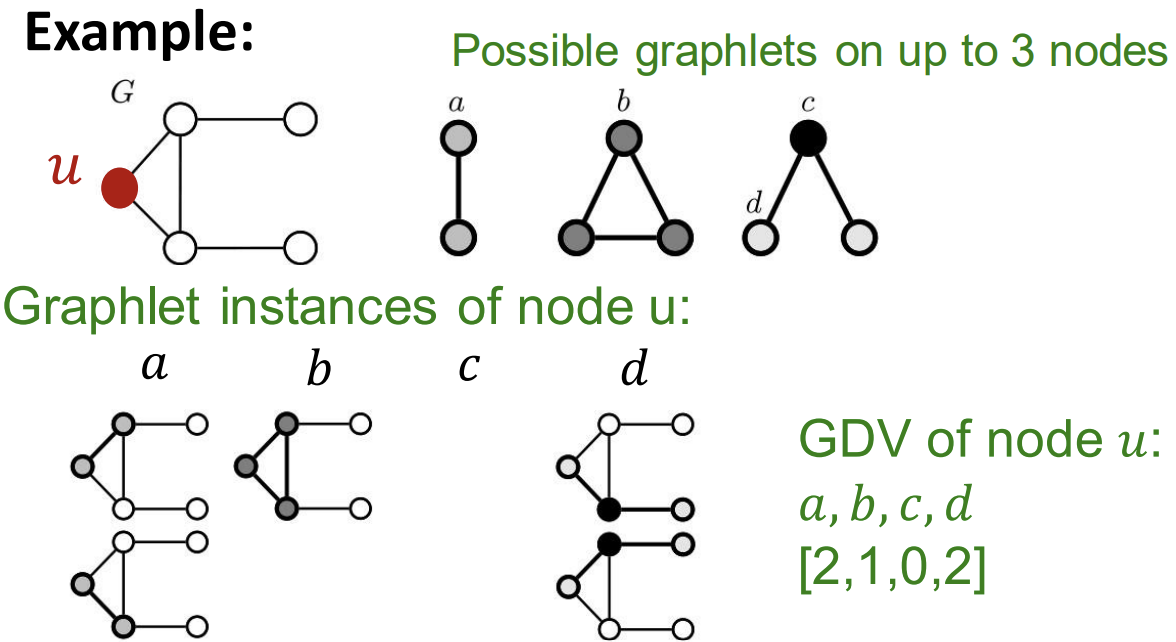
정리하자면, 2~5개의 Node가 참여하는 Graphlet의 갯수는 73개이다. 이를 73차원의 벡터로 표시할 수 있다. 이는 node의 이웃들에 대한 topology를 표현하는 signature라 할 수 있다. Graphlet degree vector는 node의 local network topology에 대한 measure를 제공한다.
'놀라운 Deep Learning > Machine Learning with Graphs' 카테고리의 다른 글
| [CS224W] 2-3. Traditional Feature-based Methods: Graph (0) | 2023.09.04 |
|---|---|
| [CS224W] 2-2. Traditional Feature-based Methods: Link (0) | 2023.09.04 |
| [CS224W] 1-3. Choice of Graph Representation (0) | 2023.08.27 |
| [CS224W] 1-2. Applications of Graph ML (0) | 2023.08.27 |
| [CS224W] 1-1. Why Graphs (1) | 2023.08.27 |



