
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- cs224w
- Semantic Gap
- 산술연산
- implicit rule
- cross-entropy loss
- multiclass SVM loss
- 내장함수
- geometric viewpoint
- print*
- image classification
- gfortran
- data-driven approach
- visual viewpoint
- tensor core
- cv
- EECS 498-007/598-005
- L1 distance
- object detection
- L2 distance
- format이 없는 입출력문
- human keypoints
- GNN
- FORTRAN
- computer vision
- feature cropping
- algebraic viewpoint
- implicit rules
- parametric approach
- Graph Neural Networks
- fortran90
- Today
- Total
수리수리연수리 코드얍
[CS224W] 1-3. Choice of Graph Representation 본문
[CS224W] 1-3. Choice of Graph Representation
ydduri 2023. 8. 27. 20:121. Components of a Network
- Objects: nodes, vertices → N
- Interactions: links, edges → E
- System: network, graph → G(N, E)
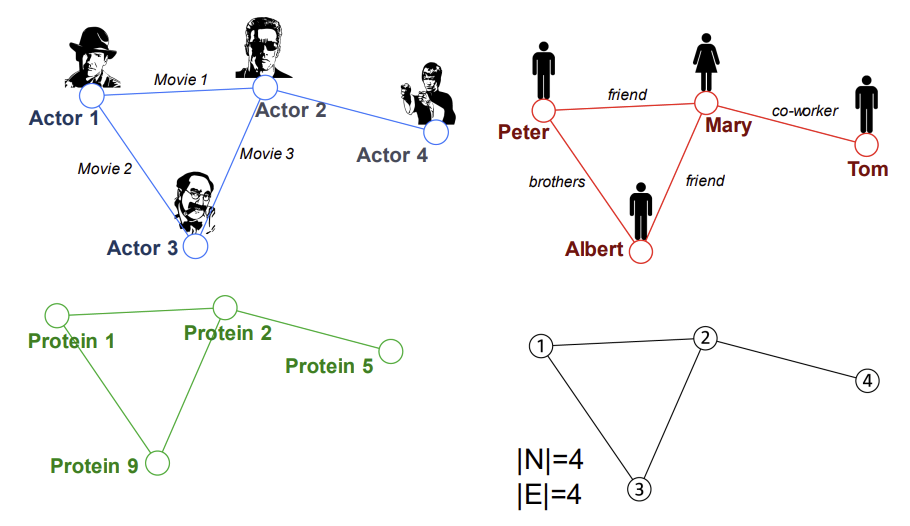
Graph는 일반적인 언어이다. 배우와 배우 사이의 관계, 사람과 사람 사이의 관계, 단백질과 단백질 사이의 관계를 나타내는 세 개의 모식도는 모두 우측 아래 검은색 그래프와 같은 공통된 수학적인 표현으로 나타낼 수 있다.
2. Choosing a Proper Representation
당연한 이야기지만, 적절한 graph representation을 선택하는 일은 매우 중요하다. 일례로 같은 개인을 연결하더라도 professional한 관계를 따지느냐, sexual한 관계를 따지느냐에 따라 네트워크의 종류는 달라지게 된다. 그렇기에 node가 무엇인지, link가 무엇인지를 결정하는 게 중요한 것이다. 데이터셋이 주어졌을 때, 우리는 우선 underlying graph를 어떻게 디자인할 것인지를 결정해야 한다. interest nodes에 대응하는 객체는 무엇이 될 것인지, 그들 사이의 관계는 어떻게 되며 그렇다면 edge는 무엇이 될 것인지를 정해야 한다. 적절한 graph representation을 결정하는 일이, 네트워크를 얼마나 성공적으로 활용할 수 있을지를 좌우한다.
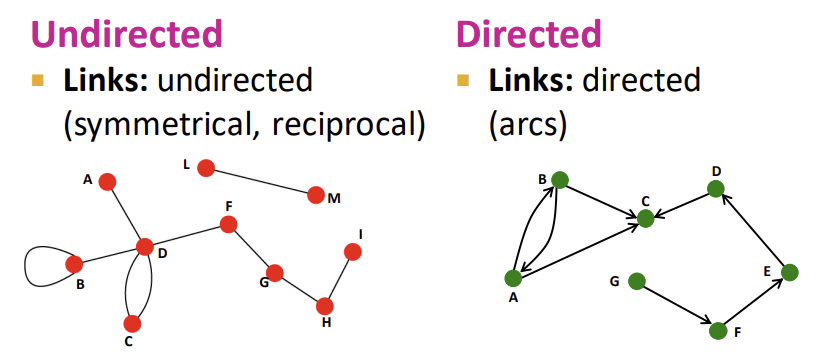
1) Directed vs. Undirected Graphs
- Undirected: symmetric(대칭적인), reciprocal(상호간의) 관계를 모델링하기에 적합
- ex) collaboration, friendship on Facebook, interaction between proteins...
- Directed: 모든 link가 방향을 가지고 있거나 source 혹은 destination이 있을 때, 화살표로 나타내기에 적합
- ex) phone calls, financial transactions, following on Twitter
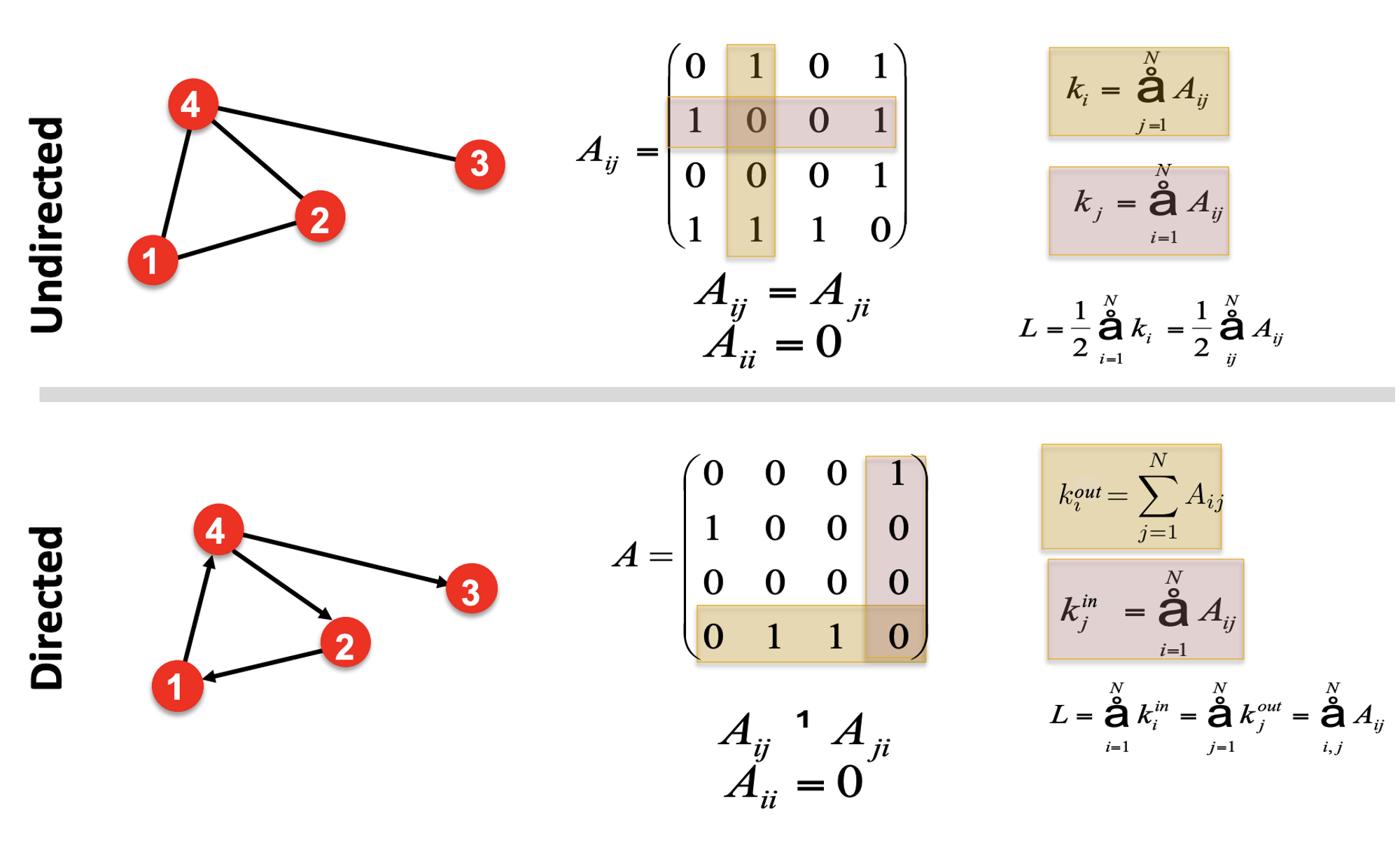
Undirected, Directed graph에서 서로 다르게 정의되는 용어들을 살펴보자. Node degree와 Average node degree는 Undirected graph에서, in-degree와 out-degree는 Directed graph에서 정의되는 용어이다.
- Node degree: 어떤 노드 i와 인접한 edge의 개수. 아래의 그림에서 노드 A의 node degree는, 인접한 노드가 4개이므로 4가 된다.
- Average Node degree: 해당 네트워크의 모든 노드에 대한 degree를 평균한 것, 계산식은 아래와 같다.
- 아래 계산식을 정리하면 결과적으로 edge의 개수의 두 배를 node의 개수로 나눈 값이 된다. 분자가 edge 개수의 두 배가 되는 이유는, 우리가 node degree를 계산할 때, edge는 서로 다른 node를 연결해주기 때문에 모든 node에 대해서 degree를 구하면 edge는 두 번씩 카운트되기 때문이다.
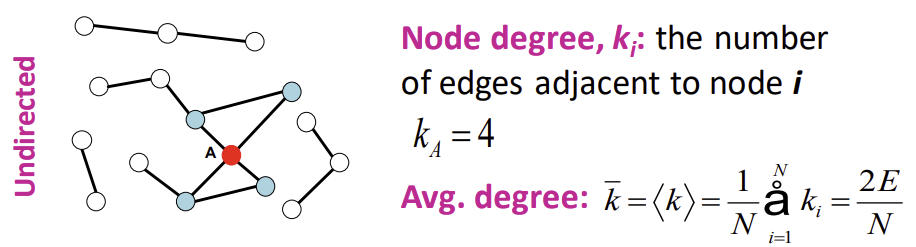
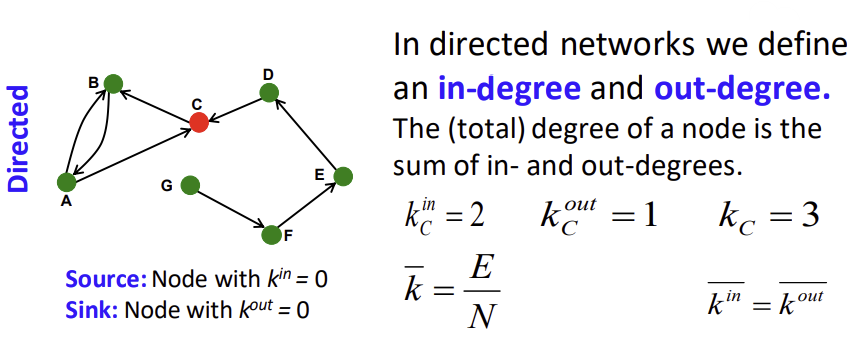
- in-degree: 어떤 노드를 향하고 있는 edge의 개수
- out-degree: 어떤 노드로부터 시작된, 밖을 향하고 있는 edge의 개수
일례로, 아래 그림의 예시에서 node C를 기준으로 봤을 때, in-degree는 node C를 향하고 있는 화살표의 개수를 세면 되므로 2, out-degree는 반대 방향으로 뻗어나가는 화살표의 개수를 세면 되므로 1이 된다.
2) Bipartite Graph
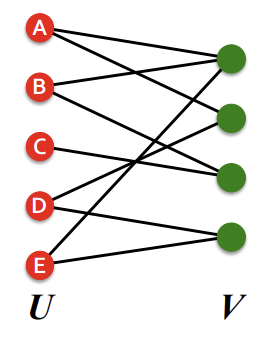
다양한 도메인을 자연스럽게 표현할 수 있어서 많이 사용되는 구조인 'Bipartite Graph'에 대해서 보자. 이는 두 개의 다른 타입의 node로 구성되며, node는 오직 다른 타입의 node하고만 상호작용한다. 따라서 edge는 서로 다른 두 partition을 연결하는 역할을 하지, 한 partition 내에서 연결하지는 않는다. bipartite graph의 예시는 아래와 같다.
- Authors-to-Papers(they authored)
- Actors-to-Movies(they appeared in)
- Users-to-Movies(they rated)
- Recipes-to-Ingredients(they contain)
- Customers-to-Products(they purchased)
우리는 또한 'folded' 혹은 'projected' network라는 용어에 대해 정의할 수 있다. folded/projected bipartite graph는 그 이름처럼, bipartite graph를 오른쪽 또는 왼쪽 중 한쪽으로 project 시켜서 만들 수 있다. 예를 들어, 아래의 그래프에서 U가 저자, V가 논문이라고 한다면, 그중에서도 논문 A에 연결된 저자 1, 2, 3은 해당 논문의 공저자라 할 수 있다. 만일 저자 쪽으로 projection을 시켜서 projection 저자 그래프를 만든다고 한다면, 공통된 논문의 공저자인 1, 2, 3은 서로 관계가 있다고 볼 수 있을 것이다. 반면, 저자 3, 4는 함께 작업한 논문이 아무것도 없으므로 관계가 없다고 할 수 있고, 실제로 projection 저자 그래프에서 edge로 연결되어 있지 않다.
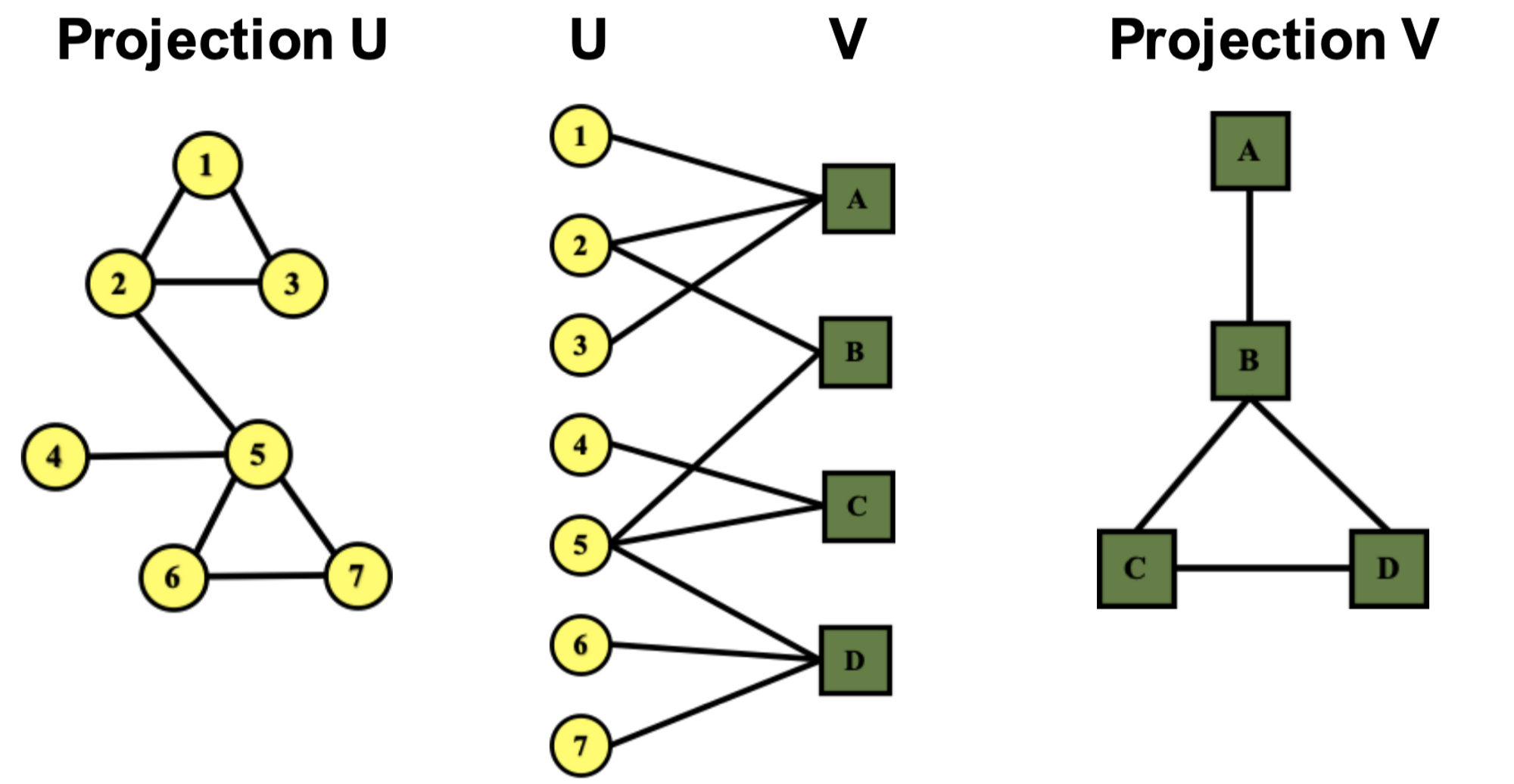
3. Representing Graphs
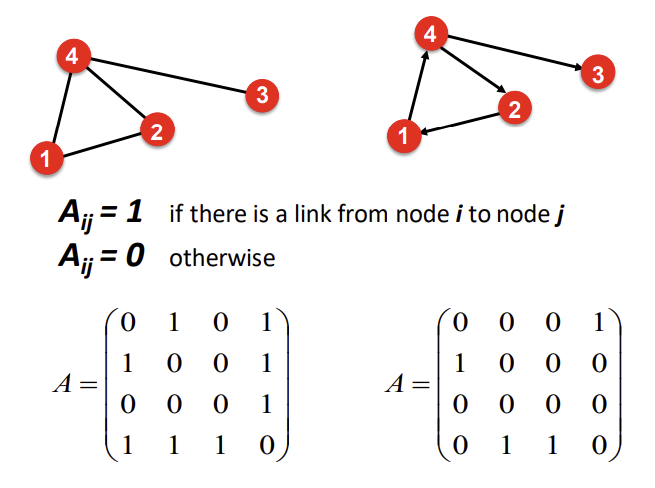
1) Adjacency Matrix
그래프를 표현하는 방법 중 하나는 adjacency matrix(인접 행렬: 각 노드 간의 연결 상태를 행렬과 같은 형태로 표현)를 이용하는 것이다. node의 개수가 n일 때, n*n 행렬 A를 만든다. 이 행렬은 binary로, 0 또는 1의 entity를 가지게 된다.
- Undirected graph: i번째 node와 j번째 node가 서로 연결되어 있다면 행렬 A의 (i, j) 위치에 1을, 연결되어 있지 않다면 0을 넣는다. 그래서 Undirected graph의 adjacency matrix는 symmetric할 수밖에 없다(대칭적이라는 의미).
- Directed graph: i번째 node에서 j번째 node로 edge가 뻗어나가고 있다면 행렬 A의 (i, j) 위치에 1을, 그렇지 않다면 0을 넣는다. 아래 그래프의 예시에서, node 2에서 1로 화살표가 향하고 있으므로 행렬 A의 (2, 1) 위치에 1이 채워졌다. 그러나 그 역으로는 화살표가 향하지 않으므로 그와 대칭되는 위치에 있는 (1, 2)에는 0이 들어간다. Directed graph는 symmetric하지 않을 수 있다.
adjacency matrix를 이용하면, node degree를 구할 때 어떤 node와 인접한 edge가 몇 개나 있는지 직접 셀 필요 없이, 행과 열의 합으로서 그 값을 구할 수 있다는 장점도 있다. 이처럼 adjacency matrix는 연산을 편하게 만들어준다는 장점이 있지만, 단점도 존재한다. 바로 극도로 sparse하다는 점이다. 전 세계 사람들 사이의 social network를 그린다고 생각해보자. 80억 개가 넘는 node가 존재할테지만, 80억 명의 친구를 가진 사람은 그 누구도 없을 것이다. 따라서 실제로 연결된 node는 극히 일부일 것이고, 그렇기 때문에 adjacency matrix는 극도로 sparse해질 수밖에 없다.
2) Edge list
그래프를 표현하는 또 다른 방법 중 하나는 바로 그래프를 edges의 목록으로 나타내는 것이다. 이러한 representation은 딥러닝 프레임워크에서 꽤나 자주 쓰이는 방법인데, 그래프를 2D matrix로 간단하게 나타낼 수 있도록 해주기 때문이다. 다만 이 방식은 graph manipulation이나 분석을 하기 어렵다는 단점도 있다. node degree를 계산하는 것이 non-trivial(자명하지 않다고 해석해야 할 듯)하기 때문이다.
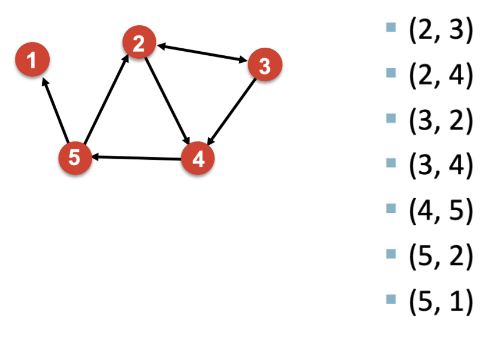
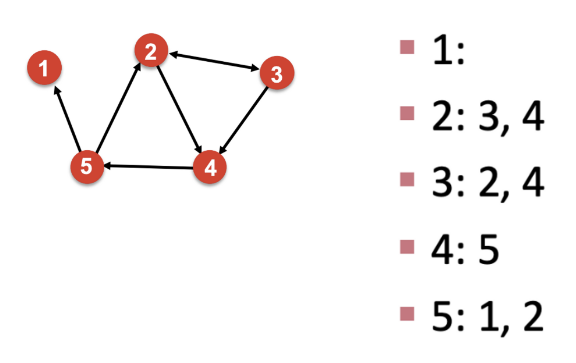
3) Adjacency list
graph analysis, manipulation 측면에서는 위의 edge list 방식보다 더 나은 방법이라 할 수 있다. 각 node의 이웃을 목록 형식으로 표현하는 방식으로서, 크고 sparse한 네트워크에 적용하기 좋다. 또한 이 방식은 주어진 node의 모든 이웃들을 빠르게 retrieve할 수 있도록 해준다.
4. Node and Edge Attributes
우리는 그래프에 추가적인 특성을 attach할 수도 있다. 아래는 가능한 option의 종류이다.
- Weight(edgd에 가중치 부여): ex. frequency of communication
- Ranking: ex. best friend, second best friend...
- Type: ex. friend, relative, co-worker
- Sign: Friend vs. Foe, Trust vs.Distrust
그래프를 구성하는 각 개체는 속성을 가질 수 있다. 사람 사이의 관계를 예로 들자면, node(즉, 사람)는 성별, 관심사, 위치 등의 속성을 가질 수 있고, edge(그들 사이의 link)는 호의적인지, 친한지 등의 속성을 가질 수 있다. 그래프를 이용해서 화학 분자를 나타낸다면, node 하나하나는 각각의 화학적인 특성을 가지게 될 것이다. 뿐만 아니라 전체 그래프 그 자체도 속성을 가질 수 있는데, 이는 해당 그래프를 구성하는 객체들의 속성에 기반한다. 따라서, Graph Neural Network를 모델링할 때 우리는 단순히 그래프의 topology뿐만 아니라, 그것을 구성하는 객체 각각이 가지는 속성까지 고려하여야 한다.
5. More Types of Graphs
그래프의 속성을 representation 자체에 녹여낼 수도 있다.
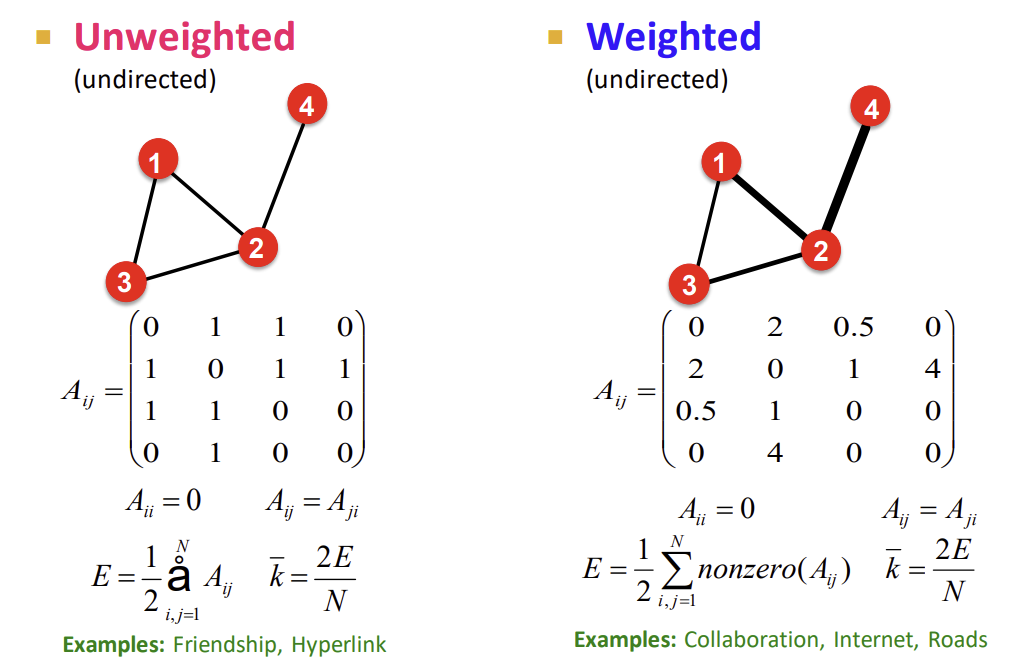
1) Unweighted vs. Weighted
우선, edge에 가중치가 가해지는 경우, adjacency matrix를 0과 1의 entity로 구성된 binary matrix로 만드는 대신, 연결 강도에 따라 entity의 크기를 달리함으로써 표현할 수 있다.
2) Self-edges(Self-loops), Multigraph
self-edges(self-loops)를 가지는 경우에는, adjacency matrix의 diagonal 부분이 채워지므로 이를 통해 표현할 수 있다. 같은 두 개의 node 사이에 여러 개의 edge가 있는 경우, 그만큼 연결이 강하다는 의미이므로 가중치를 부여했듯이 edge의 개수에 따라 entity를 증가시키며 표현할 수 있다. 그러나 만일 Multigraph의 같은 두 개의 node를 이어주는 edge 사이의 속성이 다르다면, adjacency matrix를 이용해 퉁쳐서 표현하기보다는 각각의 edge를 살려서 표현해주어야 할 수도 있다. 그렇기는 하지만, 일상 생활 중에 Multigraph를 사용해야 할 상황이 꽤 되기 때문에(ex. phone calls: 같은 사람들끼리 여러 번 전화할 수 있음), Multigraph는 그런 상황을 표현하는 데 매우 유용하게 사용될 수 있다.
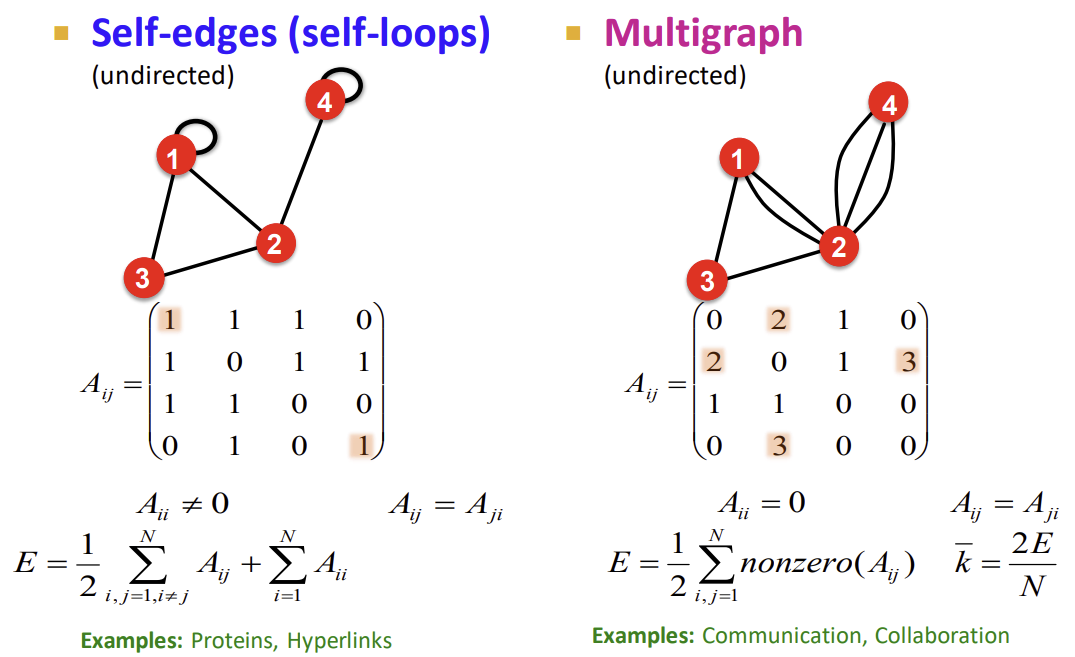
- Weighted graph: 가중치에 따라 matrix entity의 크기 변화시킴
- Self-edges graph: diagonal이 채워짐
- Multigraph: node 사이의 edge 개수에 따라 matrix entity의 크기 변화시킴
3) Connectivity of Undirected Graphs
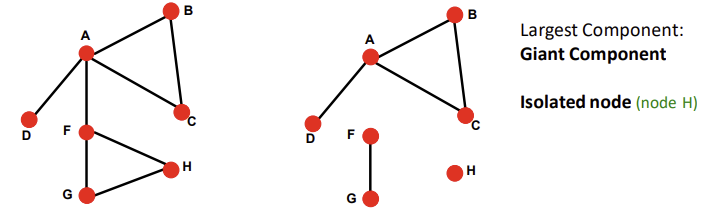
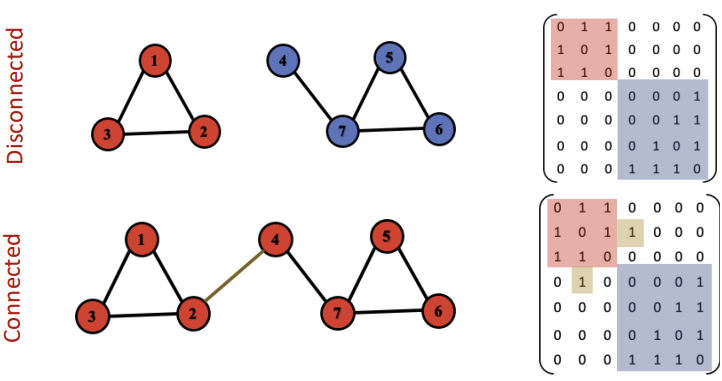
Undirected Graph에서 그래프가 connected되어 있다는 말은, 어떤 두 개의 node도 적어도 하나의 edge로 서로 연결되어 있다는 것을 의미한다. 흥미로운 점은, undirected disconnected graph를 adjacency matrix로 나타내면 block diagonal structure를 갖게 된다는 것이다.
4) Connectivity of Directed Graphs
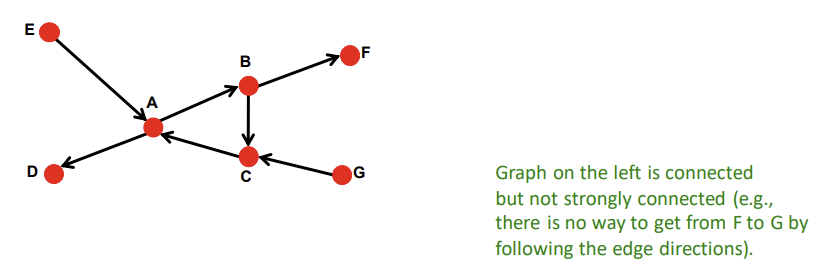
- Strongly connected directed graph: 어떤 노드에서 출발하든 edge 방향을 따라서 다른 모든 노드에 도달할 수 있는 그래프
- Weakly connected directed graph: edge 방향을 무시한다면 다른 모든 노드와 연결된 그래프
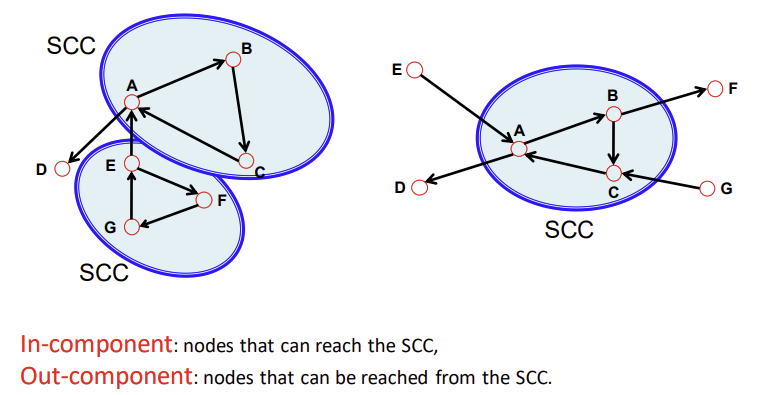
- Strongly connected components: edge 방향을 따라서 연결될 수 있는 노드들의 집합, 일종의 cycle을 형성한다.
'놀라운 Deep Learning > Machine Learning with Graphs' 카테고리의 다른 글
| [CS224W] 2-3. Traditional Feature-based Methods: Graph (0) | 2023.09.04 |
|---|---|
| [CS224W] 2-2. Traditional Feature-based Methods: Link (0) | 2023.09.04 |
| [CS224W] 2-1. Traditional Feature-based Methods: Node (0) | 2023.09.03 |
| [CS224W] 1-2. Applications of Graph ML (0) | 2023.08.27 |
| [CS224W] 1-1. Why Graphs (1) | 2023.08.27 |



