
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- data-driven approach
- parametric approach
- format이 없는 입출력문
- algebraic viewpoint
- image classification
- computer vision
- L2 distance
- human keypoints
- Semantic Gap
- tensor core
- cross-entropy loss
- GNN
- feature cropping
- L1 distance
- cv
- Graph Neural Networks
- fortran90
- implicit rule
- cs224w
- print*
- visual viewpoint
- object detection
- FORTRAN
- gfortran
- implicit rules
- 산술연산
- geometric viewpoint
- 내장함수
- multiclass SVM loss
- EECS 498-007/598-005
- Today
- Total
수리수리연수리 코드얍
[CS224W] 2-2. Traditional Feature-based Methods: Link 본문
[CS224W] 2-2. Traditional Feature-based Methods: Link
ydduri 2023. 9. 4. 12:231. Link Prediction as a Task
Link prediction task에는 크게 두 가지 종류가 있다.
- 랜덤하게 사라진 link 찾기(ex. protein-protein interaction network와 같은 static network에 적합)
- 시간에 따라 생겨나는 link 찾기(ex. citation network, social network, collaboration network...)
이제부터는 어떻게 주어진 pair of nodes에 대해 feature descriptor를 생성할 수 있는지를 알아보도록 하자. pair of nodes x, y에 대해서 몇 가지 score를 비교하는 것이 기본 아이디어가 된다(score의 예시로는 node x, y 간의 common neighbor의 개수 등이 있을 수 있다).
- 각 node 쌍 (x, y)에 대하여 score c(x, y)를 계산한다.
- c(x, y) 내림차순으로 node 쌍을 정렬한다.
- top N개의 pair들을 새로운 link로 예측한다.
2. Link-Level Features
1) Overview
link-level features를 잡아 내는 방법에는 크게 아래와 같은 종류가 있다. 앞으로 각각의 접근법에 대해서 자세히 살펴볼 예정이다.
- Distance-based feature
- Local neighborhood overlap
- Global neighborhood overlap
2) Distance-Based Features
이는 두 node 사이의 가장 짧은 path의 거리를 기반으로 characterize하는 방법이다. 다만 이 방법은 두 node간 최단 경로의 거리를 사용할 뿐, 이웃의 수나 강도에 대한 어떠한 정보도 capture하지 않는다.
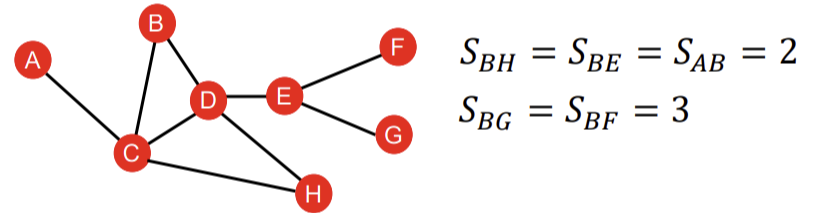
3) Local Neighborhood Overlap
두 node간 connection의 강도를 capture하기 위해 도입된 방법이 바로 local neighborhood overlap이다. 얼마나 많은 이웃을 공통으로 가지고 있는지를 본다.
- Common neighbors: 단순히 두 node간 이웃의 개수(교집합)를 구한다.
- Jaccard's coefficient: 교집합의 크기를 합집합으로 나눠 normalize한다.
- Adamic-Adar index: 두 node가 공유하는 이웃을 u라고 할 때, u의 degree에 log를 취한 값으로 나눠서 구할 수 있으며, social network에서 잘 동작한다.
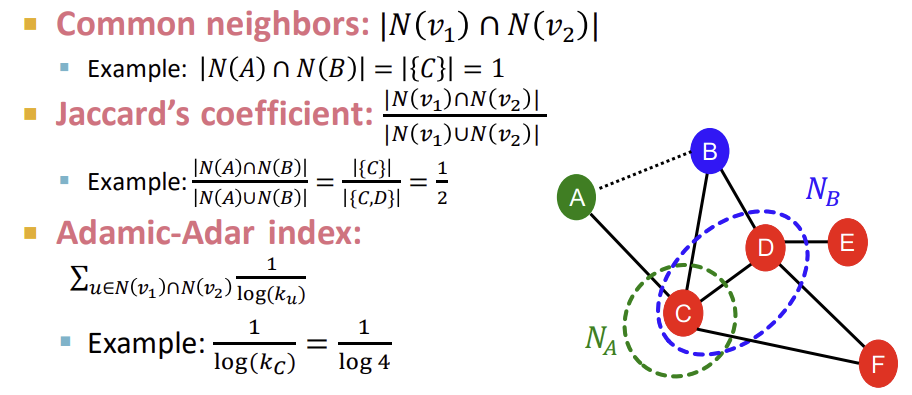
local neighborhood overlap의 단점은 직접적인 공통 이웃이 없으면 무조건 0이 나온다는 점이다. 아래의 예시를 보면, node A와 node E는 직접적인 공통 이웃이 없기 때문에 교집합을 구했을 때 0이 나올 수밖에 없다. 그러나 실제 세계에서 두 node A, E는 미래에 연결될 수도 있는 잠재력을 가지고 있다. 단순히 local neighborhood overlap을 사용하는 것만으로는이러한 미래의 잠재력까지 고려하기는 어렵다는 한계가 있다.
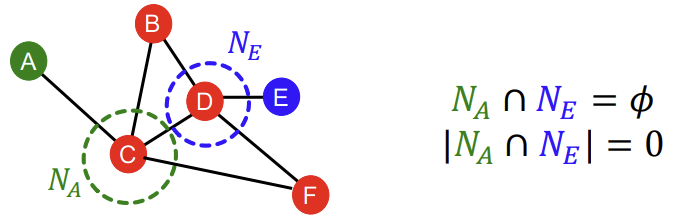
4) Global Neighborhood Overlap
위에서 언급한 local neighborhood overlap의 단점을 해결하기 위해 등장한 것이 바로 global neighborhood overlap이다. 이는 이름처럼, 직접적인 공통 이웃만을 고려하는 'local' 방식과는 달리, 'global'하게 entire graph를 고려하고자 하는 방식이다. 대표적으로 쓰이는 것이 Katz index이다.
Katz index: 주어진 node 쌍을 잇는 모든 길이의 경로의 개수를 센다. 1-3. Choice of Graph Representation에서 배운 adjacency matrix를 이용하면 이를 쉽게 계산할 수 있다.
- adjacency matrix $A_{uv}$는 직접 이웃일 때 1, 아니면 0이다.
- $P_{uv}^{(K)}$는 K길이의 u, v를 잇는 경로이다.
- $P_^{(K)}$ = $A^k$이다.
$P_{uv}^{(2)}$를 계산하는 예시를 보자. 이는 두 단계로 나눠서 접근할 수 있다.
- Step 1: Compute number of walks of length 1 between each of u's neighbor and v
- Step 2: Sum up these number of walks across u's neighbors
이를 수식적으로 접근한 결과는 아래와 같다.
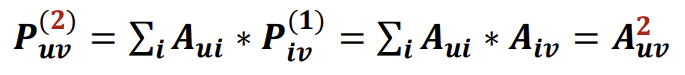
adjacency matrix를 이용해서 행렬 연산으로 시각화해보면 아래와 같다.
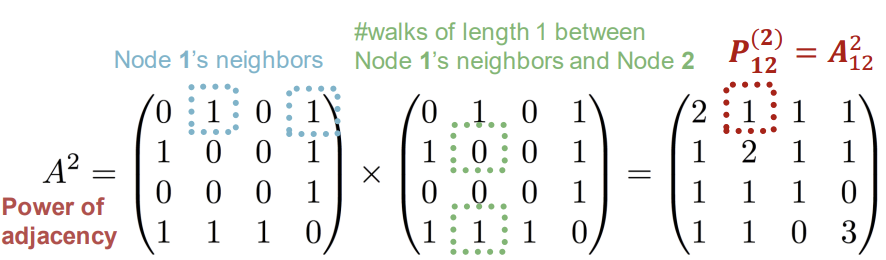
앞서 adjacency matrix를 이용하면 계산이 쉬워진다고 했는데, 도대체 어디가 쉬워진 걸까? 바로 두 node 사이의 number of walks 계산을 adjacency matrix의 거듭제곱으로 나타낼 수 있다.
- $A_{uv}$ specifies #walks(number of walks) of length 1(direct neighborhood) between u and v
- $A_{uv}^{2}$ specifies #walks of length 2(neighbor of neighbor) between u and v
- $A_{uv}^{l}$ specifies #walks of length l
이를 이용해서 Katz index 식을 정리해보면 아래와 같다. 이는 또한 geometric series of matrices 수식을 활용해 closed-form으로도 나타낼 수 있다.
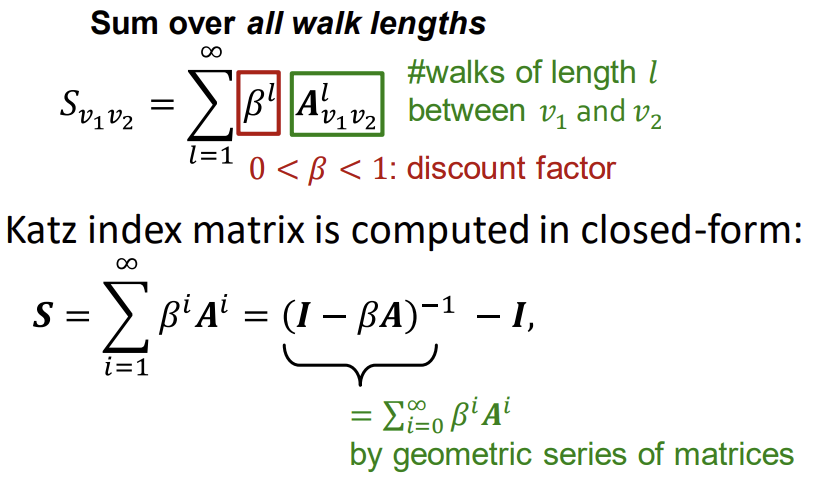
※ 참고: Geometric series of matrices
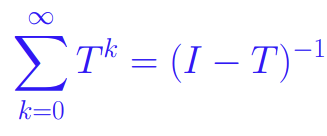
이때, $S_n = I + T + ... + T^{n-1}$에서 $S_0 = I$이기 때문에, 위의 Katz index in closed form의 경우 i=0이 아닌 1부터 시작하고 있어서 I를 빼 준 것.
'놀라운 Deep Learning > Machine Learning with Graphs' 카테고리의 다른 글
| [CS224W] 2-3. Traditional Feature-based Methods: Graph (0) | 2023.09.04 |
|---|---|
| [CS224W] 2-1. Traditional Feature-based Methods: Node (0) | 2023.09.03 |
| [CS224W] 1-3. Choice of Graph Representation (0) | 2023.08.27 |
| [CS224W] 1-2. Applications of Graph ML (0) | 2023.08.27 |
| [CS224W] 1-1. Why Graphs (1) | 2023.08.27 |



